







卷积神经网络
一、代码练习
1.卷积神经网络
1.1加载数据 (MNIST)

1.2 创建网络

其中,
nn.Linear(input_size, n_hidden):创建一个线性层,将输入数据的维度从input_size变换到n_hidden。
nn.ReLU():应用ReLU激活函数,它将负值变为零,保持正值不变。
nn.Linear(n_hidden, n_hidden):创建另一个线性层,将隐藏层的维度从n_hidden变换到n_hidden。
nn.Linear(n_hidden, output_size):创建最后一个线性层,将隐藏层的维度从n_hidden变换到output_size,即模型的输出维度。
nn.LogSoftmax(dim=1):对输出进行LogSoftmax操作,通过指定dim=1,在第一个维度上进行LogSoftmax计算,表示对每个样本进行处理。
总体而言,这段代码定义了一个具有两个隐藏层的前馈神经网络模型,其中包括线性层和ReLU激活函数,并使用LogSoftmax对输出进行标准化,以便在分类问题中获得概率分布。
1.3 在小型全连接网络上训练(Fully-connected network)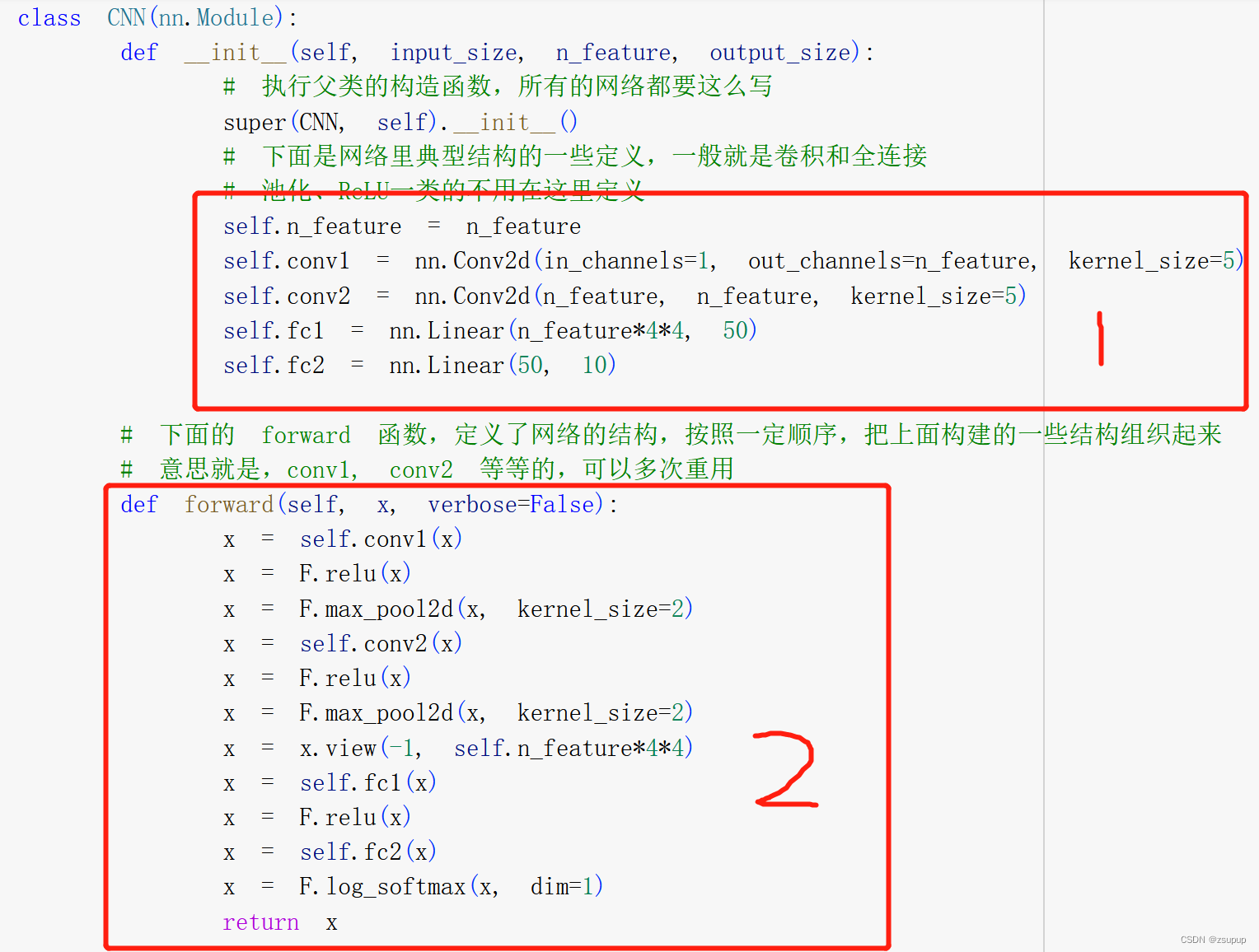
1部分中,使用了 PyTorch 的 nn 模块来定义神经网络的各个层。Conv2d 是卷积层,Linear 是全连接层。通过组合这些层,可以构建一个深度神经网络模型,用于图像分类任务。
#定义了第一层卷积层。输入通道数为 1(假设输入是单通道灰度图像),输出通道数为 n_feature,卷积核大小为 5x5。
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
2部分中,是一个神经网络模型的前向传播函数。它接受一个输入张量 x,然后通过一系列的卷积、池化和全连接层操作,最后返回一个经过 softmax 激活函数处理后的输出张量。
self.conv1(x) #对输入进行第一次卷积操作。
F.relu(x) #对卷积结果应用 ReLU 激活函数。
F.max_pool2d(x, kernel_size=2) #使用 2x2 的窗口进行最大池化操作。
1.4 训练结果
小型全连接网络上训练结果:
 卷积神经网络上训练结果:
卷积神经网络上训练结果:
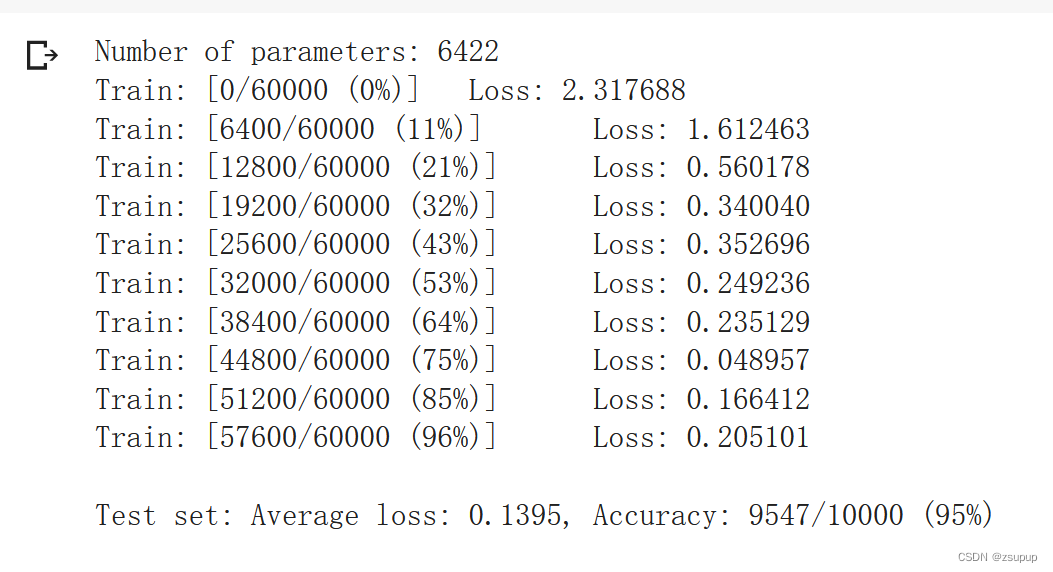
 通过上面的测试结果,可以发现,含有相同参数的 CNN 效果要明显优于 简单的全连接网络,是因为 CNN 能够更好的挖掘图像中的信息,主要通过两个手段:
通过上面的测试结果,可以发现,含有相同参数的 CNN 效果要明显优于 简单的全连接网络,是因为 CNN 能够更好的挖掘图像中的信息,主要通过两个手段:
卷积:Locality and stationarity in images
池化:Builds in some translation invariance
1.5 打乱像素顺序再次在两个网络上训练与测试
小型全连接网络:
Test set: Average loss: 0.3887, Accuracy: 8854/10000 (89%)
卷积神经网络:
Test set: Average loss: 0.5300, Accuracy: 8344/10000 (83%)
从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化,但是 卷积神经网络的性能明显下降。
这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
2 使用 CNN 对 CIFAR10 数据集进行分类
2.1 加载数据集
 用于加载和预处理 CIFAR-10 数据集的代码,使用了不同的数据处理方法。 transform 使用了以下两个操作:
用于加载和预处理 CIFAR-10 数据集的代码,使用了不同的数据处理方法。 transform 使用了以下两个操作:
transforms.ToTensor():将图像转换为张量(Tensor)格式。这样可以方便地在PyTorch中进行处理。
transforms.Normalize():对图像进行标准化处理。它会减去均值 (0.5, 0.5, 0.5) 并除以标准差 (0.5, 0.5, 0.5)。这样做可以将图像的像素值范围限制在 -1 到 1 之间。
通过这些转换,训练集 trainset 和测试集 testset 中的图像数据都被转换成了张量,并进行了标准化处理。在训练集上,使用了 shuffle=True 的设置,表示每个 epoch(迭代周期)中的训练样本顺序会被随机打乱,以增加多样性。而在测试集上,使用了 shuffle=False,表示测试集中的样本顺序保持原有的顺序即可。
其中,
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) 的作用是将输入的图像数据进行归一化处理。它对每个颜色通道进行了减去均值并除以标准差的操作,以使数据分布接近于零均值和单位方差。
具体地说,(0.5, 0.5, 0.5) 是用来指定每个颜色通道的均值,而 (0.5, 0.5, 0.5) 则是用来指定每个颜色通道的标准差。这些值是经验性地选择,通常用于将图像的像素值范围从 [0, 1] 归一化到 [-1, 1]。
2.2 定义网络,损失函数和优化器
 定义了一个具有两个卷积层和三个全连接层的简单卷积神经网络模型。
定义了一个具有两个卷积层和三个全连接层的简单卷积神经网络模型。
2.3 训练网络

2.4 测试
 我们把图片输入模型,看看CNN把这些图片识别成什么:
我们把图片输入模型,看看CNN把这些图片识别成什么:
cat、ship、ship、plane、deer、frog、car、deer。
Accuracy of the network on the 10000 test images: 62 %
3 使用 VGG16 对 CIFAR10 分类
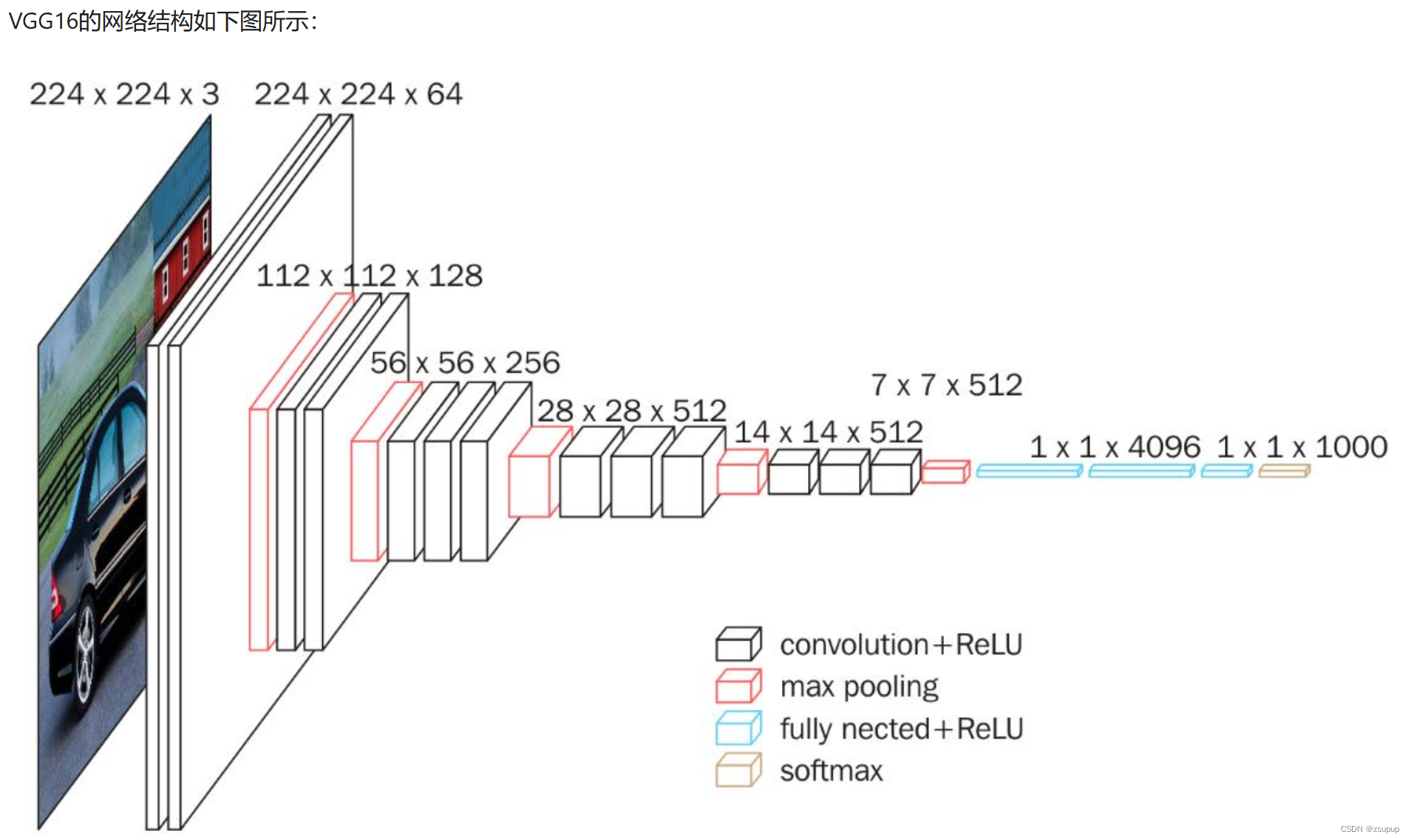
3.1 加载数据

VGG代码中的 transform_train 和 transform_test 使用了更多的数据增强操作,其具体操作如下:
对于训练集的转换 transform_train:
transforms.RandomCrop(32, padding=4):随机裁剪图像为 32x32 大小,并进行填充。这种随机裁剪操作有助于提取图像中的局部特征,同时引入一定的平移和缩放不变性。
transforms.RandomHorizontalFlip():以 0.5 的概率对图像进行水平翻转。这样可以增加数据的多样性,提高模型的鲁棒性。
transforms.ToTensor():将图像转换为张量格式。
transforms.Normalize():对图像进行标准化处理,均值为 (0.4914, 0.4822, 0.4465),标准差为 (0.2023, 0.1994, 0.2010)。
对于测试集的转换 transform_test:
transforms.ToTensor():将图像转换为张量格式。
transforms.Normalize():对图像进行标准化处理,使用与训练集相同的均值和标准差。
通过这些转换,训练集 trainset 和测试集 testset 中的图像数据在训练集上会进行随机裁剪和翻转等增强操作,从而增加数据的多样性和模型的泛化能力。在训练过程中,使用了 batch_size=128 来指定每个批次的样本数,shuffle=True 表示每个 epoch 中的训练样本顺序会被随机打乱,以增加多样性。而在测试集上,使用了 shuffle=False,表示测试集中的样本顺序保持原有的顺序即可。
3.2 定义网络结构
 其中,
其中,
在__init__方法中,定义了模型的结构。self.cfg是一个列表,其中包含了每个卷积层和池化层的通道数或者’M’表示最大池化层。self.features是通过调用_make_layers方法生成的卷积层和池化层的序列。self.classifier是一个线性层,将输入特征映射到10个类别上。
forward方法定义了前向传播过程。输入数据x首先通过self.features进行卷积和池化操作,然后将输出展平成一维向量,并通过self.classifier进行线性映射,最后返回分类结果。
_make_layers方法根据cfg列表中的配置创建了一系列的卷积层和池化层。根据列表中的值,如果是’M’则添加一个最大池化层,否则添加一个卷积层、批归一化层和ReLU激活函数。列表中的值也代表了每个卷积层的输入通道数和输出通道数。方法最后返回一个包含所有层的序列。
初始化网络,
定义一个交叉熵损失函数(CrossEntropyLoss)。交叉熵损失函数通常用于多分类问题,它可以度量模型预测结果与真实标签之间的差异。
定义一个Adam优化器(Adam(optimizer)),用于更新网络模型的参数。Adam是一种常用的梯度下降优化算法,通过自适应地调整学习率来优化模型参数。
将网络模型的参数传递给优化器(optimizer),并设置学习率为0.001。这一步将告诉优化器需要更新哪些参数以及使用什么样的学习率进行参数更新。
3.3 网络训练
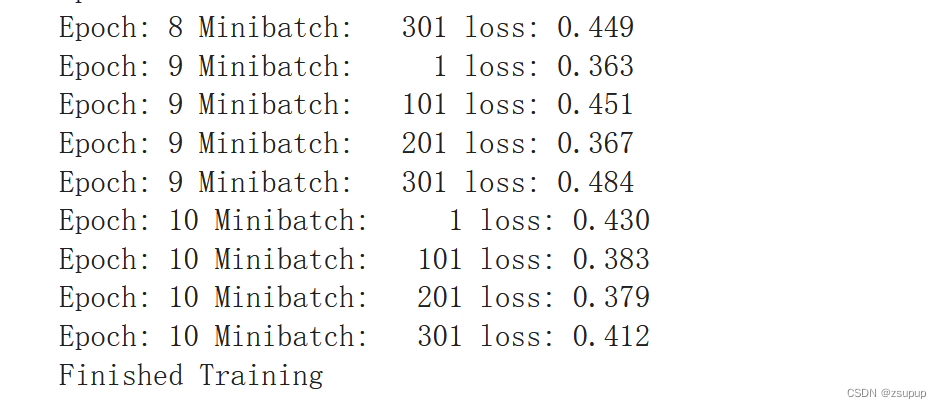
3.4 测试验证准确率
Accuracy of the network on the 10000 test images: 82.93 %
二、问题总结
1. dataloader 里面 shuffle 取不同值有什么区别?
shuffle (bool, optional):
set to ``True`` to have the data reshuffled at every epoch (default: ``False``).
shuffle是一个布尔类型的可选参数,默认值为False。当将其设置为True时它会在每个epoch(训练周期)开始时数据进行重新洗牌(reshuffle),即打乱数据的序。这样做可以增模型的泛化能力,避免模型过度依赖数据的顺。
通过将shuffle设置为True可以确保每个epoch中的样本顺序都是随机的从而使模型在不同的训练批次中看到各样本组合,有助于提高型的性能和鲁棒性。
需要注意的是,如果同时定了sampler参数,则不能将shuffle参数设置为True,因sampler参数已经定义样本抽取的策略。如下所示:
sampler (Sampler or Iterable, optional): defines the strategy to draw
samples from the dataset. Can be any ``Iterable`` with ``__len__``
implemented. If specified, :attr:`shuffle` must not be specified.
batch_sampler (Sampler or Iterable, optional): like :attr:`sampler`, but
returns a batch of indices at a time. Mutually exclusive with
:attr:`batch_size`, :attr:`shuffle`, :attr:`sampler`,
and :attr:`drop_last`.
这段解释是关于Python中的数据集采样器(sampler)和批次采样器(batch_sampler)的说明。
- sampler(采样器)参数是用来定义从数据集中抽取样本的策略。它可以是任实现了__len__方法的可迭代对象(Iterable)。如果指定了sampler参数,则不能同时指定shuffle参数。
- batch_sampler(批次采器)参数与sampler类,但它一次返回一批索引。batch_sampler与batch_size、shuffle、sampler和drop_last参数互斥,也就是说使用batch_sampler时不能同时指定这些参数。
2. transform 里,取了不同值,这个有什么区别?
Transforms可以对图像或数据进行格式变换,裁剪,缩放,旋转等。Transforms常见类如下:
- ToTensor():适用于将图像数据从PIL图像对象或NumPy数组转换为PyTorch张量。
import torchvision.transforms as transforms
transform = transforms.ToTensor()
tensor_data = transform(pil_image)
-
Normalize:归一化处理。具体说,transforms.Normalize((0.1307,), (0.3081,)) 是一个数据转换操作,它将输入数据进行标准化处理。里的参数(0.1307,)和(0.3081,)分表示均值和标准差。
归一化过程如下:
对每个像素点的数值减去均值(0.1307)。
将结果除以标准差(0.3081)。 -
RandomHorizontalFlip(p=0.5):
这个取值以给定的概率p随机水平翻转图像。它适用于数据增强,可以增加训练数据的多样性。 -
Resize(size):
这个取值用于整图像的大小。size可以是一个整数表示将图像的较短边缩放到指定大小,或者是一个元组(height, width),表示将像的尺寸调整为指的高度和宽度。 -
Grayscale:将图像转换为灰度图。
3. epoch 和 batch 的区别?
Epoch(时期)是指将整个训练数据集通过神经网络进行一次正向传递和反向传播的过程。当一个epoch完成后,模型就完成了对整个训练数据集的一次训练。
Batch(批次)是指将训练数据集分成多个小批次进行模型训练的过程。在每个batch中,一小部分训练样本被送入网络进行正向传播、计算损失、计算梯度并更新参数。
区别如下:
- Epoch关注的是整个数据集的一轮训练,而Batch关注的是每次训练中送入网络的一小批数据。
- Epoch是整个数据集的迭代次数,而Batch是每次迭代中处理的数据量。
- 在一个epoch中,可能有多个batch,通过多个batch的迭代来完成整个数据集的训练。
以一个例子来说明:如果将一个数据集分为5个batch,然后开始进行训练,首先使用第一个batch进行前向传播、反向传播和参数更新,然后使用第二个batch,然后是第三个,以此类推,当处理完第五个batch后,完成了一个epoch。即完成了一次对整个数据集的训练。
4. 1x1的卷积和 FC 有什么区别?主要起什么作用?
1x1的卷积和全连接层(FC)是深度学习中常用的两种操作,它们的主要区别在于其输入和操作方式。
1x1卷积:
- 1x1卷积实际上是一种窗口尺寸为1x1的卷积操作。
- 1x1卷积通过在通道维度上进行卷积操作来改变特征图的通道数,但保持空间维度不变。
全连接层(FC):
- 全连接层的每个神经元与前一层的所有神经元相连接,每个连接都有一个对应的权重。
- 全连接层通常用于将前一层的特征映射转换为输出的预测结果。
主要作用:
- 1x1卷积主要用于控制模型的复杂度、调整通道数和特征融合。
- 全连接层主要用于将低层特征映射转换为最终的输出预测结果。
5. residual leanring 为什么能够提升准确率?
残差学习(Residual Learning)是一种用于提升深度神经网络准确率的技术,它通过引入跳过连接(skip connection)来解决深层网络训练中的梯度消失问题。以下是残差学习能够提升准确率的主要原因:
-
解决梯度消失问题:在传统的深层网络中,梯度在经过多个层的传播过程中可能会逐渐减小并消失,导致难以有效地训练深层网络。通过跳过连接,残差学习可以使梯度沿着捷径路径直接传播到后续层,避免了梯度消失问题,从而更好地优化深层网络。
-
网络的易优化性:引入跳过连接后,网络的优化目标变为优化残差(residual),而不再是优化整个映射。相对于直接优化底层输入和顶层输出之间的映射,优化残差更容易,因为残差通常具有较小的范围和较简单的模式。这使得网络更容易收敛并学习到更好的特征表示。
-
网络的深度扩展:残差学习允许通过增加更多的残差块来构建非常深的网络。由于跳过连接的存在,每个残差块的训练变得相对独立,可以有效地进行优化,从而在训练非常深的网络时更加容易。
6. 代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
代码练习二中的网络相对于LeNet,在两个卷积层和最后一个全连接层后分别添加了ReLU激活函数,但是没有添加最后的softmax函数。
7. 代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
在卷积操作后,特征图的尺寸通常会变小,这可能会对残差学习的应用造成一些挑战。然而,可以通过以下方式来应用残差学习:
-
使用适当的填充(padding):在卷积操作中,可以通过使用适当的填充方式来保持特征图的尺寸不变或者减小的幅度较小。常用的填充方式包括"same"填充和"valid"填充。"same"填充可以在卷积操作后保持特征图尺寸不变,而"valid"填充会使特征图尺寸减小。
-
使用尺寸匹配的跳过连接(Skip Connection):在引入跳过连接时,确保跳过连接前后特征图的尺寸大小匹配。可以通过1x1卷积或全连接层来调整特征图的通道数和尺寸,以便与跳过连接的特征图尺寸相匹配。
8. 有什么方法可以进一步提升准确率?
- 调整网络结构。对于CIFAR10数据集,CNN网络的准确 率只能在60%多,而ResNet网络的准确率可以达到90%以上。
- 尝试不同的优化器和损失函数,尝试调节超参数。















 530
530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









