







自然语言处理笔记
自然语言处理笔记 第三章 隐马尔科夫模型与序列标注-CSDN博客
自然语言处理笔记 第五章 条件随机场与序列标注-CSDN博客
序列标注:
给定一个序列x=x1x2…xn![]() ,找出序列中每个元素对应标签y=y1y2…yn
,找出序列中每个元素对应标签y=y1y2…yn![]() 的问题
的问题
其中,y![]() 所有可能的取值集合称为标注集(TagSet)
所有可能的取值集合称为标注集(TagSet)
中文分词可以转化为标注集为{切,过}![]() 的序列标注问题
的序列标注问题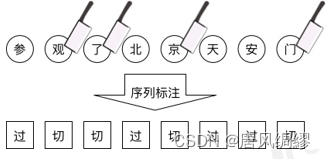
之后人们提出{B,M,E,S}这种最流行的标注集:汉字分别作为词语首尾(Begin、End)、词中(Middle)以及单字成词(Single)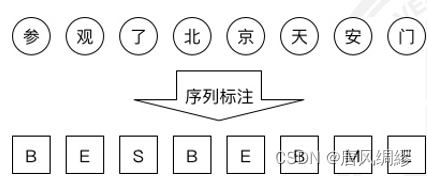
不同的标注集可用于不同功能,如用于词性标注的POSTagSet、用于命名实体识别的NERTagSet等
隐马尔科夫模型:
描述两个时序序列联合分布p(x,y)![]() 的概率模型。x
的概率模型。x![]() 序列外界可见,称为观测序列(显状态)。y
序列外界可见,称为观测序列(显状态)。y![]() 序列外界不可见,称为状态序列(隐状态)。
序列外界不可见,称为状态序列(隐状态)。
NLP中,x为单词,y为词性。

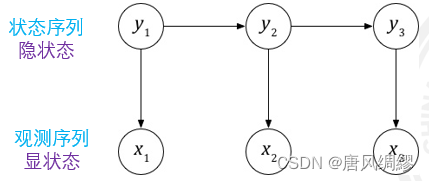
隐马尔可夫模型利用三个要素来模拟时序序列的发生过程:
初始状态概率向量;状态转移概率矩阵;发射概率矩阵(亦称观测概率矩阵)
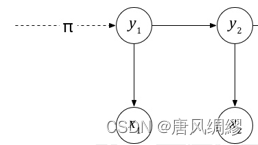

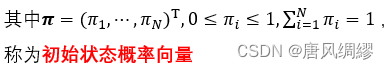
 因为状态有N个可能的取值,所以矩阵为N*N。第i行j列的值代表从状态i转移到状态j的概率
因为状态有N个可能的取值,所以矩阵为N*N。第i行j列的值代表从状态i转移到状态j的概率
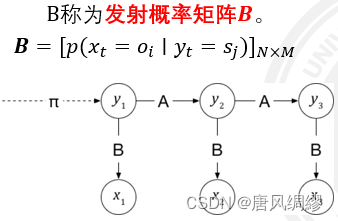 设有x个状态,y个单词,则B是n*m矩阵
设有x个状态,y个单词,则B是n*m矩阵
隐马尔可夫模型的三个基本用法:
样本生成:给定模型λ=(π,A,B)![]() ,生成满足模型的样本
,生成满足模型的样本
模型训练:给定训练集,生成模型参数λ=π,A,B![]()
序列预测:已知模型λ=π,A,B![]() 和观测序列x,求最大概率y
和观测序列x,求最大概率y
样本生成:给定模型λ![]() ,生成满足模型的样本
,生成满足模型的样本

模型训练:给定训练集,生成模型参数λ![]()
利用极大似然法来估计隐马尔可夫模型的参数
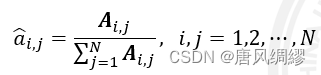
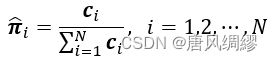
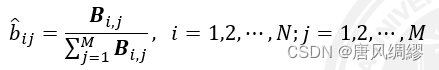
序列预测:已知模型λ![]() 和观测序列x,求最大概率y。
和观测序列x,求最大概率y。
 维特比算法
维特比算法
其他实际问题:
字符映射:字符作为观测变量,必须是整型才被隐马尔科夫模型接受。因此需要从字符串形式到整型的映射
语料转换:将语料转换为(𝒙,𝒚)二元组才能训练隐马尔可夫模型,因此需要将一个句子转换为二元组
二阶隐马尔科夫模型:如果隐马尔可夫模型中每个状态依赖于前两个状态,则称为二阶
效果评测: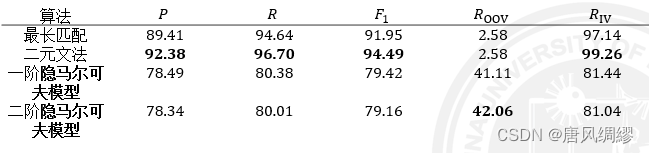















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









