







【第1周】深度学习基础
一、第一部分 代码练习
1. pytorch基础练习
1.1定义数据
Tensor(张量)可以被视为多维数组,它是PyTorch中最基本的数据结构。
张量可以存储和处理各种形式的数字数据,包括整数、浮点数等。它们可以具有不同的维度,比如标量(0维张量)、向量(1维张量)、矩阵(2维张量)以及更高维度的张量。
示例1.1.1
z = torch.randn_like(x, dtype=torch.float)
print(z)
代码z = torch.randn_like(x, dtype=torch.float)的作用是创建一个与张量x具有相同大小(形状)的新张量z,但数据类型(dtype)为torch.float。
torch.randn_like()函数会生成一个符合标准正态分布(均值为0,方差为1)的张量,并使用与输入张量相同的大小。通过指定dtype=torch.float,可以将生成的张量的数据类型设置为浮点型。
1.2定义操作
Tensor(张量)可以执行各种基本运算。
-
基本运算:加法(add)、减法(sub)、乘法(mul)、除法(div)、求幂(pow)、取余(fmod)等。此外,还可以进行绝对值(abs)、平方根(sqrt)、指数函数(exp)和三角函数(cos、sin、asin、atan2、cosh)等操作。还有取整函数(ceil、round、floor、trunc)等,在具体使用时可以查询相关文档或搜索引擎获取更多信息。
-
布尔运算:张量也支持布尔运算,例如大于(gt)、小于(lt)、大于等于(ge)、小于等于(le)、等于(eq)、不等于(ne)等比较操作。此外,还可以使用topk、sort、max和min等函数进行排序和获取最值。
-
线性计算:张量可以执行各种线性计算操作。例如,矩阵乘法(mm)、批量矩阵乘法(bmm)、转置(t)、点积(dot)、叉积(cross)、求逆(inverse)、奇异值分解(svd)等。还可以进行迹运算(trace)、对角线提取(diag)等。
示例1.2.1
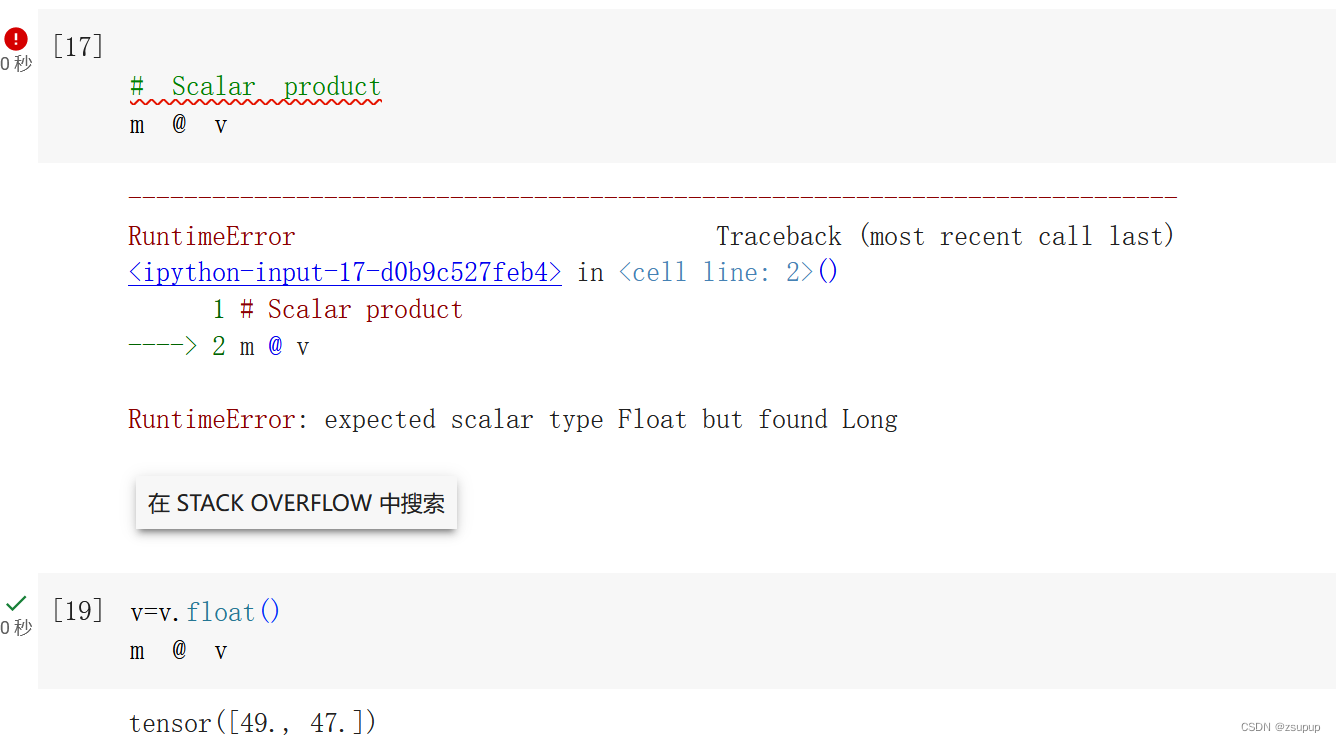 这个错误提示表明在进行矩阵乘法运算时,预期的数据类型是浮点型(Float),但实际上发现了长整型(Long)的数据类型。要解决这个问题,可以将输入的矩阵和向量转换为相同的数据类型,确保它们具有匹配的数据类型。
这个错误提示表明在进行矩阵乘法运算时,预期的数据类型是浮点型(Float),但实际上发现了长整型(Long)的数据类型。要解决这个问题,可以将输入的矩阵和向量转换为相同的数据类型,确保它们具有匹配的数据类型。
示例1.2.2
from matplotlib import pyplot as plt
## matlabplotlib 只能显示numpy类型的数据,下面展示了转换数据类型
#通过torch.randn(1000)生成了一个包含1000个服从均值为0、方差为1的正态分布随机数的张量。
#使用.numpy()将该张量转换为NumPy数组
plt.hist(torch.randn(1000).numpy(), 100);
2.螺旋数据分类
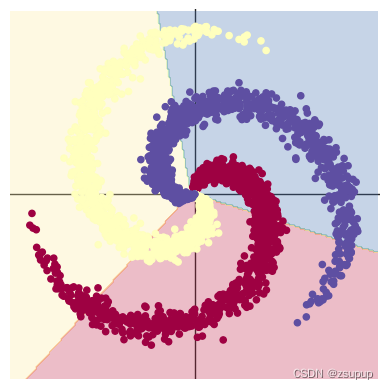
螺旋数据分类是指对一类特殊的二维数据进行分类任务。螺旋数据通常由两个或多个连续的螺旋形状组成,每个螺旋代表一个不同的类别。
2.1 构建线性模型分类
2.2 构建两层神经网络分类
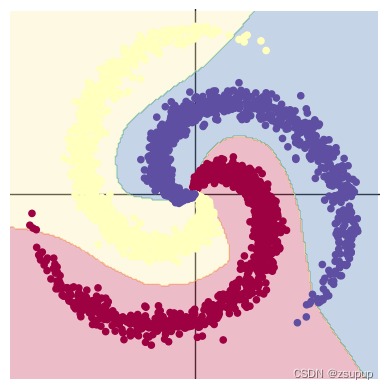
总结:对于螺旋数据分类问题,选择哪种方法取决于数据分布和问题的复杂度。如果数据分布非常复杂且线性模型无法解决,则两层神经网络可能更适合。但如果数据分布相对简单,并且可以通过线性分割,则线性模型也可以给出合理的结果。
二、问题总结
1.AlexNet有哪些特点?为什么可以比LeNet取得更好的性能?
1.1 AlexNet⽐相对较小的LeNet要深得多。
AlexNet由⼋层组成:五个卷积层、两个全连接隐藏层和⼀个全连接输出层。AlexNet的结构与LeNet相似,但使⽤了更多的卷积层和更多的参数来拟合⼤规模的ImageNet数据集 。

1.2 AlexNet使⽤ReLU而不是sigmoid作为其激活函数。
AlexNet将sigmoid激活函数改为更简单的ReLU(Rectified linear unit,ReLU)激活函数 。
-
一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。
-
另一方面,当使⽤不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。当sigmoid激活函数的输出⾮常接近于0或1时,这些区域的梯度⼏乎为0,因此反向 传播无法继续更新⼀些模型参数。相反,ReLU激活函数在正区间的梯度总是1。因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
1.3 容量控制和预处理
AlexNet通过dropout控制全连接层的模型复杂度,而LeNet只使⽤了权重衰减。为了进⼀步扩充数据,AlexNet在训练时增加了⼤量的图像增强数据,如翻转、裁切和变⾊。这使得模型更健壮,更⼤的样本量有效地减少了过拟合。
2.激活函数有哪些作用?
激活函数通过计算加权和并加上偏置来确定神经元是否应该被激活。它们是将输⼊信号转换为输出的可微运算。⼤多数激活函数都是非线性的。
3.梯度消失现象是什么?
目前优化神经网络的方法都是基于反向传播的思想,在回答题目的问题之前,我们需要先了解一下反向传播 (Back Propagation)。 反向传播本质上指的是计算神经⽹络每一层参数梯度的⽅法,利用链式法则逐层求出损失函数对各个神经元权重和偏置的偏导数,构成损失函数对权值和偏置向量的梯度,指导深度网络权值的更新优化。 可以参考这是视频BV16x411V7Qg
3.1 梯度消失
梯度消失是指当梯度传递到深层时,由于参数的初始值或激活函数的形式,梯度变得非常小,从而导致训练难以收敛。这种情况通常发生在使用 sigmoid 或 tanh 作为激活函数的情况下,因为这两个函数在输入较大时,梯度会变得非常小。
代码:
import torch
import matplotlib.pyplot as plt
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.sigmoid(x)
y.backward(torch.ones_like(x))
plt.plot(x.detach().numpy(), y.detach().numpy(), label = 'sigmoid')
plt.plot(x.detach().numpy(), x.grad.numpy() ,linestyle=':', label = 'gradient')
plt.legend()
plt.show()
结果:
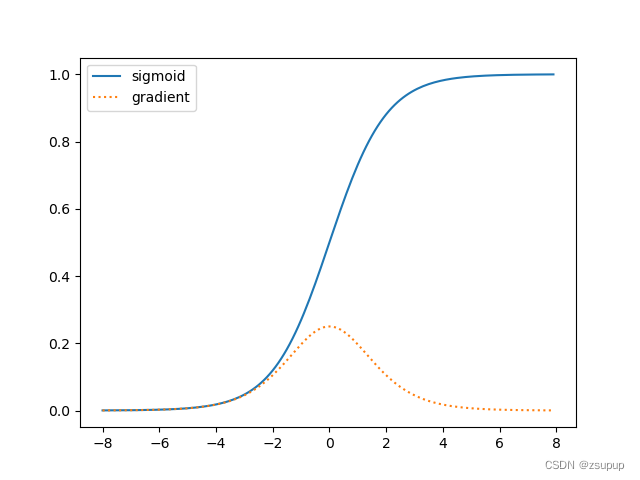
可以看出,当sigmoid函数的输入很大或是很小时,它的梯度都是一个远远小于1的数,非常趋近于0。当反向传播通过许多层时,除非每一层的sigmoid函数的输入都恰好接近于零,否则整个乘积的梯度可能会消失。 当我们的网络有很多层时,除非我们很小心,否则在某一层可能就会切断梯度。 因此,现在大家更愿意选择更稳定的ReLU系列函数作为激活函数。
3.2 梯度爆炸
与之相反的则是梯度爆炸问题。梯度爆炸是指当梯度传递到深层时,由于参数的初始值或激活函数的形式,梯度变得非常大,从而导致训练难以收敛。为了更直观的看到这个问题,可以用代码生成了100个高斯随机矩阵,并将这些矩阵与一个矩阵相乘,这个矩阵相当于模型的初始参数矩阵。设置方差为1,看一下运行结果。
代码:
M = torch.normal(0, 1, size=(4,4))
print('⼀个矩阵 \n',M)
for i in range(100):
M = torch.mm(M,torch.normal(0, 1, size=(4, 4)))
print('乘以100个矩阵后\n', M)
结果:

4.神经网络是更宽好还是更深好?
- 深度——神经网络的层数
- 宽度——每层的通道数
- 更深的网络具有更好的非线性表达能力,可以学习更复杂的变换,从而拟合更加复杂的特征。然而,随着网络的加深,会面临梯度不稳定和网络退化的问题,过深的网络可能导致浅层学习能力下降。因此,在将网络加深时需要注意调整参数,避免出现性能下降的情况。
- 足够的宽度可以确保每一层都学习到丰富的特征,例如不同方向和频率的纹理特征。如果宽度太窄,网络无法充分提取特征,学习到的信息会受限,从而限制了模型的性能。但宽度也会带来额外的计算负担,因为太宽的网络可能会提取重复的特征,增加了计算开销。
5.为什么要使用Softmax?
softmax函数,又称为归一化指数函数。它是将二分类函数sigmoid推广到多分类问题中的一种方法,其目的是以概率的形式展示多类别的结果。
待补充...
6.SGD 和 Adam 哪个更有效?
SGD(随机梯度下降)和Adam(自适应矩估计)都是常用的优化算法,用于训练神经网络和更新模型参数。它们各有特点,效果的相对优劣依赖于具体问题和数据集的性质。
6.1 SGD
随机梯度下降法 (SGD,Stochastic Gradient Descent) 的基本思想是每次选代中仅使用一个样本来计算梯度,然后根据梯度来调整参数的值。
优点:
- 首先,随机梯度下降法每次迭代中仅使用一个样本计算梯度,这使得计算速度快很多。(梯度下降法每次迭代中都需要使用所有的样本计算梯度,这使得计算速度要慢很多。)
- 其次,随机梯度下降法每次迭代中仅使用一个样本计算梯度,这使得它比梯度下降法更加稳定。
缺点:
- 首先,由于每次迭代中只使用一个样本计算梯度,因此每次迭代的梯度都是有噪声的。这会导致每次迭代的收敛速度变化很大,并且在目标函数有多个局部最小值时可能会被卡在局部最小值中。但是,因为总的迭代次数很多,所以随机梯度下降法最终会收敛到最优解。
- 其次,由于每次迭代中只使用一个样本计算梯度,因此每次迭代的计算代价都很低。但是,如果训练集很大,那么总的计算代价就会变得很高,因为我们需要计算很多次梯度。
- 最后,随机梯度下降法在每次迭代中都只使用一个样本,因此我们不能利用批量计算的优势来加速计算。
6.2 Adam
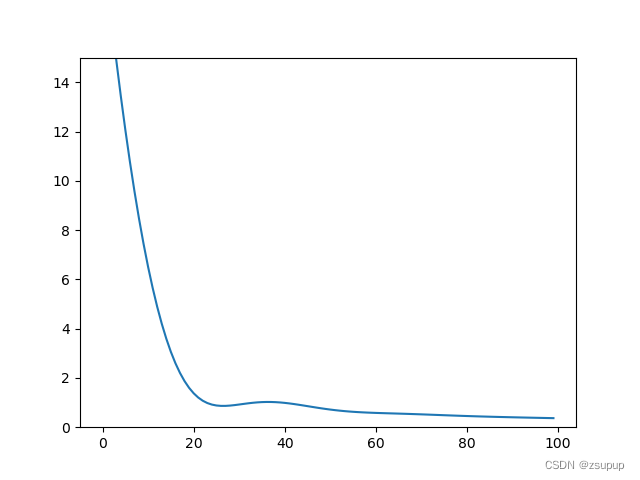
Adam算法是在RMSProp算法的基础上提出的,并且使用了指数加权平均数来调整学习率。Adam算法被广泛用于神经网络的训练过程中,因为它能够自适应学习率,使得训练过程更加顺畅。
代码示例:
import matplotlib.pyplot as plt
import numpy as np
import torch
# 首先,我们定义一个随机训练数据
np.random.seed(0)
x = np.random.uniform(0, 2, 100)
y = x * 3 + 1 + np.random.normal(0, 0.5, 100)
# 将训练数据转换为 PyTorch Tensor
x = torch.from_numpy(x).float().view(-1, 1)
y = torch.from_numpy(y).float().view(-1, 1)
# 然后,我们定义一个线性模型和损失函数
model = torch.nn.Linear(1, 1)
loss_fn = torch.nn.MSELoss()
# 接下来,我们使用 Adam 优化器来训练模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
# 初始化用于可视化训练过程的列表
losses = []
# 开始训练循环
for i in range(100):
# 进行前向传递,计算损失
y_pred = model(x)
loss = loss_fn(y_pred, y)
# 将损失存储到列表中,以便我们可视化
losses.append(loss.item())
# 进行反向传递,更新参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 可视化训练过程
plt.plot(losses)
plt.ylim((0, 15))
plt.show()
运行结果:
最近提前入校,到学校之后再更新其他内容!














 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









