







蘑菇街爬虫前的准备工作
目录
01-蘑菇街爬虫准备工作1
02-蘑菇街爬虫mw-sign参数破解
03-蘑菇街爬虫概述
04-蘑菇街爬虫:店铺搜索页面
建议大家跟着我的教程一步一步走下去
网站分析
1. 店铺搜索相关分析
店铺搜索
(1)打开店铺搜索页面。
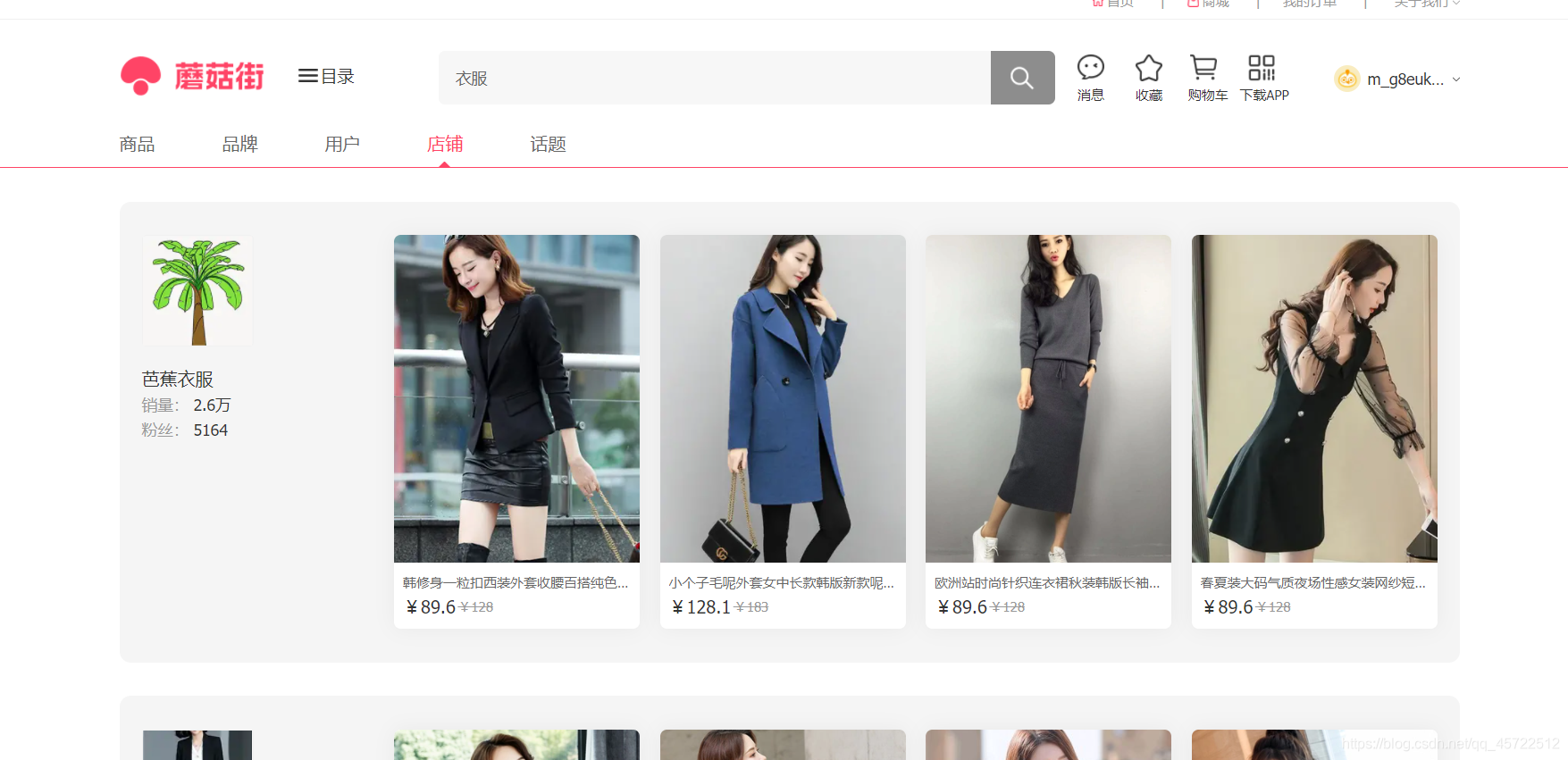
(2)按f12,打开chrome抓包工具,并且刷新页面,最后搜索芭蕉衣服。
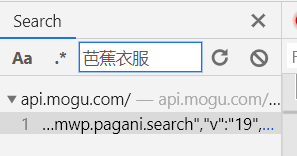
(3)分析搜索结果的url组成。经过我的url解码后得到:
https://api.mogu.com/h5/mwp.pagani.search/19/?data={"cKey":"pc-search-result-shop","q":"衣服","page":1}&mw-appkey=100028&mw-ttid=NMMain@mgj_pc_1.0&mw-t=1617857400633&mw-uuid=10b321d1-3ddb-4298-a453-acbf17732d41&mw-h5-os=unknown&mw-sign=6668677d4480c04443425f4b1f6b7535&callback=mwpCb2&_=1617857400634
我测试后得到当前url中变化部分:
| 变量名 | 解释 |
|---|---|
| data | 一个包含我们搜索的关键词以及页码的字典,{“cKey”:“pc-search-result-shop”,“q”:“衣服”,“page”:1} |
| mw-t | 表示请求时间,1617857400633 |
| mw-sign | 这是一个加密数据,每次都会变化,需要我们破解加密过程,6668677d4480c04443425f4b1f6b7535 |
mw-sign后面的键值对都可以删除掉不影响我们获取数据。
(4)分析测试代码,大家可以拿去自己测试哪些变量需要我们模拟。
我使用的jupyter notebook运行的代码
import requests
import json
def Request(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36',
'cookie': '把自己的cookie粘在这',
'referer': 'https://list.mogu.com/',
}
response = requests.get(url,headers=headers).text
return response
url = "https://api.mogu.com/h5/mwp.pagani.search/19/?data=%7B%22cKey%22%3A%22pc-search-result-shop%22%2C%22q%22%3A%22%E8%A1%A3%E6%9C%8D%22%2C%22page%22%3A1%7D&mw-appkey=100028&mw-ttid=NMMain%40mgj_pc_1.0&mw-t=1617857400633&mw-uuid=10b321d1-3ddb-4298-a453-acbf17732d41&mw-h5-os=unknown&mw-sign=6668677d4480c04443425f4b1f6b7535"
url不能使用解码后的url,不然请求不到数据。
Request(url)
mw-sign破解教程在后面发布。
2. 产品搜索页面分析
(1)打开产品搜索页面。
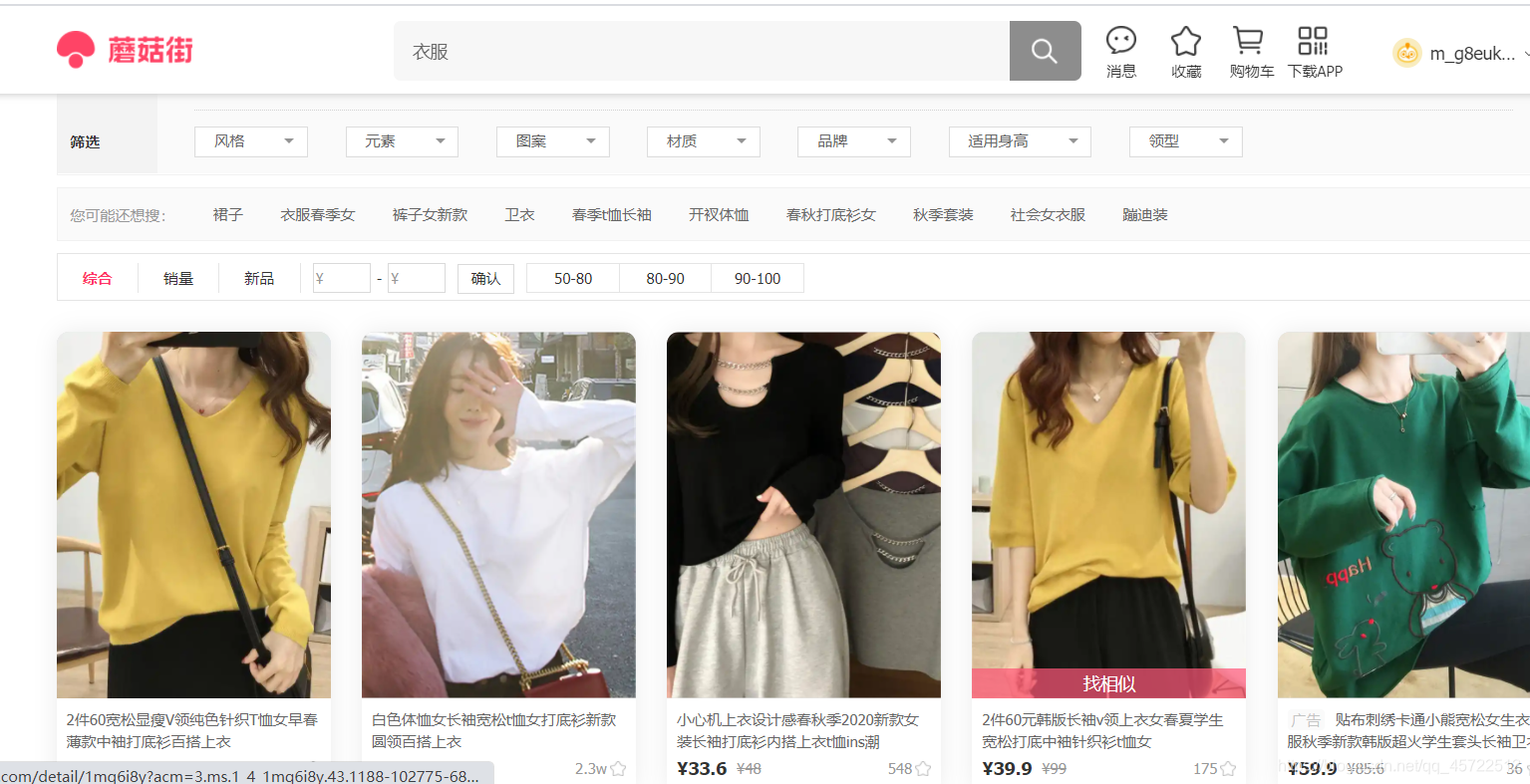
(2)按f12,打开chrome抓包工具,并且刷新页面,最后搜索39.9。
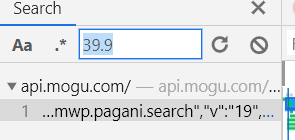
(3)分析搜索结果的url组成。经过我的url解码后得到:
https://api.mogu.com/h5/mwp.pagani.search/19/?data={"page":1,"pageSize":24,"sort":"pop","ratio":"3:4","cKey":"pc-search-wall","q":"衣服","ptp":"31.TOjDTb.0.0.9eJGifSJ","f":"mgjlm"}&mw-ckey=pc-search-wall&mw-appkey=100028&mw-ttid=NMMain@mgj_pc_1.0&mw-t=1617859017302&mw-uuid=10b321d1-3ddb-4298-a453-acbf17732d41&mw-h5-os=unknown&mw-sign=6e6e64a003746cc1e5cdc6553b54ccb9&callback=mwpCb2&_=1617859017303
我测试后得到当前url中变化部分:
| 变量名 | 解释 |
|---|---|
| data | 一个包含我们搜索的关键词以及页码的字典,{“page”:1,“pageSize”:24,“sort”:“pop”,“ratio”:“3:4”,“cKey”:“pc-search-wall”,“q”:“衣服”,“ptp”:“31.TOjDTb.0.0.9eJGifSJ”,“f”:“mgjlm”} |
| mw-t | 表示请求时间,1617859017302 |
| mw-sign | 这是一个加密数据,每次都会变化,需要我们破解加密过程,6e6e64a003746cc1e5cdc6553b54ccb9 |
mw-sign后面的键值对都可以删除掉不影响我们获取数据。
(4)分析测试代码,大家可以拿去自己测试哪些变量需要我们模拟。
我使用的jupyter notebook运行的代码
import requests
import json
def Request(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36',
'cookie': '把自己的cookie粘在这',
'referer': 'https://list.mogu.com/',
}
response = requests.get(url,headers=headers).text
return response
url1 = 'https://api.mogu.com/h5/mwp.pagani.search/19/?data=%7B%22page%22%3A1%2C%22pageSize%22%3A24%2C%22sort%22%3A%22pop%22%2C%22ratio%22%3A%223%3A4%22%2C%22cKey%22%3A%22pc-search-wall%22%2C%22q%22%3A%22%25E8%25A1%25A3%25E6%259C%258D%22%2C%22ptp%22%3A%2231.TOjDTb.0.0.9eJGifSJ%22%2C%22f%22%3A%22mgjlm%22%7D&mw-ckey=pc-search-wall&mw-appkey=100028&mw-ttid=NMMain%40mgj_pc_1.0&mw-t=1617859017302&mw-uuid=10b321d1-3ddb-4298-a453-acbf17732d41&mw-h5-os=unknown&mw-sign=6e6e64a003746cc1e5cdc6553b54ccb9&callback=mwpCb2&_=1617859017303'
url不能使用解码后的url,不然请求不到数据。
Request(url1)
mw-sign破解教程在后面发布。
3.其他页面分析
其他页面分析流程如同上面两个步骤一样,问题的核心是破解mw-sign。

















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









