







 本文提出一种深度反应扩散模型,通过整合系统生物学和深度学习,揭示阿尔茨海默病中淀粉样蛋白和tau神经原纤维的相互作用,以提高早期诊断的准确性,并在ADNI数据上展示了其优势。模型考虑了神经网络的动态特性,为理解疾病病因提供了新视角。
本文提出一种深度反应扩散模型,通过整合系统生物学和深度学习,揭示阿尔茨海默病中淀粉样蛋白和tau神经原纤维的相互作用,以提高早期诊断的准确性,并在ADNI数据上展示了其优势。模型考虑了神经网络的动态特性,为理解疾病病因提供了新视角。
文章目录
Enhance Early Diagnosis Accuracy of Alzheimer’s Disease by Elucidating Interactions Between Amyloid Cascade and Tau Propagation
摘要
尽管淀粉样蛋白(Aβ)沉积和tau神经原纤维缠结(tau)是阿尔茨海默病(AD)的重要特征,但越来越多的证据表明Aβ和tau之间的相互作用是理解AD病因的关键。然而,在当前最先进的AD早期诊断模型中,这两个AD特征通常被视为独立变量,这可能部分地导致了解释性不足的问题。受系统生物学最近的进展启发,Aβ级联和tau传播的生物过程被形式化为一个封闭环反馈系统,该系统动态受到脑内区域间白质纤维束的约束。在此基础上,Aβ-tau相互作用被概念化,遵循最优控制原理,作为AD的病理生理机制。
在这种情况下,提出了一种深度反应扩散模型,利用深度学习和系统生物学的见解,使人们能够提高发展AD的预测准确性,并且揭示Aβ-tau相互作用的潜在控制机制。这项研究在阿尔茨海默病神经影像计划(ADNI)的神经影像数据上进行了评估,不仅提高了疾病进展的预测准确性,而且比传统的(“黑匣子”)深度模型更好地理解了疾病病因。
本文方法
从脑动力学的角度看,针对每个脑区域引入了演化状态 vi(t),被视为每个脑节点特征的内在交互轨迹。基于此,研究了两个脑区域特征,即 tau-xi(t) 和 Aβ-ui(t),并探究了它们之间的相互作用,这被认为在阿尔茨海默病(AD)进展的演化动态 V(t) 中扮演关键角色。特别地,研究了Aβ对AD进展中tau传播的影响。该研究旨在揭示AD进展的复杂机制,是神经科学领域的重要研究课题。
Reaction-Diffusion Model for Neuro-Dynamics
RDM是一种能够捕捉各种动态进化现象的数学模型,通常用于描述控制大脑动态状态v(t)进化的反应扩散过程。
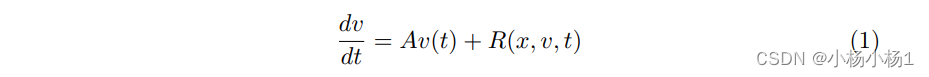
方程(1)中的第一项表示受网络拓扑结构 A 约束的扩散过程(即节点之间的信息交换),其中 A = −∇ · (∇) 表示拉普拉斯算子,由梯度 ∇ 的散度 ∇· 表示。而 R(x, v, t) 表示包含观察 x 和演化状态 v 之间非线性交互的反应过程。在深度神经网络中,这种非线性交互通常被定义为 RΘ(t) = σ (β1V (t) + β2X(t) + μ),其中 σ 为激活函数,β1、β2 和 μ 是可学习参数。
Construction on the Interaction Between Tau and Amyloid
传统上,通过将tau和淀粉样蛋白视为图中的嵌入来建立它们之间的联系,但这种方法无法捕捉节点嵌入特征之间的相互作用。因此,提出了一种新颖的解决方案来建模tau和淀粉样蛋白之间的相互作用。在反应扩散模型基础上,引入了一个交互项,描述了淀粉样蛋白在评估tau积累过程中如何影响了tau的传播。根据这一线索,提出了一个新的偏微分方程。
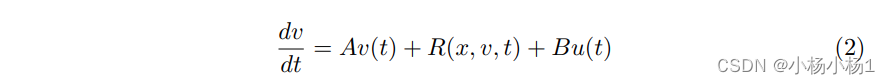
设计的最后一项表征了演化状态 v 和 u 之间的相互作用,其中 B 表示交互矩阵。为了合理和适当地建立这种相互作用,我们引入了一个交互约束,确保了理想的演化状态。在控制理论中,灵感来自线性二次调节器(LQR),交互约束被制定为:
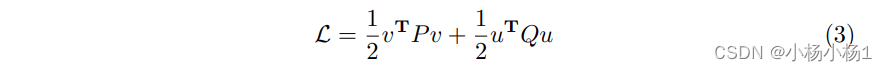
要求 L ≥ 0 意味着 P 和 Q 都是正定的。通过最小化目标函数(式子3),可以实现新的PDE的稳定和高性能设计。为了实现这一目标,可以通过一个最优控制约束问题来最小化式子(3)。这种最优控制约束被视为一个闭环反馈系统,u 作为控制项在控制理论中产生最优反馈。此外,为了考虑已知的临床结果(即标签的 ηT ),将临床结果作为优化过程中的最终cost进行了合并。
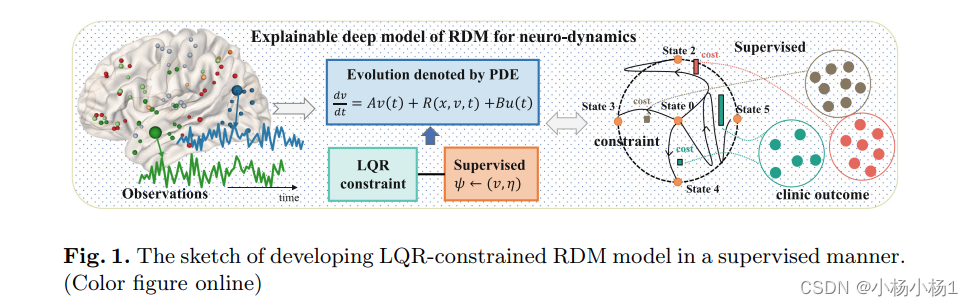
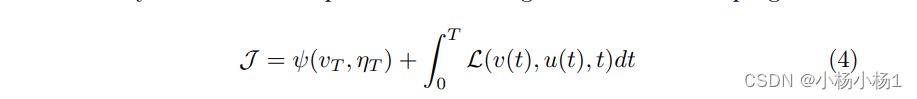
最终cost ψ(vT , ηT ) = KL(vT , ηT ) 使用 Kullback-Leibler (KL) 散度来衡量预测的最终状态 vT 与标签状态 ηT 之间的差异。第二项是式子(3)中描述的 LQR 约束。为了解决这个优化问题,按照[5]中概述的方法进行操作,首先构建一个新的 PDE 来模拟脑动力学的演化,然后在 LQR 的基础上引入一个交互约束,最后利用标签来指导学习,优化方程。整个框架的概述如图1所示。
Neural Network Landscape of RDM-Based Dynamic Model
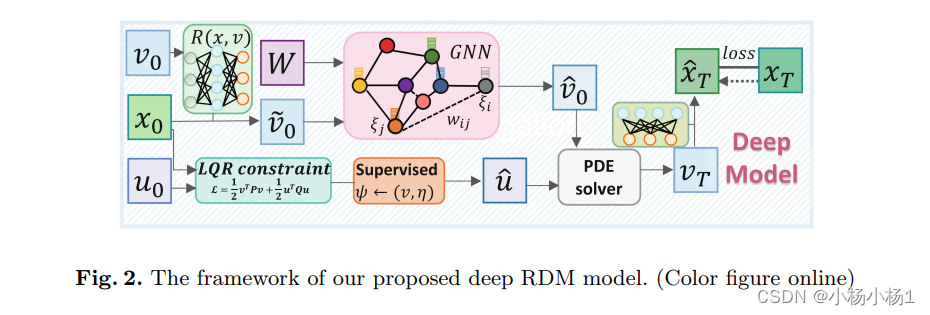
整个物理信息模型的整体网络架构如图2所示,其中骨干是反应扩散模型。具体来说,首先通过深度神经网络(DNN,绿色阴影)定义反应过程(式子(2)中的 R(x, v)),从而通过初始状态 v0 和观察到的 tau 水平 x0 生成反应状态 v˜0。然后通过基础 GNN 进行图扩散过程(红色阴影),接着通过定制的反应扩散模型获得理想的特征表示 vˆ0。受闭环反馈系统的启示,我们实现了LQR以适应问题约束(青色阴影),在监督方式下生成最优交互约束 uˆ。基于 vˆ0 和 uˆ,可以根据式子(2)建立新的 PDE 方程,然后使用具有时间常数的 PDE 求解器(灰色阴影)循环地寻求未来的演化状态轨迹 v1 到 vT。最终,通过在 vT 之上的全连接层的映射函数获得预测的 xˆT。我们模型的驱动力是最小化我们模型输出 xˆT 与观察目标 xT 之间的均方误差(MSE)。在梯度反向传播中使用了变化自适应矩估计(Adam)(学习率为0.001,周期为300)。
实验结果
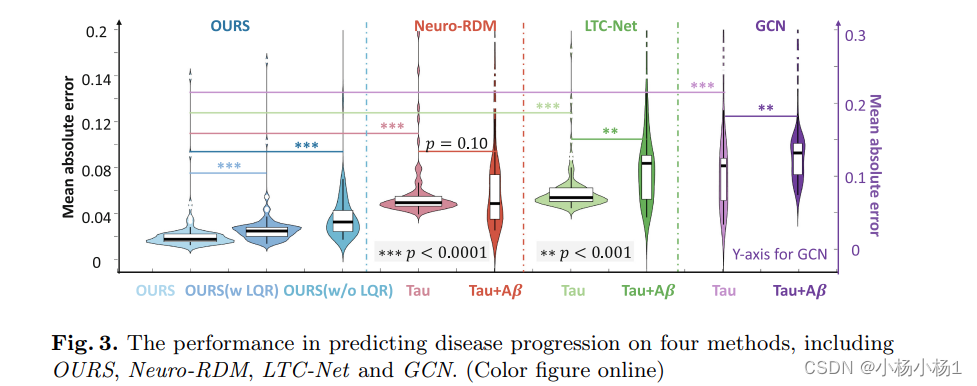
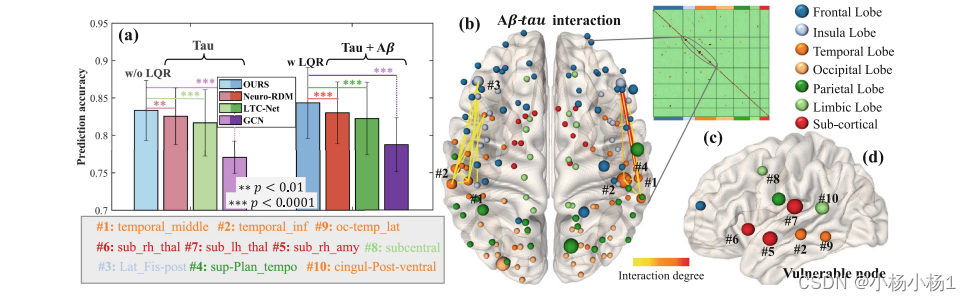
图4显示了以下内容:(a) 预测阿尔茨海默病风险的预测准确度。(b) Aβ- tau 相互作用的局部(Θ中的对角线)和远程(非对角线)相互作用的可视化。节点大小和链接带宽分别与局部和远程相互作用的强度成比例。© 交互矩阵 B。(d) 对于淀粉样蛋白沉积干预易受影响的排名靠前的关键脑区域。
















 2750
2750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











