








import torch
torch.manual_seed(0)
print(torch.randn(1, 2))
print(torch.randn(1, 2))
print("======================") # torch.manual_seed()控制torch中随机数的生成,并不控制numpy和random中
torch.manual_seed(0)
print(torch.randn(1, 2))
print(torch.randn(1, 2))

然后就有一个好玩的事情发生了
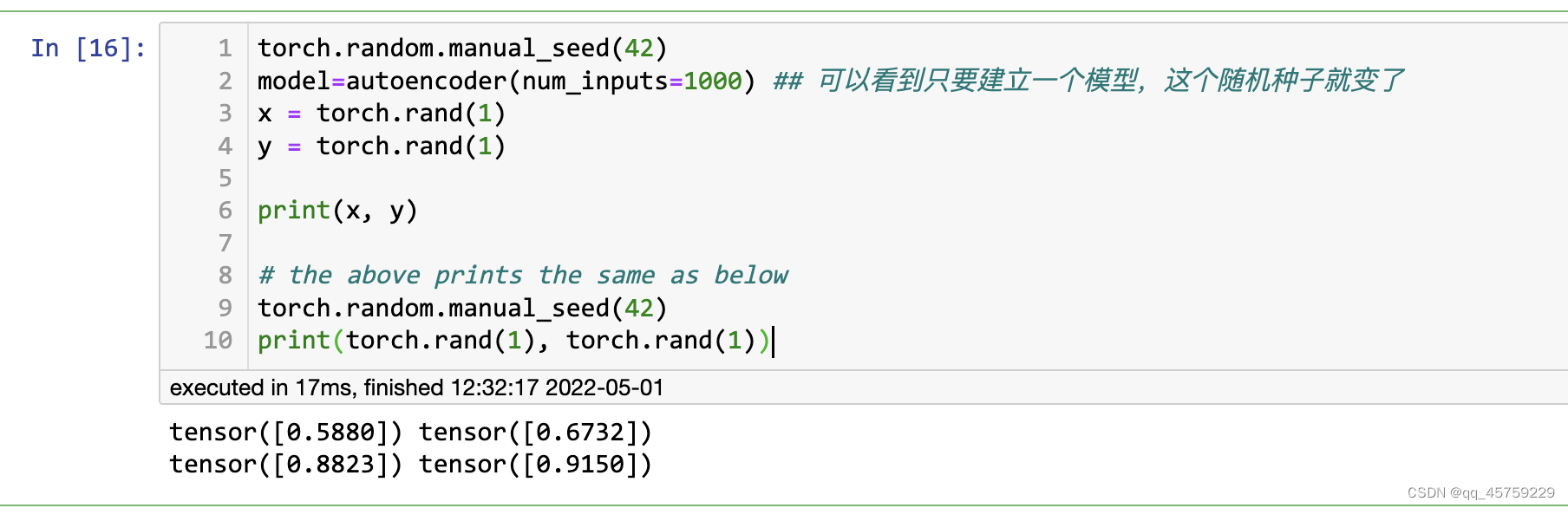
可以看到,我仅仅多设置了一个模型,导致这个随机种子不同了,这个原因到底在哪呢? 我之前的测试代码在这
import torch.nn as nn
### 这里是最简单的simple autoencoder
def init_weights(m):
""" initialize weights of fully connected layer
"""
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
# Encoder
class Encoder(nn.Module):
def __init__(self, num_inputs):
super(Encoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(num_inputs, 64),
nn.ReLU(),
nn.Linear(64,32))
self.encoder.apply(init_weights)
def forward(self, x):
x = self.encoder(x)
return x
# Decoder
class Decoder(nn.Module):
def __init__(self, num_inputs):
super(Decoder, self).__init__()
self.decoder = nn.Sequential(
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, num_inputs),
nn.ReLU())
self.decoder.apply(init_weights)
def forward(self, x):
x = self.decoder(x)
return x
# Autoencoder
class autoencoder(nn.Module):
def __init__(self, num_inputs):
super(autoencoder, self).__init__()
self.encoder = Encoder(num_inputs)
self.decoder = Decoder(num_inputs)
def forward(self, x):
code = self.encoder(x)
x = self.decoder(code)
return code, x
不建立autoencoder,看dataloader的数据,第一次运行
from torch.utils.data import TensorDataset,DataLoader
import torch
from sklearn.datasets import load_iris
import random
import os
import numpy as np
def seed_torch(seed=42):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.badatahmark = False
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.enabled = False
seed_torch(1)
X,y=load_iris(return_X_y=True)
myset=TensorDataset(torch.FloatTensor(X),torch.FloatTensor(y))
myloader=DataLoader(myset,batch_size=10,shuffle=True,num_workers=0)
for idx, (X,y) in enumerate(myloader):
print(X)
print(y)
break
print("=============================================================================================")
#model=autoencoder(1000)
for idx, (X,y) in enumerate(myloader):
print(X)
print(y)
break
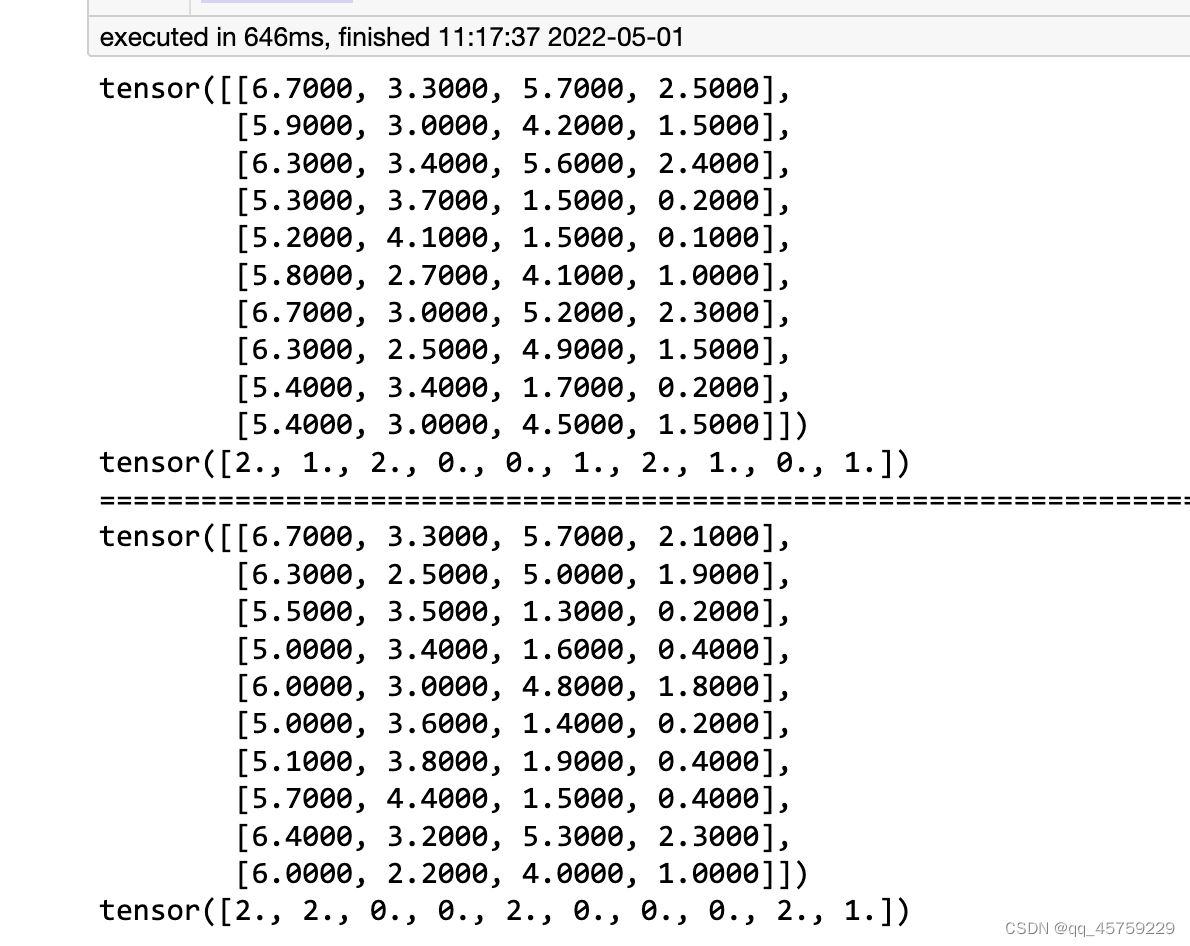 当再次执行这个代码,结果还是固定的
当再次执行这个代码,结果还是固定的
不建立autoencoder,看dataloader的数据,第二次运行
from torch.utils.data import TensorDataset,DataLoader
import torch
from sklearn.datasets import load_iris
import random
import os
import numpy as np
def seed_torch(seed=42):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.badatahmark = False
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.enabled = False
seed_torch(1)
X,y=load_iris(return_X_y=True)
myset=TensorDataset(torch.FloatTensor(X),torch.FloatTensor(y))
myloader=DataLoader(myset,batch_size=10,shuffle=True,num_workers=0)
for idx, (X,y) in enumerate(myloader):
print(X)
print(y)
break
print("=============================================================================================")
#model=autoencoder(1000)
for idx, (X,y) in enumerate(myloader):
print(X)
print(y)
break
 目前这里还没有问题,一切都如所料
目前这里还没有问题,一切都如所料
建立autoencoder,看dataloader的数据,第一次运行
from torch.utils.data import TensorDataset,DataLoader
import torch
from sklearn.datasets import load_iris
import random
import os
import numpy as np
def seed_torch(seed=42):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.badatahmark = False
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.enabled = False
seed_torch(1)
X,y=load_iris(return_X_y=True)
myset=TensorDataset(torch.FloatTensor(X),torch.FloatTensor(y))
myloader=DataLoader(myset,batch_size=10,shuffle=True,num_workers=0)
for idx, (X,y) in enumerate(myloader):
print(X)
print(y)
break
print("=============================================================================================")
model=autoencoder(1000)
for idx, (X,y) in enumerate(myloader):
print(X)
print(y)
break
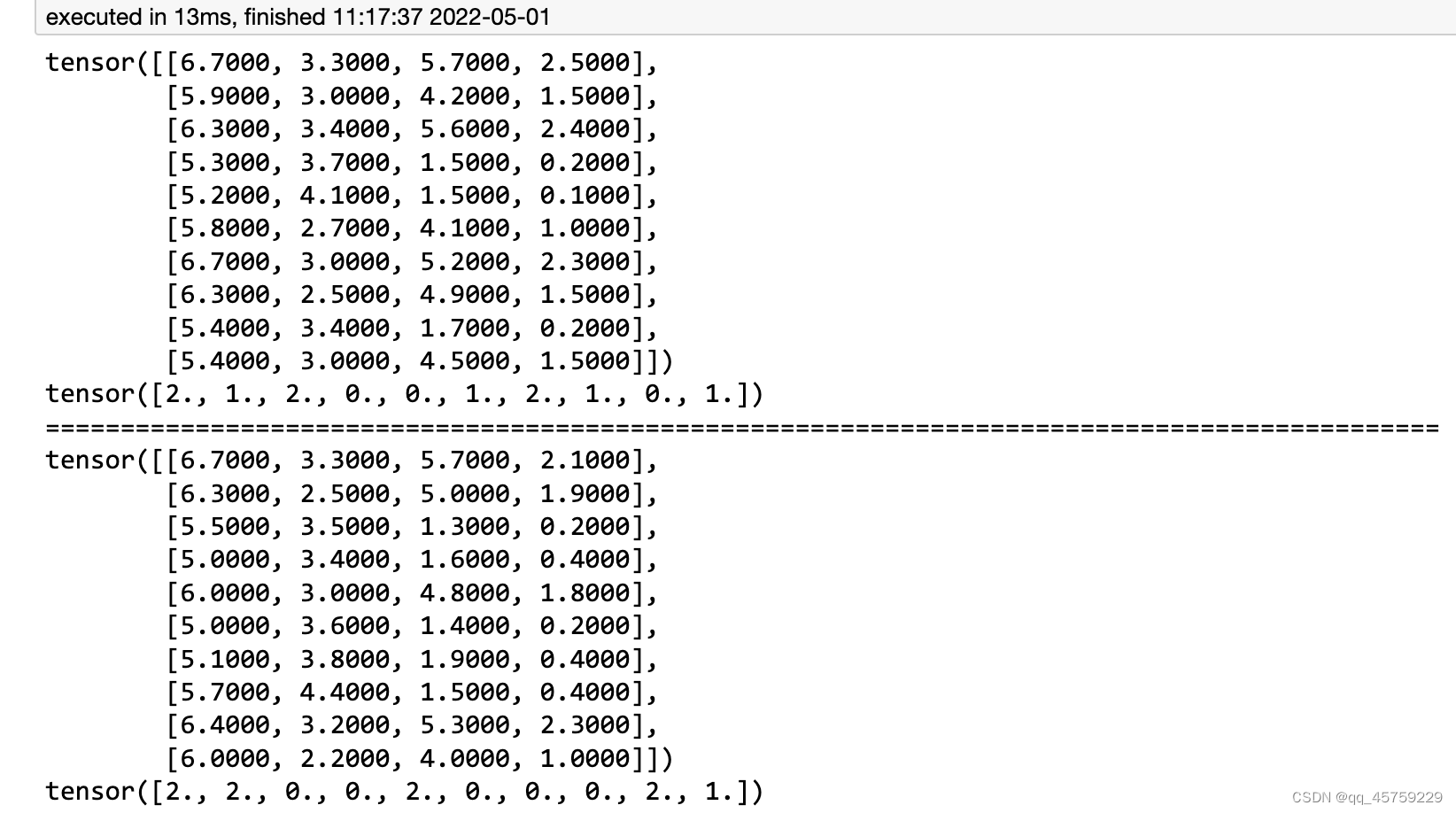
这个时候,结果如下
 可以看到,这个时候就不对劲了,我加入了一个autoencoder的模型,可以看到,之后生成的dataloader就开始变化了,不再是以前的顺序了
可以看到,这个时候就不对劲了,我加入了一个autoencoder的模型,可以看到,之后生成的dataloader就开始变化了,不再是以前的顺序了
建立autoencoder,看dataloader的数据,第二次运行
from torch.utils.data import TensorDataset,DataLoader
import torch
from sklearn.datasets import load_iris
import random
import os
import numpy as np
def seed_torch(seed=42):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.badatahmark = False
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.enabled = False
seed_torch(1)
X,y=load_iris(return_X_y=True)
myset=TensorDataset(torch.FloatTensor(X),torch.FloatTensor(y))
myloader=DataLoader(myset,batch_size=10,shuffle=True,num_workers=0)
for idx, (X,y) in enumerate(myloader):
print(X)
print(y)
break
print("=============================================================================================")
model=autoencoder(1000)
#torch.manual_seed("1")
for idx, (X,y) in enumerate(myloader):
print(X)
print(y)
break
for idx, (X,y) in enumerate(myloader):
print(X)
print(y)
break
 虽然这个结果与加入autoencoder后第一次运行的结果相同,但是这个结果还是与没有加入autoencoder前的生成数据不同了
虽然这个结果与加入autoencoder后第一次运行的结果相同,但是这个结果还是与没有加入autoencoder前的生成数据不同了
问题所在
你可以理解 torch.manual_seed()只能用一次,你最开始设置的随机种子在没有加入模型前测试中,作用在了dataloader上,而加入模型后,你的随机种子首先作用于设置模型的权重,然后再是dataloader,这个顺序也就变了,所以要想获得建立模型后,还与之前一样的dataloader的抽样结果,就在dataloaer之前 重新设置torch.manual_seed()
from torch.utils.data import TensorDataset,DataLoader
import torch
from sklearn.datasets import load_iris
import random
import os
import numpy as np
def seed_torch(seed=42):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
torch.backends.cudnn.badatahmark = False
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.enabled = False
seed_torch(1)
X,y=load_iris(return_X_y=True)
myset=TensorDataset(torch.FloatTensor(X),torch.FloatTensor(y))
myloader=DataLoader(myset,batch_size=10,shuffle=True,num_workers=0)
# for idx, (X,y) in enumerate(myloader):
# print(X)
# print(y)
# break
print("=============================================================================================")
model=autoencoder(1000)
torch.manual_seed("1")
for idx, (X,y) in enumerate(myloader):
print(X)
print(y)
break
for idx, (X,y) in enumerate(myloader):
print(X)
print(y)
break

可以看到这个结果与之前没有加入autoencoder的结果是一致的,是不是很神奇















 2361
2361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









