







SwinMM: Masked Multi-view with Swin Transformers for 3D Medical Image Segmentation
摘要
最近,在大规模视觉Transformer方面取得的进展显著改进了医学图像分割的预训练模型。然而,这些方法面临着一个明显的挑战,即获取大量的预训练数据,特别是在医学领域。为了解决这一限制,研究人员提出了一种新的多视图方法,名为Masked Multiview with Swin Transformers(SwinMM),用于实现准确和高效的自监督医学图像分析。
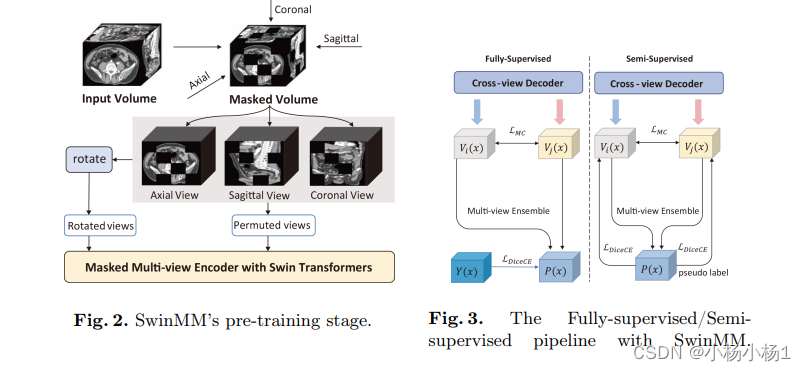
该策略利用了多视图信息的潜力,包括两个主要组成部分。在预训练阶段,他们部署了一个被mask的多视图编码器,通过一系列多样的代理任务同时训练掩蔽的多视图观测。这些任务涵盖了图像重建、旋转、对比学习,以及一种利用相互学习范式的新任务。这项新任务利用了不同视角预测之间的一致性,从3D医学数据中提取隐藏的多视图信息。在微调阶段,他们开发了一个跨视图解码器,通过交叉注意力块聚合多视图信息。与先前的最先进的自监督学习方法Swin UNETR相比,SwinMM在多个医学图像分割任务上展现出显著优势。它允许平滑地整合多视图信息,显著提升了模型的准确性和数据效率。
代码地址
方法
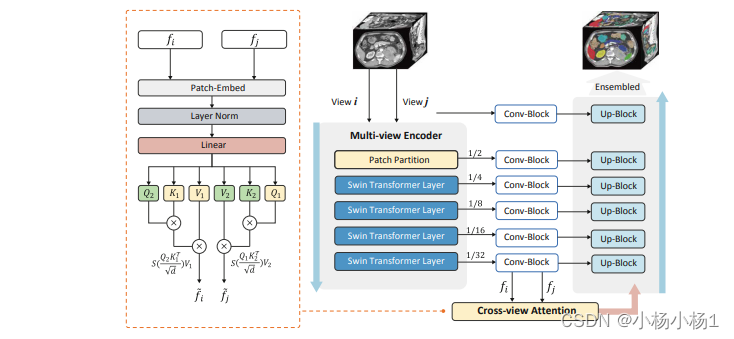
图1. SwinMM的概述。Conv-Blocks对从掩蔽的多视图编码器的不同级别获得的潜在表示进行卷积,使它们的特征大小与相应的解码器层匹配。Up-Blocks执行反卷积以上采样特征图。
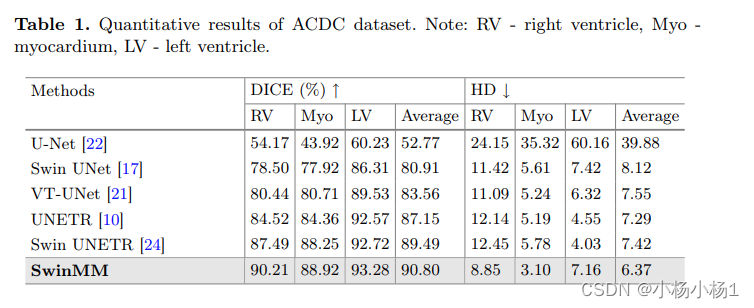
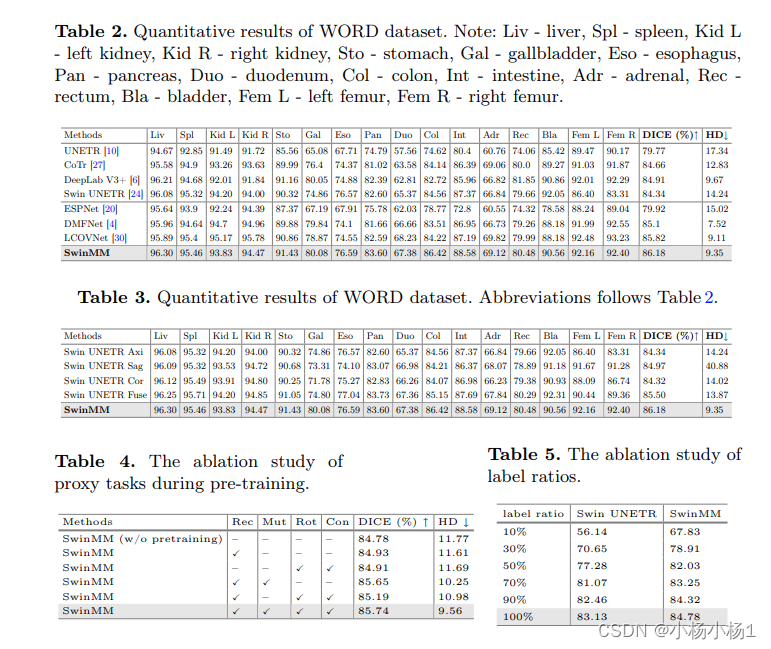
实验结果
















 144
144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











