







自然语言处理笔记
自然语言处理笔记 第三章 隐马尔科夫模型与序列标注-CSDN博客
自然语言处理笔记 第五章 条件随机场与序列标注-CSDN博客
两种流派:
基于规则的专家系统:针对需求设计规则死板不稳定
基于统计学的机器学习:通过构建语料库让计算机学习
语料库:分为中文分词语料库、词性标注语料库等等,实现一种功能就需要一种语料库
词典分词基本介绍:
词典分典
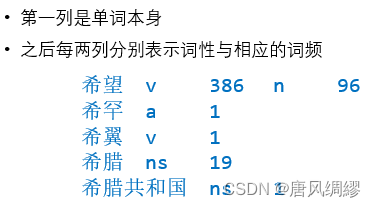
词的定义:具有独立意义的最小单位 ![]()
词频:二八定律
词典:记录大量词的词库
Hanlp词典
切分算法:
1、完全切分---找出文本中的所有词,不是标准意义上的分词

从文本(长度为n)的第i个字开始(i初始=0)。匹配[i,i+1]一直到[i,n]。然后i++。直到i=n。 问题:会重复匹配(如:出租车à出租,出租车)
2、正向最长匹配
最长匹配不是返回一个最长词,而是多个最长词

从文本(长度为n)的第i个字开始(i初始=0)。匹配[i,i+1]一直到[I,n]。选择其中最长的放到word_list待输出;第二轮匹配i从上一轮的最长词之后第一个字开始,找第二个最长词。如果没有匹配到任何一个词,word_list就加入当前的单个字作为这一轮的最长词。
3、逆向最长匹配

与正向相似,只是倒着来
但正向匹配和逆向匹配的结果未必相同
如:我一个人吃饭 正向:![]() 逆向:
逆向:![]()
4、双向最长匹配

优先返回逆向的原因:统计学规律,逆向匹配正确率高
速度:正向逆向速度差不多;python比java慢
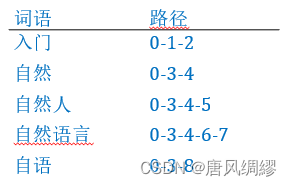
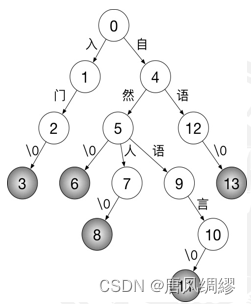
字典树(前缀树)
每个字符串末尾添加一个\0(散列值=0),普通节点不需要分配内存标记颜色
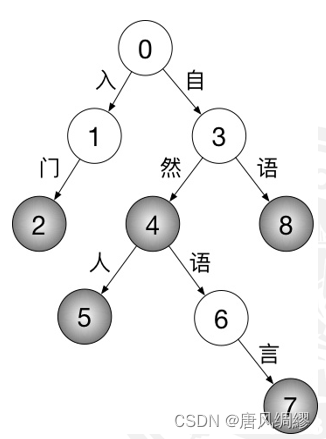
从有限自动机DFA的角度看每个节点对应着一个状态(这个状态就是当前的前缀)
状态转移:向父节点询问该字符与子节点对应边(边上存储字符的整型值)的关系,若存在满足条件的边,则转移状态到子节点
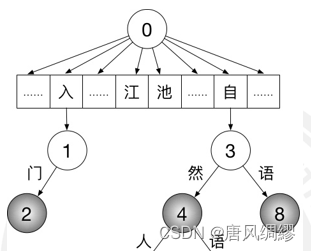
首字散列其余二分的字典树
中文大多是二字词,因此第一次状态匹配的速度十分重要。
第一次匹配:创建一个长为 65536 的数组,将子节点按对应的字符整型值作为下标放入该数组即可。这样每次状态转移时,只需访问对应下标就行了。
前缀树的优点:

双数组字典树DAT
Base数组每个元素表示一个状态,check数组每个元素表示一个状态的前驱状态
每个字符串末尾添加一个\0(散列值=0),普通节点不需要分配内存标记颜色
状态转移:
当状态s接受字符c转移到状态t时,双数组满足
base[s]+c:s状态+c(s的前缀加c)得到了t状态。t状态的前驱状态为s状态。
查询: (base[p]<0时,对应单词结尾)

最开始的状态b=0,待识别字符串为key。通过循环依次匹配key[i]和b,匹配成功则令当前状态b=本次匹配成功后的状态p。若在循环结束前p=-1则提前return跳出循环。
令![]() (p=最终状态b的前缀+结尾状态\0)(注意,这里的p
(p=最终状态b的前缀+结尾状态\0)(注意,这里的p
和循环里面的p完全无关)。令n=base[p]即末尾节点的前缀。第二个if的第一个条件是状态转移的判定 (此步是否有必要?)。第二个条件是判断末尾节点是不是单词结尾。
(此步是否有必要?)。第二个条件是判断末尾节点是不是单词结尾。
注意:该算法对于key[]串最后一个元素是不是/0有容忍性,有的话循环结束时不会记录(else中没有令b=p),没有的话后面会补上(![]() ,c=/0)(应该是这样吧...);如果key[]中间就出现了/0的话,那么for循环到此为止,/0后面的就不管了。
,c=/0)(应该是这样吧...);如果key[]中间就出现了/0的话,那么for循环到此为止,/0后面的就不管了。
AC自动机
速度优于字典树,原因:


实现方法:
Goto表:
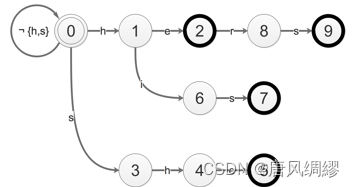 其实就是前缀树
其实就是前缀树
Output表:
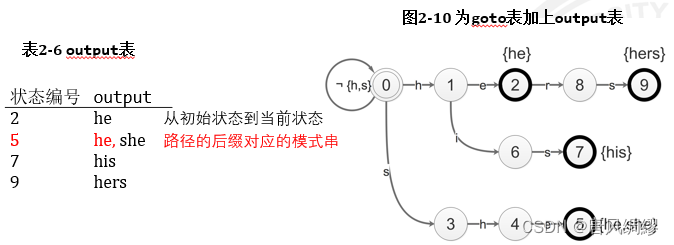
Fail表:存储状态转移失败后应当转移到的节点
which? 节点状态为已匹配的字符串的最长后缀
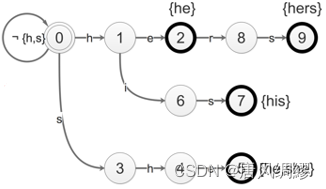
例:节点7---his继续匹配,匹配失败后,节点3的状态---s,是his在表上的最长后缀;节点5---she继续匹配,匹配失败后,节点2的状态---he是she在表上的最长状态。
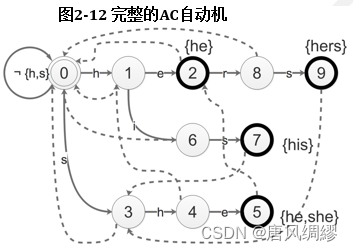
(双数组字典树DAT和AC自动机可以结合---ACDAT,提升性能)
准确率评测:
精度P:被判定为正样本里有多少真的是正样本
召回率R:所有正样本里有多少被判定为正样本
OOV:未登录词(out of vocabulary),新词
IV:“登录词”(in vocabulary),词典里有的词
定义F1值:![]()

















 1811
1811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









