







局部性原理:不久的将来要用到的信息与正在使用的信息很可能是存储空间相邻的。数组元素,顺序执行代码所致
时间局部性:不久的将来要用到的信息很可能是现在正在用的信息。循环结构所致
因为局部性原理,可以将当前访问地址及周围地址放入cache
性能分析:显然CPU同时访问cache和主存速度更快


主存与cache以“块”为单位进行数据交换(如:将每1KB视为1块)
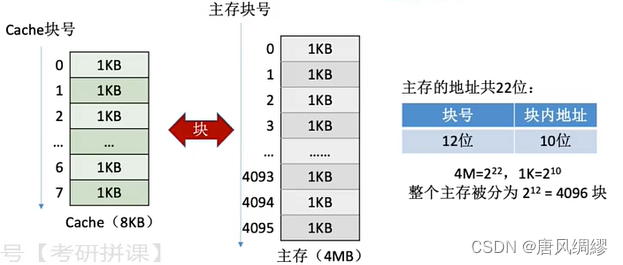 块,行,页,页面,页框都是一个意思
块,行,页,页面,页框都是一个意思
Cache与主存的映射方式:
- 全相连映射:主存块可以放在cache的任意位置

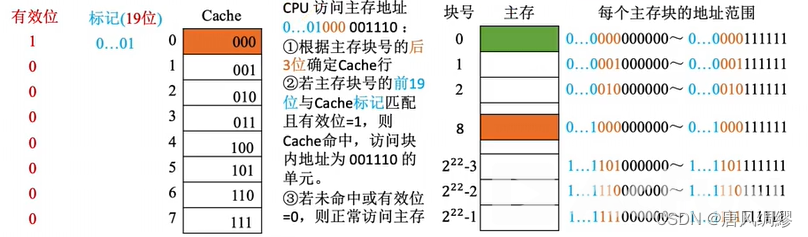 直接映射:只能放特定位置:cache号=主存号%cache总块数
直接映射:只能放特定位置:cache号=主存号%cache总块数
最后三位就是(主存号%cache总块数)的结果
存于同一cache块的地址后三位必一样。不同cache块的后三位必不同
- 组相连映射:将若干cache块分为1组,然后直接映射

Cache替换算法:当cache中没有空位时,替换谁
1.随机算法:字面意思
2.先进先出算法:字面意思
3.近期最少使用算法LRU:
为每一个 Cache块设置一个“计数器”,用于记录每个 Cache块已经有多久没被访问了。当 Cache满后替换“计数器”最大的
命中时:所命中的行的计数器清零,比其低的计数器加1,其余不变
未命中且有空闲:新装入的行的计数器置0,其余非空闲行全加1
未命中且无空闲:数值最大行的信息块淘汰,新装行的块的计数器置0,其余全加1
考试解题时问替换哪个:(下题cache有四块)
 需要替换时往前找,最晚出现的替换
需要替换时往前找,最晚出现的替换
4.最不经常使用算法:
为每一个 Cache块设置一个用于记录每个 Cache块被访问过几次。当 Cache满后替换“计数器”最小的。新调入的块计数器=0,之后每被访问一次计数器+1。需要替换时,选择计数器最小的一行。实际运行效果不如LRU
Cache写策略:
写命中:
写回法:
当CPU对Cache写命中时,只修改Cache的内容,不立即写入主存,只有当此块被换出时才写回主存。需要在cache块上加一位“脏位”表示数据是否被修改过。脏位为1则重写回主存。脏位为0则不用重写。
全写法:
把数据同时写入Cache和主存。因为写入主存速度慢,所以一般不直接写入主存,而是写入“写缓冲区”,由“写缓冲区”将信息逐一写入主存。如果写操作很频繁,可能导致写缓冲区饱和阻塞。
写不命中:
写分配法:把主存中的块调入Cache,在 Cache中修改。搭配写回法使用。
非写分配法:只写入主存,不调入cache。搭配全写法使用。
页式存储器:
设某一程序有4KB,主存中1块是1KB,那么需要将该程序分为四“页”,每页是1KB。
(页和块的意思差不多,不过页是逻辑上的含义,块是物理存储地址上的含义)
每一页对应主存上的一块,每一页有一个逻辑地址(虚地址),一一对应主存上的物理地址(实地址)。


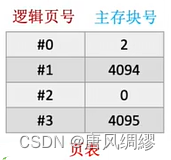 页表中的每一行叫一个页表项
页表中的每一行叫一个页表项
页表基址寄存器:存储页表的首位置(页表存储在主存的什么地方)
CPU读取数据时,将逻辑地址拆分为逻辑页号和页内地址,找到逻辑页号在页表中对应的主存块号,与页内地址拼接,得到数据的物理地址
因为页表在主存中,存取速度慢,可以建一个“快表”,用SRAM速度快,快表与页表的关系相当于主存与cache















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









