






文章目录
CLIMS: Cross Language Image Matching for Weakly Supervised Semantic Segmentation
摘要
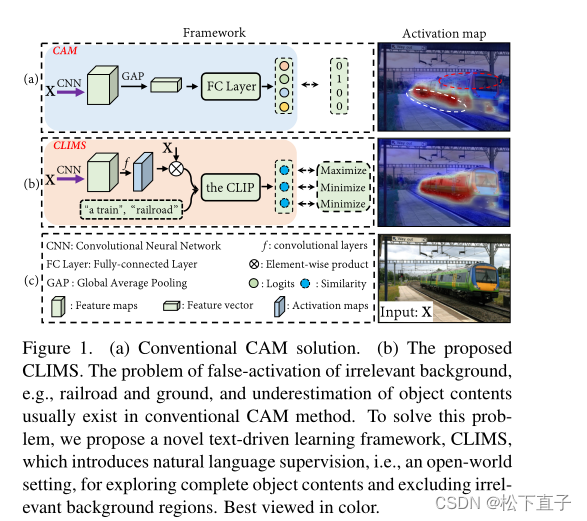
存在的问题
CAM(类激活图)通常只激活有区别的对象区域,并且错误地包含了大量与对象相关的背景,由于WSSS(弱监督语义分割)模型只有一组固定的图像级对象标签,因此很难抑制由开放集对象组成的不同背景区域。
本文方法
提出了一个跨语言图像匹配(CLIMS)框架,基于最近引入的CLIP模型,用于WSSS。
引入自然语言监督来激活更完整的目标区域,抑制密切相关的背景区域。
设计了目标区域、背景区域和文本标签匹配损失,引导模型为每个类别的CAM激发更合理的目标区域。
此外,还设计了一个共存背景抑制损失,以防止模型激活密切相关的背景区域,并使用预定义的类相关背景文本描述集。
代码链接
论文链接
方法
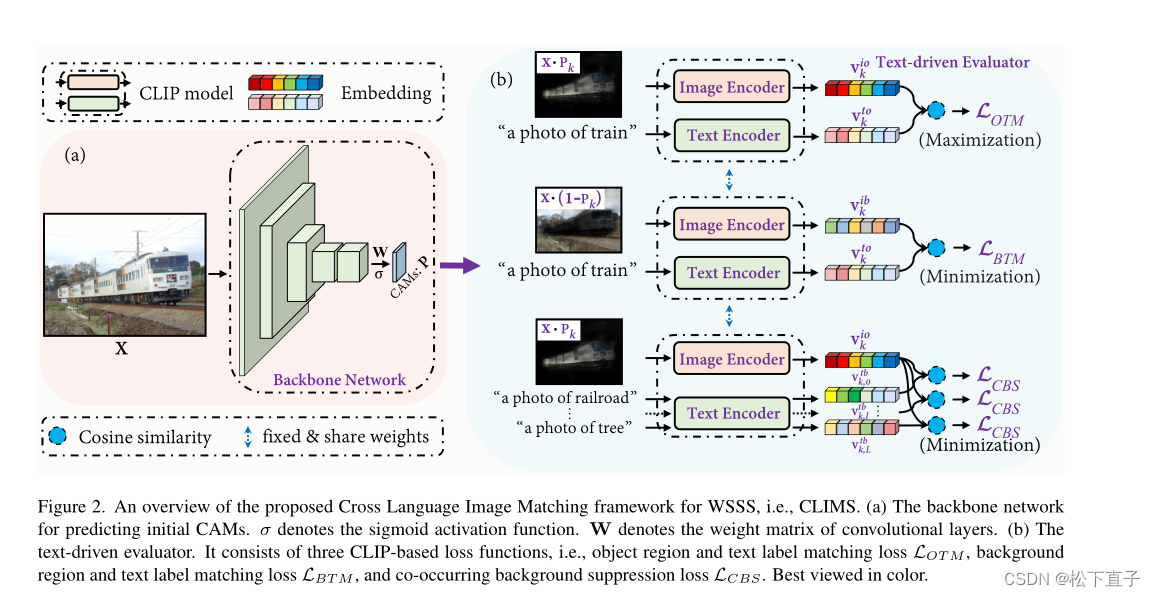
(a)用于预测初始cam的主干。σ表示sigmoid激活函数。W为卷积层的权值矩阵
(b)文本驱动的评价器。由三个基于clip的损失函数组成,即对象区域和文本标签匹配损失,背景区域和文本标签匹配损失和共现背景抑制损失
语言图像匹配框架
与传统的CAM解相似,不同之处是去掉了GAP层,在W后直接应用sigmoid函数σ:
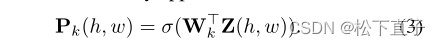
文本驱动的评估器由来自CLIP模型的图像编码器fi(·)和文本编码器ft(·)组成。首先,Pk和(1−Pk)分别乘以X来屏蔽前景对象和背景像素。然后通过fi(·)将结果映射到表示向量viok和vibk:
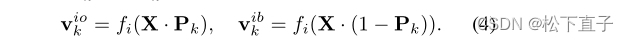

可以取了解一下CLIP模型
给定第k个前景对象表示viok及其对应的文本表示vtok,我们首先计算图像和文本表示之间的余弦相似度,然后使用提出的对象区域和文本标签匹配损使其最大化:
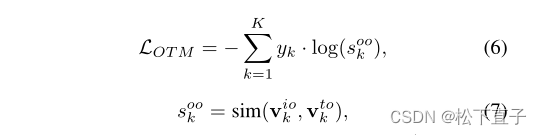
生成的初始CAMs将在上面损失函数的监督下逐渐接近目标物体。但是,仅使用LOTM并不能促使模型探索非判别目标区域并抑制激活的背景区域
为了提高激活对象区域的完整性,我们设计了背景区域和文本标签匹配损失LBTM,以包含更多的对象内容。已知背景表示法vibk及其对应的文本表示法vtok(注意,LBTM的文本标签与LOTM的文本标签相同),则LBTM的计算方法如下:
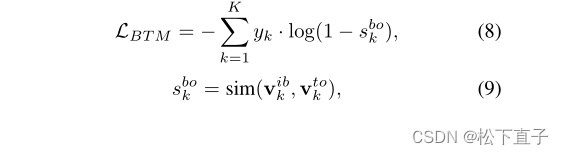
上述两个损失函数只保证了P完全覆盖目标对象,没有考虑到共现类相关背景的假激活。同时出现的背景可能会显著降低生成的伪标签掩模的质量。然而,对这些背景进行像素级标记非常耗时且耗费人力,并且通常在WSSS中无法提供。由于背景的集合比前景的集合更加多样化,使用ImageNet训练的分类网络可能看不到其中的许多背景。然而,根据相应的文本描述,使用预训练的CLIP来识别这些背景要容易得多。为了解决这一问题,我们设计了以下共现背景抑制损失。给定目标对象表示形式viok及其对应的与类相关的背景文本表示形式vtbk,l,损失计算为:
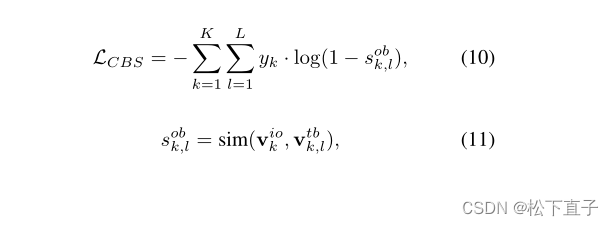
在训练过程中,网络会逐渐抑制Pk中类相关背景区域的假激活,使LCBS最小化。
在只有LOTM、LBTM和LCBS的情况下,如果激活图中同时包含不相关的背景和目标对象,CLIP模型仍然可以正确预测目标对象。因此,我们设计了一个像素级区域正则化项来约束激活图的大小,以确保不相关的背景在激活图Pk中被排除:
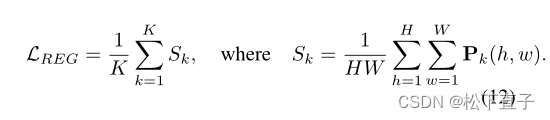
总的训练目标:
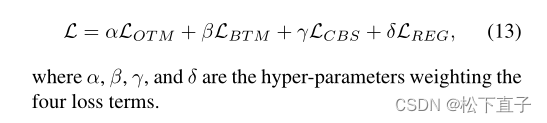
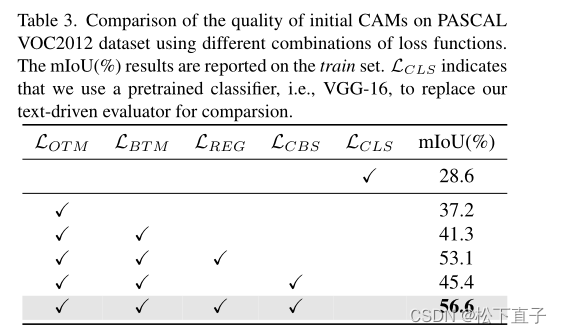
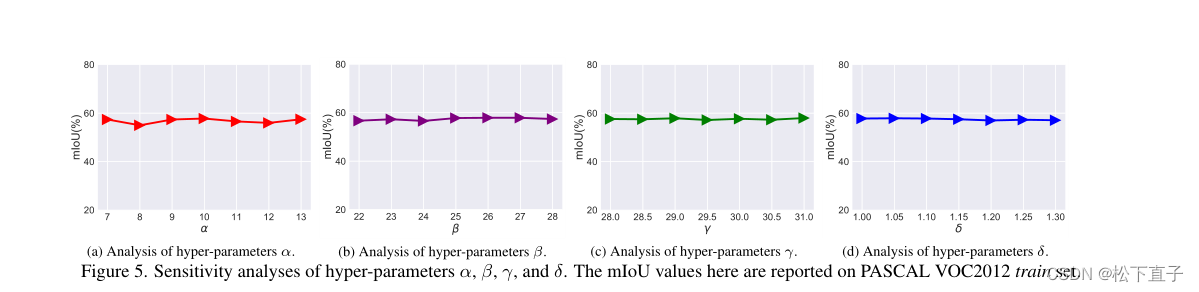
实验结果















 1725
1725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











