







文章目录
Source-Free Domain Adaptation for Medical Image Segmentation via Prototype-Anchored Feature Alignment and Contrastive Learning
摘要
无监督域适应(UDA)因其能够将从有标记的源域中学习到的知识迁移到无标记的目标域而备受关注。然而,典型的UDA方法需要同时访问源域和目标域的数据,这在源数据由于隐私问题而不可用的医学场景中受到很大限制。为了解决无源数据问题,我们提出了一种新颖的两阶段无源域适应(SFDA)框架,用于医学图像分割。在域适应过程中,只能使用经过良好训练的源分割模型和未标记的目标数据。
方法
- 原型锚定特征对齐阶段
首先利用预训练的像素级分类器的权重作为源原型,这些原型保留了源特征的信息。
然后引入双向传输,通过最小化预期成本将目标特征与类原型对齐。
- 对比学习阶段
在此基础上,进一步设计了对比学习阶段,以利用那些预测不可靠的像素,从而实现更紧凑的目标特征分布。
代码地址
方法

图1展示了在无源数据域适应过程中,不同阶段目标特征分布的可视化效果和不可靠像素的类别概率分布。
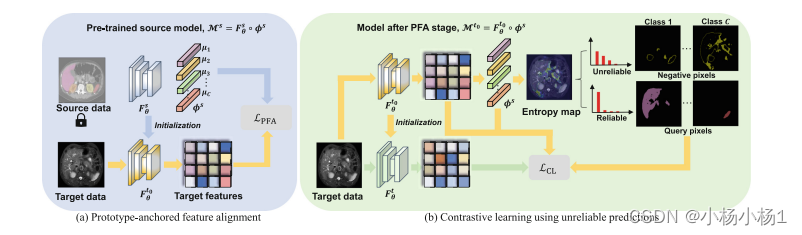
图2展示了所提出的两阶段无源域适应(SFDA)框架的概览。
-
(a) 第一个阶段:原型锚定特征对齐(PFA)
- 固定分类器φs,并使用其权重进行原型锚定特征对齐。
- 在这个阶段,目标是将目标域的特征对齐到源域的原型,以便保持源域特征的信息。
-
(b) 随后的对比学习(CL)阶段
- 给定一个目标图像,首先使用Mt0进行预测,并根据预测的可靠性(熵)将像素分为查询像素和负像素。
- 查询像素的特征来自Ftθ(查询样本),负像素的特征来自Ft0θ(负样本)。
- 在最小化对比学习损失LCL时,这种方法利用查询和负样本的特征进行进一步优化。
这个两阶段框架旨在通过首先对齐特征,然后利用对比学习进一步优化特征表示,从而在无源数据的情况下实现有效的域适应。
正样本原型对于同一类别的所有查询像素是相同的
负样本。对于类别c的查询样本,其合格的负样本应满足以下条件:1) 不可靠;2) 高概率不属于类别c。
实验结果

















 8565
8565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











