







 本文介绍了GoogleNet在ImageNet竞赛中的成就,特别是其Inception模块如何通过1x1卷积层减少计算量并实现更深网络设计。文章还讨论了原始Inception结构和改进版,以及全球平均池化在降低参数量上的应用。
本文介绍了GoogleNet在ImageNet竞赛中的成就,特别是其Inception模块如何通过1x1卷积层减少计算量并实现更深网络设计。文章还讨论了原始Inception结构和改进版,以及全球平均池化在降低参数量上的应用。
主干网络论文阅读(按论文时间顺序):
论文阅读 LeNET CONVOLUTIONAL NEURAL NETWORKS FOR ISOLATED CHARACTER RECOGNITION-CSDN博客
论文阅读 AlexNet ImageNet Classification with Deep ConvolutionalNeural Networks-CSDN博客
论文阅读 VGGNet VERY DEEP CONVOLUTIONALNETWORKSFORLARGE-SCALEIMAGERECOGNITION-CSDN博客
论文阅读 GoogleNet(Inception) Going deeper with convolutions-CSDN博客
论文阅读 ResNet Deep Residual Learning for Image Recognition-CSDN博客
论文阅读 ResNext Aggregated Residual Transformations for Deep Neural Networks-CSDN博客
这里讲GoogleNetV1
12年ImageNet竞赛冠军(vgg是亚军)。
其模型参数参数但只有AlexNet的1/12。
在GoogLeNet之前的卷积神经网络基本都是由多个卷积层与池化层堆积而成,然后接入一个或者多个全连接层来预测输出。这些图像特征为了适应全连接层的输入都会拉成一维向量,通常这就导致了网络模型参数主要集中在(第一个)全连接层;
池化层的主要目的是减少特征和网络参数,平均池化层主要保留图像的背景信息,最大池化层主要保留纹理信息。
网络结构:
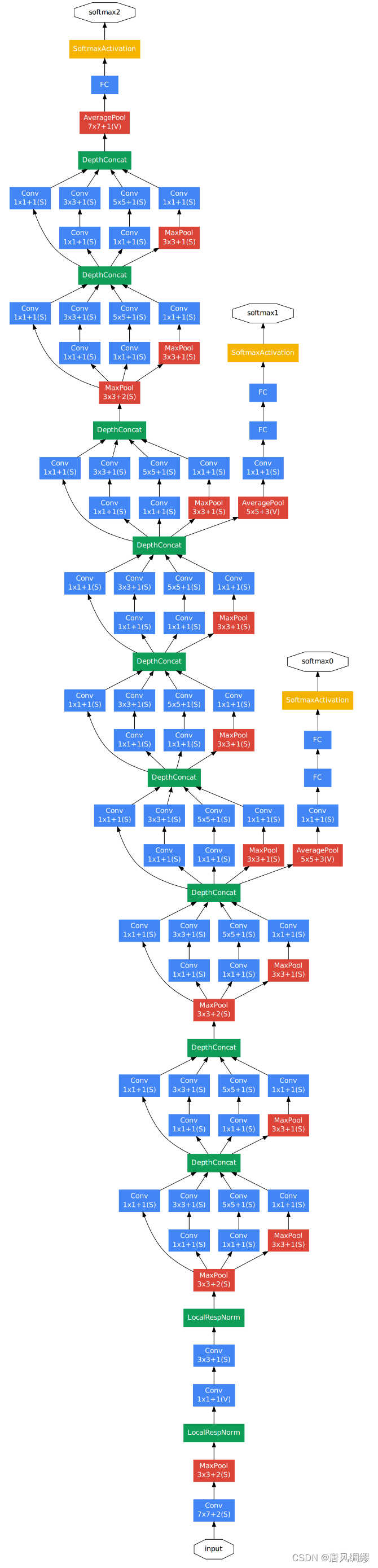
网络共22层,LocalRespNorm即LRN操作(AlexNet里提出的)
DepthConcat是Inception模块中的filter concatenation后面讲
Softmax0和softmax1用于辅助分类
GoogleNet核心内容在于Inception模块:
Inception模块主要在CNN中添加一个额外的1X1卷积层,使用Relu作为激活函数,其主要作用是在不牺牲网络模型性能的前提下,即实现网络特征的降维、减少大量计算量,这有利用训练更深更广的网络。
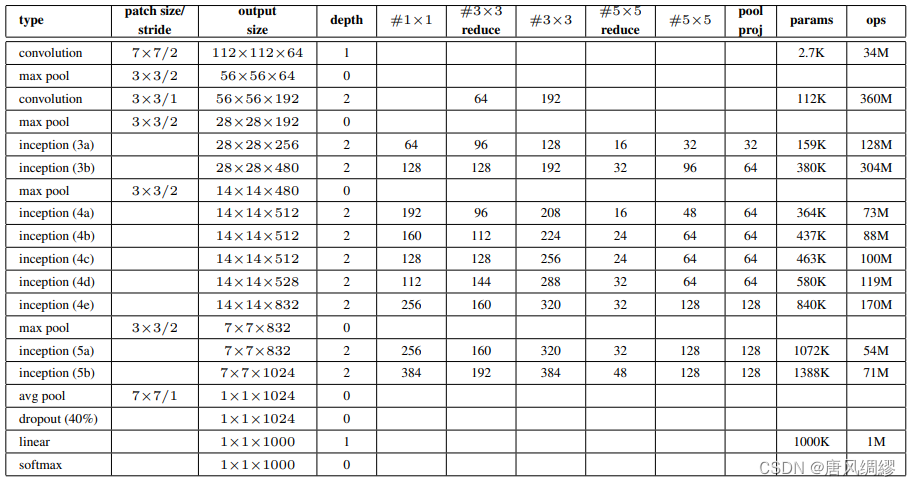
提高深度网络模型性能的常用方法就是提高网络模型大小,网络模型大小包括网络深度与网络宽度。在有足够的有标签数据的前提下,这是简单和保险的训练高性能模型的方法,但这会加大网络模型参数,加大了模型过拟合的风险。同时这也大大降低的训练周期,带来了大量的计算开销,尤其是在全连接层。解决上述两个问题的可行方式就是利用稀疏连接来代替全连接层。
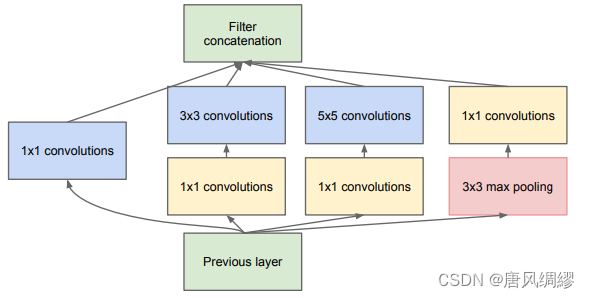
Inception 结构的主要思路是用密集成分来近似最优的局部稀疏结构。原始Inception 结构如下图所示

原始Inception 结构采用1×1、3×3和5×5三种卷积核的卷积层(和一个最大池化)进行并行提取特征,这可以加大网络模型的宽度,不同大小的卷积核也就意味着原始Inception 结构可以获取到不同大小的感受野。只要设置不同的padding就可以用不同大小的卷积核得到同样大小的特征图,最后的filter concatenation简单理解为把特征图摞起来。
但是原始Inception结构中卷积核仍然会带来巨大的计算量。GoogLeNet借鉴了使用1×1卷积层与5×5卷积层相结合来实现参数降维:
假如上一层的输出为100×100×128,经过具有256个输出的5×5卷积层之后(stride=1,pad=2),输出数据为100×100×256。其中,那么卷积层的参数为128×5×5×256。此时如果上一层输出先经过具有32个输出的1×1卷积层,再经过具有256个输出的5×5卷积层,那么最终的输出数据仍为为100×100×256,但卷积参数量已经减少为128×1×1×32+32×5×5×256,相比之下参数大约减少了4倍。
改进后的Inception结构如下图所示:
此外,GoogleNet用一个全局平均池化代替(第一个)全连接层以减低参数量
















 4879
4879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









