







Augmentation Matters: A Simple-yet-Effective Approach to Semi-supervised Semantic Segmentation
paper
code
创新点:
创新点1: random intensity-based augmentation
作者一直在强调一个观点:现存的数据增强策略基本都是为监督学习设计的,其思路都是获取特定的最优增强策略。但是在一致性正则化中,数据扰动的目标是从同一图像生成两个不同的视图,其中不需要特定的最优增强策略。
因此基于以上观点,作者根据一致性正则化的要求,对现存的被设计用于监督学习的data aug进行简化改进。
改进方案如下:

看起来好像就是从之前的RandomAug里面专门选了强度类的增强来用。
创新点2: Adaptive CutMix-based augmentations
这个说实话,我也没咋看懂,只能按照论文说一下,懂的大佬求带。
图例如下:
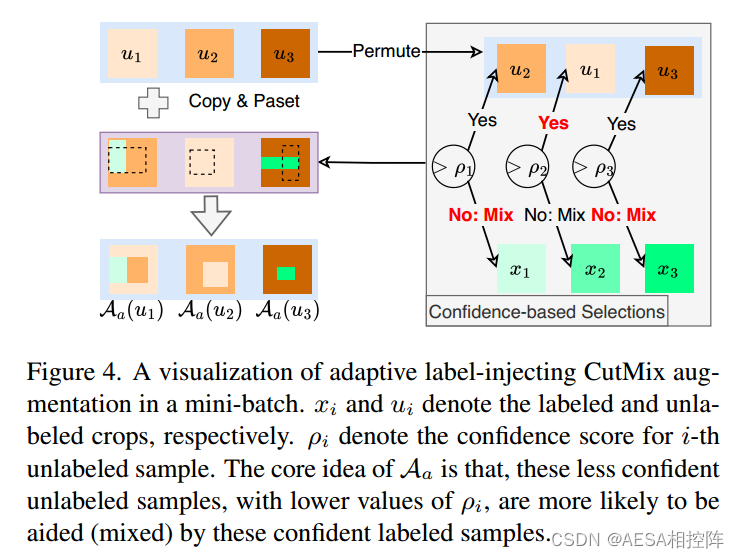
1、作者首先强调了CutMix对半监督学习的重要性(尤其是用在强扰动分支),但是强调了一个bug,就是前面学者的工作都仅仅是把CutMix用在unlabel的伪标签之间,他认为这种这种方式会不可避免的为模型带来偏差,尤其是对那些难以训练的数据样本,以及在训练早期阶段。
这点不难理解,对于难以训练的数据样本来说,伪标签本来就带有大量的错误,再CutMix一个新生成的错误样本进行,只会让模型更加累计偏差走偏。
模型训练早期也和这个类似,早期模型性能本来就不行,再用CutMix一个新生成的错误样本加入训练,同样会累计偏差,降低模型性能。
2、因此基于以上分析,作者的想法是,既然无法保证unlabel的伪标签都是正确的,那就强行赛一个正确的进去,强行进行监督。也就是label和unlabel进行CutMix。
3、但是这个想法还是有一个风险,unlabel那些被label的CutMix后,完全遮挡住了,相当于unlabel中被遮挡住的这一块区域句完全浪费掉了,万一这个区域恰恰包含重要信息呢?这样无疑就降低了对unlabel的利用,违背了半监督学习的初衷,既对unlabel数据充分使用。
4、那么如何解决这个unlabel没有被充分使用的问题?于是就设计了这个叫做自适应标记注入增强(adaptive label-injecting augmentation)的data aug。
流程大概如下:
step1:计算当前模型在第i个unlabel实例的predict的置信度分数p_i:

step2:使用归一化预测熵的加权平均值来估计unlabel样本u_i的置信度得分。
step3:使用p_i作为触发概率,随机的应用于label与unlabel之间的CutMix混合,得到混合候选:

step4:得到混合候选后,执行最后的混合,既将unlabel样本u_m与上一步得到的排列的混合候选进行混合:

最后的一步我没明白,为什么要再混合一次?按照我理解的,其实就是以置信度为阈值作为CutMix混合触发概率,挑选那些置信度低的样本(代表样本难以训练or训练早期模型性能不好导致的置信度不高)与label样本进行CutMix,加强这些置信度低的样本的监督约束,那公式(8)其实已经达到目的了。
为什么要拿着已经CutMix的样本再去和一个unlabel样本u_m再CutMix一次???
Model讲解

整个模型全程没有对模型进行修改,全部精力都用在数据增强策略上。
step1:label样本(x,y)经过弱增强后分为两个支路,一个支路进入Student模型进行训练。另外一个支路与经过同样弱增强的unlabel样本u,通过Adaptive CutMix-based augmentations后,再经random intensity-based augmentation后,进入Student进行训练生成对label样本(x,y)的预测y_^、label样本(x,y)与unlabel样本u经CutMix、随机强度增强后的预测 p_s。
step2:Student的权重参数经过移动平均后得到Teacher模型,Teacher模型对经过弱增强的unlabel样本u进行预测,生成预测p_t。
step3:使用p_t来监督p_s。
weakly-augmented

看起来都是image-level的。
strongly-augmented
1、random intensity-based augmentation

2、Adaptive CutMix-based augmentations
loss
step1:Model是经过label标签训练过的分割网络,因此对于label监督部分的损失为传统的交叉熵损失:
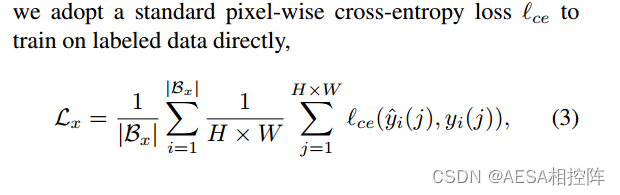
step2:unlabel的损失:

总loss为:

实验结果:
对比实验

Table4:在PASCAL VOCAug上的实验对比。

Table5:在Cityscapes上的实验对比。
消融实验:
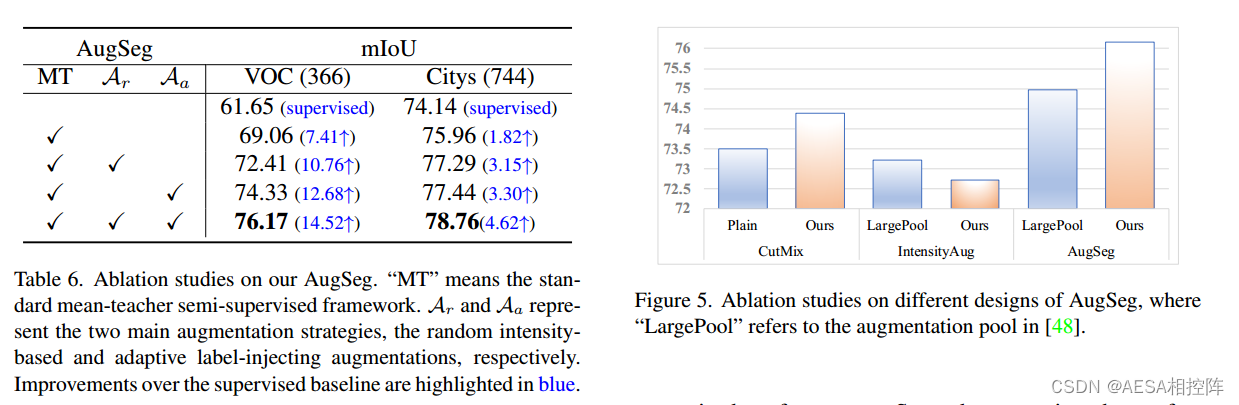
Table6:讨论AugSeg三个部件的作用。
Figure5:讨论不同aug设计的影响。
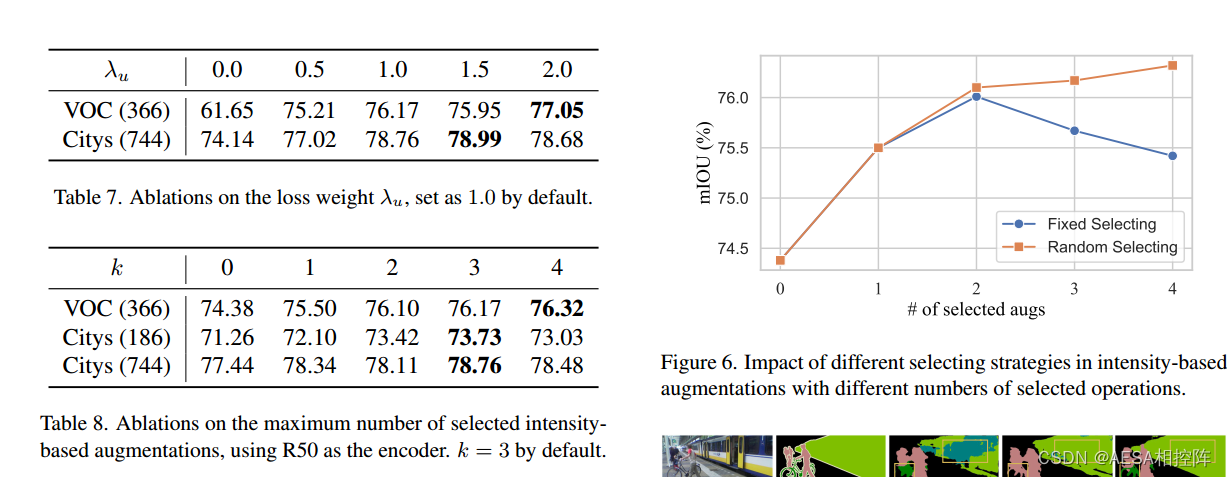
Table7:讨论在不同数据集下使用不同的损失权重值的影响。
Table8:讨论最大数量intensity-based augmentations选择的影响。
Figure6:固定选择策略与随机选择策略随着选择aug数目增加对模型性能的影响。
个人小结:
1、当前默认的数据增强并不一定适用于半监督学习的一致性正则化,直接使用有可能会带来偏差累计,伤害模型性能。
2、强扰动的数据增强算法方案选择与设计很关键,image-leve扰动非常重要,可以多从任务的本质出发,设计更加符合任务的data aug。
3、实验一定要多设计、尽可能的考虑到方方面面,从多角度验证模型的可行性。
4、对高质量的label使用非常重要。
5、使用MT可以增强对困惑类别的分辨能力。















 1548
1548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









