当然,我会提供一个代码框架,并且根据您的数据集和模型选择进行适当的调整。下面是一个简单的深度学习半监督语义分割的代码框架:
```python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
from skimage.io import imread
from skimage.transform import resize
# Define hyperparameters
num_epochs = 50
batch_size = 4
learning_rate = 0.001
img_height = 256
img_width = 256
num_classes = 2
# Define transforms for data augmentation
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5), (0.5))
])
# Define dataset class
class SegmentationDataset(Dataset):
def __init__(self, image_dir, mask_dir=None):
self.image_dir = image_dir
self.mask_dir = mask_dir
self.image_files = sorted(os.listdir(image_dir))
def __getitem__(self, idx):
img = imread(self.image_dir + self.image_files[idx])
img = resize(img, (img_height, img_width))
if self.mask_dir:
mask = imread(self.mask_dir + self.image_files[idx], as_gray=True)
mask = resize(mask, (img_height, img_width))
mask = (mask > 0).astype(float)
mask = torch.from_numpy(mask).float()
return transform(img), mask
return transform(img)
def __len__(self):
return len(self.image_files)
# Define model class
class SegmentationModel(nn.Module):
def __init__(self):
super(SegmentationModel, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3, padding=1)
self.bn1 = nn.BatchNorm2d(16)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(16, 32, 3, padding=1)
self.bn2 = nn.BatchNorm2d(32)
self.relu2 = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(32, num_classes, 1)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.conv3(x)
return x
# Define training function
def train_model(model, dataloader, criterion, optimizer, device):
model.train()
for i, (inputs, targets) in enumerate(dataloader):
inputs = inputs.to(device)
targets = targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
# Define testing function
def test_model(model, dataloader, criterion, device):
model.eval()
total_loss = 0
with torch.no_grad():
for inputs, targets in dataloader:
inputs = inputs.to(device)
targets = targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
total_loss += loss.item()
return total_loss / len(dataloader)
# Define main function
def main():
# Define data paths
image_dir = 'path/to/image/folder/'
mask_dir = 'path/to/mask/folder/'
# Split data into train and test sets
dataset = SegmentationDataset(image_dir, mask_dir)
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
# Define dataloaders for training and testing
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
# Instantiate model, criterion, and optimizer
model = SegmentationModel()
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Move model and criterion to GPU if available
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
criterion.to(device)
# Train the model
for epoch in range(num_epochs):
train_model(model, train_dataloader, criterion, optimizer, device)
test_loss = test_model(model, test_dataloader, criterion, device)
print(f'Epoch [{epoch+1}/{num_epochs}], Test Loss: {test_loss:.4f}')
if __name__ == '__main__':
main()
```
请注意,这只是一个框架,您需要根据您的数据集和模型调整超参数和网络结构。另外,请不要将此代码或其派生代码用于商业或不当用途。








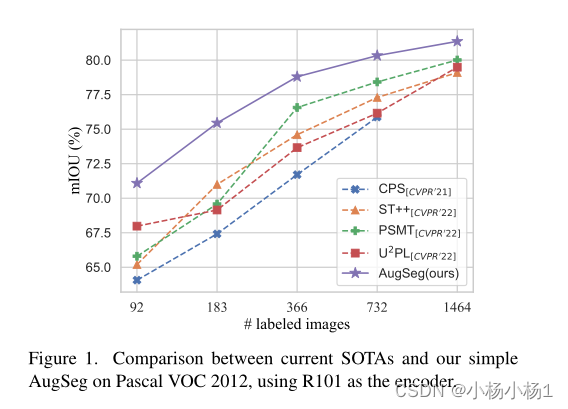
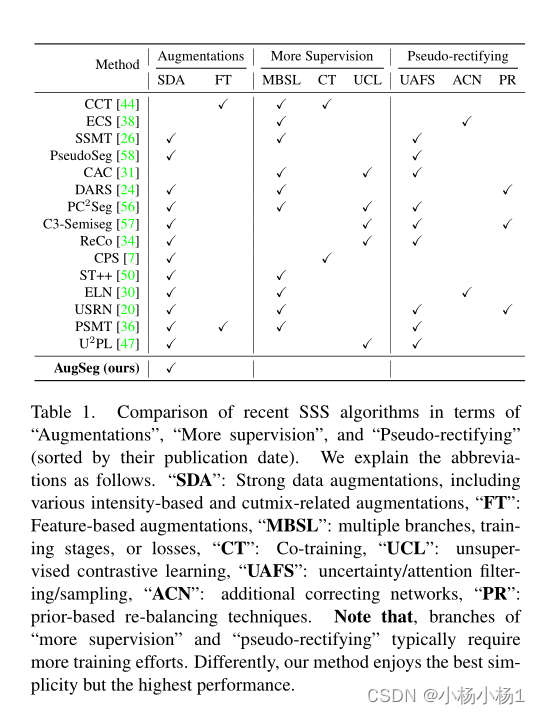
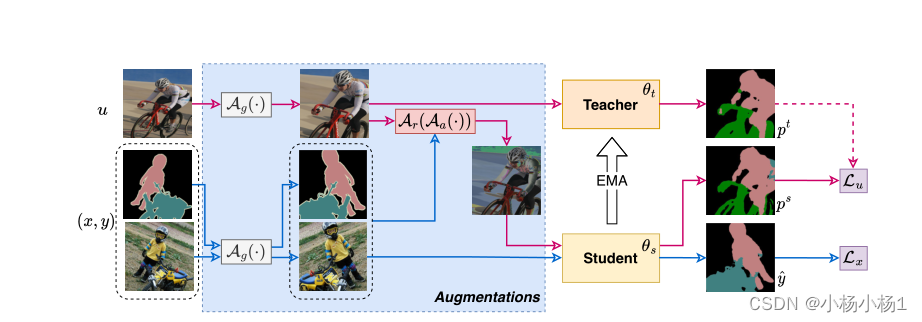
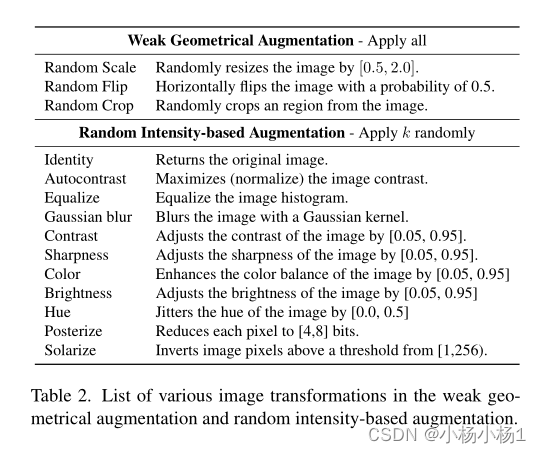
















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











