







与公众号同步更新,详细内容及相关ipynb文件在公众号中,公众号:AI入门小白
文章目录
模型学习的最优化算法
逻辑斯谛回归模型、最大熵模型学习归结为以似然函数为目标函数的最优化问题,通常通过迭代算法求解。从最优化的观点看,这时的目标函数具有很好的性质。它是光滑的凸函数,因此多种最优化的方法都适用,保证能找到全局最优解。常用的方法有改进的迭代尺度法、梯度下降法、牛顿法或拟牛顿法。牛顿法或拟牛顿法一般收敛速度更快。
下面介绍基于改进的迭代尺度法与拟牛顿法的最大熵模型学习算法。
改进的迭代尺度法
改进的迭代尺度法(improved iterative scaling, IIS) 是一种最大熵模型学习的最优化算法。
己知最大熵模型为
P
ω
(
y
∣
x
)
=
1
Z
ω
(
x
)
e
x
p
(
∑
i
=
1
n
ω
i
f
i
(
x
,
y
)
)
P_{\omega}(y|x) = \frac{1}{Z_\omega (x)} exp\Bigg(\sum_{i=1}^n \omega_i f_i (x,y)\Bigg)
Pω(y∣x)=Zω(x)1exp(i=1∑nωifi(x,y))
其中,
Z
ω
(
x
)
=
∑
y
e
x
p
(
∑
i
=
1
n
ω
i
f
i
(
x
,
y
)
)
Z_\omega(x) = \sum_y exp\Bigg(\sum_{i=1}^n \omega_i f_i (x,y) \Bigg)
Zω(x)=y∑exp(i=1∑nωifi(x,y))
对数似然函数为
L
(
ω
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
ω
i
f
i
(
x
,
y
)
−
∑
x
P
~
(
x
)
log
Z
ω
(
x
)
L(\omega) = \sum_{x,y} \tilde{P}(x,y) \sum_{i=1}^n \omega_i f_i (x,y) - \sum_x \tilde{P}(x) \log Z_\omega(x)
L(ω)=x,y∑P~(x,y)i=1∑nωifi(x,y)−x∑P~(x)logZω(x)
目标是通过极大似然估计学习模型参数, 即求对数似然函数的极大值
ω
^
\hat{\omega}
ω^。
IIS的想法是:假设最大熵模型当前的参数向量是 ω = ( ω 1 , ω 2 , ⋯ , ω n ) T \omega = (\omega_1,\omega_2,\cdots,\omega_n)^T ω=(ω1,ω2,⋯,ωn)T,我们希望找到一个新的参数向量 ω + δ = ( ω 1 + δ 1 , ω 2 + δ 2 , ⋯ , ω n + δ n ) T \omega + \delta = (\omega_1 + \delta_1, \omega_2 + \delta_2, \cdots, \omega_n + \delta_n)^T ω+δ=(ω1+δ1,ω2+δ2,⋯,ωn+δn)T,使得模型的对数似然函数值增大。如果能有这样一种参数向量更新的方法 τ : ω → ω + δ \tau: \omega \rightarrow \omega + \delta τ:ω→ω+δ,那么就可以重复使用这一方法,直至找到对数似然函数的最大值。
对于给定的经验分布
P
~
(
x
,
y
)
\tilde{P}(x,y)
P~(x,y),模型参数从
ω
\omega
ω到
ω
+
δ
\omega + \delta
ω+δ,对数似然函数的改变量是
L
(
ω
+
δ
)
−
L
(
ω
)
=
∑
x
,
y
P
~
(
x
,
y
)
log
P
ω
+
δ
(
y
∣
x
)
−
∑
x
,
y
P
~
(
x
,
y
)
log
P
ω
(
y
∣
x
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
−
∑
x
P
~
(
x
)
log
Z
ω
+
δ
(
x
)
Z
ω
(
x
)
\begin{aligned} L(\omega + \delta) - L(\omega) &= \sum_{x,y} \tilde{P}(x,y) \log P_{\omega + \delta}(y|x) - \sum_{x,y} \tilde{P}(x,y)\log P_\omega(y|x) \\ &= \sum_{x,y} \tilde{P}(x,y) \sum_{i=1}^n \delta_i f_i (x,y) - \sum_x \tilde{P}(x) \log \frac{Z_{\omega+\delta}(x)}{Z_\omega (x)} \end{aligned}
L(ω+δ)−L(ω)=x,y∑P~(x,y)logPω+δ(y∣x)−x,y∑P~(x,y)logPω(y∣x)=x,y∑P~(x,y)i=1∑nδifi(x,y)−x∑P~(x)logZω(x)Zω+δ(x)
利用不等式
−
log
α
≥
1
−
α
,
α
>
0
-\log \alpha \geq 1 - \alpha, \quad \alpha > 0
−logα≥1−α,α>0
建立对数似然函数改变量的下界:
L
(
ω
+
δ
)
−
L
(
ω
)
≥
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
Z
ω
+
δ
(
x
)
Z
ω
(
x
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
P
ω
(
y
∣
x
)
e
x
p
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
\begin{aligned} L(\omega + \delta) - L(\omega) &\geq \sum_{x,y}\tilde{P}(x,y) \sum_{i=1}^n \delta_i f_i(x,y) + 1 - \sum_x \tilde{P}(x) \frac{Z_{\omega + \delta}(x)}{Z_\omega (x)} \\ &= \sum_{x,y}\tilde{P}(x,y) \sum_{i=1}^n \delta_i f_i(x,y) + 1 - \sum_x \tilde{P}(x) \sum_y P_\omega (y|x) exp\sum_{i=1}^n \delta_i f_i (x,y) \end{aligned}
L(ω+δ)−L(ω)≥x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)Zω(x)Zω+δ(x)=x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)y∑Pω(y∣x)expi=1∑nδifi(x,y)
将右端记为
A
(
δ
∣
ω
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
P
ω
(
y
∣
x
)
e
x
p
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
A(\delta | \omega) = \sum_{x,y} \tilde{P}(x,y) \sum_{i=1}^n \delta_i f_i (x,y) + 1 - \sum_x \tilde{P}(x) \sum_y P_\omega (y|x) exp\sum_{i=1}^n \delta_i f_i (x,y)
A(δ∣ω)=x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)y∑Pω(y∣x)expi=1∑nδifi(x,y)
于是有
L
(
ω
+
δ
)
−
L
(
ω
)
≥
A
(
δ
∣
ω
)
L(\omega + \delta) - L(\omega) \geq A(\delta|\omega)
L(ω+δ)−L(ω)≥A(δ∣ω)
即
A
(
δ
∣
ω
)
A(\delta|\omega)
A(δ∣ω)是对数似然函数改变量的一个下界。
如果能找到适当的 δ \delta δ使下界 A ( δ ∣ ω ) A(\delta|\omega) A(δ∣ω)提高,那么对数似然函数也会提高。然而,函数 A ( δ ∣ ω ) A(\delta|\omega) A(δ∣ω)中的 δ \delta δ是一个向量,含有多个变量,不易同时优化。IIS试图一次只优化其中一个变量 δ i \delta_i δi,而固定其他变量 δ j , i ≠ j \delta_j, i \neq j δj,i=j。
为达到这一目的,IIS进一步降低下界
A
(
δ
∣
ω
)
A(\delta|\omega)
A(δ∣ω)。具体地,IIS引进一个量
f
#
(
x
,
y
)
f^{\#}(x,y)
f#(x,y),
f
#
(
x
,
y
)
=
∑
i
f
i
(
x
,
y
)
f^\# (x,y) = \sum_i f_i(x,y)
f#(x,y)=i∑fi(x,y)
因为
f
i
f_i
fi是二值函数,故
f
#
(
x
,
y
)
f^\#(x,y)
f#(x,y)表示所有特征在
(
x
,
y
)
(x,y)
(x,y)出现的次数。这样,
A
(
δ
∣
ω
)
A(\delta|\omega)
A(δ∣ω)可以改写为
A
(
δ
∣
ω
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
P
ω
(
y
∣
x
)
e
x
p
(
f
#
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
f
#
(
x
,
y
)
)
(6.30)
\begin{aligned} A(\delta|\omega) &= \sum_{x,y} \tilde{P}(x,y) \sum_{i=1}^n \delta_i f_i(x,y) + 1 - \\ &\sum_x \tilde{P}(x) \sum_y P_\omega(y|x) exp\Bigg(f^\# (x,y) \sum_{i=1}^n \frac{\delta_i f_i(x,y)}{f^\# (x,y)} \Bigg) \end{aligned} \quad \tag{6.30}
A(δ∣ω)=x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)y∑Pω(y∣x)exp(f#(x,y)i=1∑nf#(x,y)δifi(x,y))(6.30)
利用指数函数的凸性以及对任意
i
i
i,有
f
i
(
x
,
y
)
f
#
(
x
,
y
)
≥
0
\frac{f_i(x,y)}{f^\#(x,y)} \geq 0
f#(x,y)fi(x,y)≥0且
∑
i
=
1
n
f
i
(
x
,
y
)
f
#
(
x
,
y
)
=
1
\sum_{i=1}^n \frac{f_i (x,y)}{f^\# (x,y)} = 1
∑i=1nf#(x,y)fi(x,y)=1这一事实,根据Jensen不等式,得到
e
x
p
(
∑
i
=
1
n
f
i
(
x
,
y
)
f
#
(
x
,
y
)
δ
i
f
#
(
x
,
y
)
)
≤
∑
i
=
1
n
f
i
(
x
,
y
)
f
#
(
x
,
y
)
e
x
p
(
δ
i
f
#
(
x
,
y
)
)
exp\Bigg(\sum_{i=1}^n \frac{f_i(x,y)}{f^\#(x,y)}\delta_if^\#(x,y) \Bigg) \leq \sum_{i=1}^n \frac{f_i(x,y)}{f^\# (x,y)} exp(\delta_if^\#(x,y))
exp(i=1∑nf#(x,y)fi(x,y)δif#(x,y))≤i=1∑nf#(x,y)fi(x,y)exp(δif#(x,y))
于是式(6.30)可改写为
A
(
δ
∣
ω
)
≥
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
P
ω
(
y
∣
x
)
∑
i
=
1
n
(
f
i
(
x
,
y
)
f
#
(
x
,
y
)
)
e
x
p
(
δ
i
f
#
(
x
,
y
)
)
(6.31)
\begin{aligned} A(\delta|\omega) &\geq \sum_{x,y} \tilde{P}(x,y) \sum_{i=1}^n \delta_i f_i (x,y) + 1 - \\ &\sum_x \tilde{P}(x)\sum_y P_\omega(y|x) \sum_{i=1}^n \Bigg(\frac{f_i(x,y)}{f^\#(x,y)} \Bigg) exp(\delta_i f^\#(x,y)) \end{aligned} \quad \tag{6.31}
A(δ∣ω)≥x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)y∑Pω(y∣x)i=1∑n(f#(x,y)fi(x,y))exp(δif#(x,y))(6.31)
记不等式(6.31)右端为
B
(
δ
∣
ω
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
P
ω
(
y
∣
x
)
∑
i
=
1
n
(
f
i
(
x
,
y
)
f
#
(
x
,
y
)
)
e
x
p
(
δ
i
f
#
(
x
,
y
)
)
B(\delta|\omega) = \sum_{x,y}\tilde{P}(x,y) \sum_{i=1}^n \delta_i f_i (x,y) + 1 - \sum_x \tilde{P}(x) \sum_y P_\omega (y|x) \sum_{i=1}^n \Bigg(\frac{f_i(x,y)}{f^\# (x,y)}\Bigg) exp (\delta_i f^\#(x,y))
B(δ∣ω)=x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)y∑Pω(y∣x)i=1∑n(f#(x,y)fi(x,y))exp(δif#(x,y))
于是得到
L
(
ω
+
δ
)
−
L
(
ω
)
≥
B
(
δ
∣
ω
)
L(\omega + \delta) - L(\omega) \geq B(\delta | \omega)
L(ω+δ)−L(ω)≥B(δ∣ω)
这里,
B
(
δ
∣
ω
)
B(\delta|\omega)
B(δ∣ω)是对数似然函数改变量的一个新的(相对不紧的)下界。
求
B
(
δ
∣
ω
)
B(\delta|\omega)
B(δ∣ω)对
δ
i
\delta_i
δi的偏导数:
∂
B
(
δ
∣
ω
)
∂
δ
i
=
∑
x
,
y
P
~
(
x
,
y
)
f
i
(
x
,
y
)
−
∑
x
P
~
(
x
)
∑
y
P
ω
(
y
∣
x
)
f
i
(
x
,
y
)
e
x
p
(
δ
i
f
#
(
x
,
y
)
)
(6.32)
\frac{\partial B(\delta|\omega)}{\partial \delta_i} = \sum_{x,y} \tilde{P}(x,y)f_i(x,y) - \sum_x \tilde{P}(x) \sum_y P_\omega(y|x)f_i(x,y) exp(\delta_if^\#(x,y)) \quad \tag{6.32}
∂δi∂B(δ∣ω)=x,y∑P~(x,y)fi(x,y)−x∑P~(x)y∑Pω(y∣x)fi(x,y)exp(δif#(x,y))(6.32)
在式(6.32)里,除
δ
i
\delta_i
δi外不含任何其他变量。令偏导数为0得到
∑
x
,
y
P
~
(
x
)
P
ω
(
y
∣
x
)
f
i
(
x
,
y
)
e
x
p
(
δ
i
f
#
(
x
,
y
)
)
=
E
P
~
(
f
i
)
(6.33)
\sum_{x,y} \tilde{P}(x)P_\omega(y|x)f_i(x,y) exp(\delta_if^\#(x,y)) = E_{\tilde{P}}(f_i) \quad \tag{6.33}
x,y∑P~(x)Pω(y∣x)fi(x,y)exp(δif#(x,y))=EP~(fi)(6.33)
于是,依次对
δ
i
\delta_i
δi求解方程(6.33)可以求出
δ
\delta
δ。
这就给出了一种求 ω \omega ω的最优解的迭代算法,即改进的迭代尺度算法IIS。
算法6.1(改进的迭代尺度算法IIS)
输入:特征函数
f
1
,
f
2
,
⋯
,
f
n
f_1,f_2,\cdots,f_n
f1,f2,⋯,fn;经验分布
P
~
(
X
,
Y
)
\tilde{P}(X,Y)
P~(X,Y),模型
P
ω
(
y
∣
x
)
P_\omega(y|x)
Pω(y∣x);
输出:最优参数值
ω
i
∗
\omega_i^*
ωi∗;最优模型
P
ω
∗
P_{\omega^*}
Pω∗。
(1)对所有
i
∈
{
1
,
2
,
⋯
,
n
}
i \in \{1,2,\cdots,n\}
i∈{1,2,⋯,n},取初值
ω
i
=
0
\omega_i = 0
ωi=0。
(2)对每一
i
∈
{
1
,
2
,
⋯
,
n
}
i \in \{1,2,\cdots,n \}
i∈{1,2,⋯,n}
- (a)令
δ
i
\delta_i
δi是方程
∑ x , y P ~ ( x ) P ( y ∣ x ) f i ( x , y ) e x p ( δ i f # ( x , y ) ) = E P ~ ( f i ) \sum_{x,y}\tilde{P}(x)P(y|x)f_i(x,y) exp(\delta_if^\#(x,y)) = E_{\tilde{P}}(f_i) x,y∑P~(x)P(y∣x)fi(x,y)exp(δif#(x,y))=EP~(fi)
的解,这里,
f # ( x , y ) = ∑ i = 1 n f i ( x , y ) f^\# (x,y) = \sum_{i=1}^n f_i (x,y) f#(x,y)=i=1∑nfi(x,y) - (b)更新 ω i \omega_i ωi值: ω i ← ω i + δ i \omega_i \leftarrow \omega_i + \delta_i ωi←ωi+δi。
(3)如果不是所有 ω i \omega_i ωi都收敛,重复步(2)。
这一算法关键的一步是(a),即求解方程(6.33)中的
δ
i
\delta_i
δi。如果
f
#
(
x
,
y
)
f^\#(x,y)
f#(x,y)是常数,即对任何
x
,
y
x,y
x,y,有
f
#
(
x
,
y
)
=
M
f^\#(x,y) = M
f#(x,y)=M,那么
δ
i
\delta_i
δi可以显式地表示成
δ
i
=
1
M
log
E
P
~
(
f
i
)
E
P
(
f
i
)
(6.34)
\delta_i = \frac{1}{M} \log \frac{E_{\tilde{P}}(f_i)}{E_P(f_i)} \quad \tag{6.34}
δi=M1logEP(fi)EP~(fi)(6.34)
如果
f
#
(
x
,
y
)
f^\#(x,y)
f#(x,y)不是常数,那么必须通过数值计算求
δ
i
\delta_i
δi。简单有效的方法是牛顿法。
以
g
(
δ
i
)
=
0
g(\delta_i) = 0
g(δi)=0表示方程(6.33),牛顿法通过迭代求得
δ
i
∗
\delta_i^*
δi∗,使得
g
(
δ
i
∗
)
=
0
g(\delta_i^*) = 0
g(δi∗)=0。迭代公式是
δ
i
(
k
+
1
)
=
δ
i
(
k
)
−
g
(
δ
i
(
k
)
)
g
′
(
δ
i
(
k
)
)
(6.35)
\delta_i^{(k+1)} = \delta_i^{(k)} - \frac{g(\delta_i^{(k)})}{g'(\delta_i^{(k)})} \quad \tag{6.35}
δi(k+1)=δi(k)−g′(δi(k))g(δi(k))(6.35)
只要适当选取初始值
δ
i
(
0
)
\delta_i^{(0)}
δi(0),由于
δ
i
\delta_i
δi的方程(6.33)有单根,因此牛顿法恒收敛,而且收敛速度很快。
拟牛顿法
最大熵模型学习还可以应用牛顿法或拟牛顿法。
对于最大熵模型而言,
P
ω
(
y
∣
x
)
=
e
x
p
(
∑
i
=
1
n
ω
i
f
i
(
x
,
y
)
)
∑
y
e
x
p
(
∑
i
=
1
n
ω
i
f
i
(
x
,
y
)
)
P_\omega(y|x) = \frac{exp\Bigg(\sum_{i=1}^n \omega_i f_i (x,y) \Bigg)}{\sum_y exp\Bigg(\sum_{i=1}^n \omega_i f_i (x,y) \Bigg)}
Pω(y∣x)=∑yexp(∑i=1nωifi(x,y))exp(∑i=1nωifi(x,y))
目标函数:
min
ω
∈
R
n
f
(
ω
)
=
∑
x
P
~
(
x
)
log
∑
y
e
x
p
(
∑
i
=
1
n
ω
i
f
i
(
x
,
y
)
)
−
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
ω
i
f
i
(
x
,
y
)
\min_{\omega \in R^n} \quad f(\omega) = \sum_x \tilde{P}(x) \log \sum_y exp\Bigg(\sum_{i=1}^n \omega_i f_i (x,y) \Bigg) - \sum_{x,y} \tilde{P}(x,y) \sum_{i=1}^n \omega_i f_i (x,y)
ω∈Rnminf(ω)=x∑P~(x)logy∑exp(i=1∑nωifi(x,y))−x,y∑P~(x,y)i=1∑nωifi(x,y)
梯度:
g
(
ω
)
=
(
∂
f
(
ω
)
∂
ω
1
,
∂
f
(
ω
)
∂
ω
2
,
⋯
,
∂
f
(
ω
)
∂
ω
n
)
T
g(\omega) = \Bigg(\frac{\partial f(\omega)}{\partial \omega_1},\frac{\partial f(\omega)}{\partial \omega_2},\cdots, \frac{\partial f(\omega)}{\partial \omega_n} \Bigg)^T
g(ω)=(∂ω1∂f(ω),∂ω2∂f(ω),⋯,∂ωn∂f(ω))T
其中
∂
f
(
ω
)
∂
ω
i
=
∑
x
,
y
P
~
(
x
)
P
ω
(
y
∣
x
)
f
i
(
x
,
y
)
−
E
P
~
(
f
i
)
,
i
=
1
,
2
,
⋯
,
n
\frac{\partial f(\omega)}{\partial \omega_i} = \sum_{x,y} \tilde{P}(x) P_\omega(y|x) f_i(x,y) - E_{\tilde{P}}(f_i), \quad i=1,2,\cdots,n
∂ωi∂f(ω)=x,y∑P~(x)Pω(y∣x)fi(x,y)−EP~(fi),i=1,2,⋯,n
相应的拟牛顿法BFGS 算法如下。
算法6.2(最大熵模型学习的BFGS 算法)
输入:特征函数
f
1
,
f
2
,
⋯
,
f
n
f_1, f_2, \cdots ,f_n
f1,f2,⋯,fn;经验分布
P
~
(
x
,
y
)
\tilde{P}(x,y)
P~(x,y),目标函数
f
(
ω
)
f(\omega)
f(ω),梯度
g
(
ω
)
=
∇
f
(
ω
)
g(\omega) = \nabla f(\omega)
g(ω)=∇f(ω),精度要求
ε
\varepsilon
ε;
输出:最优参数值
ω
∗
\omega^*
ω∗;最优模型
P
ω
∗
(
y
∣
x
)
P_{\omega^*}(y|x)
Pω∗(y∣x)。
(1)选定初始点
ω
(
0
)
\omega^{(0)}
ω(0),取
B
0
B_0
B0为正定对称矩阵,置
k
=
0
k = 0
k=0;
(2)计算
g
k
=
g
(
ω
(
k
)
)
g_k = g(\omega^{(k)})
gk=g(ω(k))。若
∥
g
k
∥
<
ε
\lVert g_k \rVert < \varepsilon
∥gk∥<ε,则停止计算, 得
ω
∗
=
ω
(
k
)
\omega^* = \omega^{(k)}
ω∗=ω(k);否则转(3);
(3)由
B
k
p
k
=
−
g
k
B_k p_k = -g_k
Bkpk=−gk求出
p
k
p_k
pk;
(4)一维搜索:求
λ
k
\lambda_k
λk使得
f
(
ω
(
k
)
+
λ
k
p
k
)
=
min
λ
≥
0
f
(
ω
(
k
)
+
λ
p
k
)
f(\omega^{(k)} + \lambda_k p_k) = \min_{\lambda \geq 0} f(\omega^{(k)} + \lambda p_k)
f(ω(k)+λkpk)=λ≥0minf(ω(k)+λpk)
(5)置
ω
(
k
+
1
)
=
ω
(
k
)
+
λ
k
p
k
\omega^{(k+1)} = \omega^{(k)} + \lambda_k p_k
ω(k+1)=ω(k)+λkpk;
(6)计算
g
k
+
1
=
g
(
ω
(
k
+
1
)
)
g_{k+1} = g(\omega^{(k+1)})
gk+1=g(ω(k+1)),若
∥
g
k
+
1
∥
<
ε
\lVert g_{k+1} \rVert < \varepsilon
∥gk+1∥<ε,则停止计算,得
ω
∗
=
ω
(
k
+
1
)
\omega^* = \omega^{(k+1)}
ω∗=ω(k+1);否则,按下式求出
B
k
+
1
B_{k+1}
Bk+1:
B
k
+
1
=
B
k
+
y
k
y
k
T
y
k
T
δ
k
−
B
k
δ
k
δ
k
T
B
k
δ
k
T
B
k
δ
k
B_{k+1} = B_k + \frac{y_k y_k^T}{y_k^T \delta_k} - \frac{B_k \delta_k \delta_k^T B_k}{\delta_k^T B_k \delta_k}
Bk+1=Bk+ykTδkykykT−δkTBkδkBkδkδkTBk
其中,
y
k
=
g
k
+
1
−
g
k
,
δ
k
=
ω
(
k
+
1
)
−
ω
(
k
)
y_k = g_{k+1} - g_k, \quad \delta_k = \omega^{(k+1)} - \omega^{(k)}
yk=gk+1−gk,δk=ω(k+1)−ω(k)
(7)置
k
=
k
+
1
k = k + 1
k=k+1,转(3)。
代码部分
from math import exp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, [0,1,-1]])
# print(data)
return data[:,:2], data[:,-1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
'''
np.mat()函数用于将输入解释为矩阵。
np.matrix()函数用于从类数组对象或数据字符串返回矩阵。
np.array()函数用于创建一个数组。
'''
class LogisticReressionClassifier:
def __init__(self, max_iter=200, learning_rate=0.01):
self.max_iter = max_iter # 迭代次数
self.learning_rate = learning_rate
def sigmoid(self, x):
return 1 / (1 + exp(-x))
def data_matrix(self, X):
data_mat = []
for d in X:
data_mat.append([1.0, *d])
return data_mat
def fit(self, X, y):
# label = np.mat(y) # https://blog.csdn.net/yeler082/article/details/90342438
data_mat = self.data_matrix(X) # m*n ([1.0,X_1],[1.0,X_2],...)
self.weights = np.zeros((len(data_mat[0]), 1), dtype=np.float32)
for iter_ in range(self.max_iter):
for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights)) # sigmoid(x * w)
error = y[i] - result # 结果若不为0,则分类错误
self.weights += self.learning_rate * error * np.transpose(
[data_mat[i]]) # 更新权值 w,分类若正确,error=0,权值不变
print('LogisticRegression Model(learning_rate={},max_iter={})'.format(
self.learning_rate, self.max_iter))
#def f(self, x):
# return -(self.weights[0] + self.weights[1] * x) / self.weights[2]
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test)
for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights)
if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)
lr_clf = LogisticReressionClassifier()
lr_clf.fit(X_train, y_train)

lr_clf.score(X_test, y_test)

x_ponits = np.arange(4, 8)
y_ = -(lr_clf.weights[1] * x_ponits + lr_clf.weights[0]) / lr_clf.weights[2]
plt.plot(x_ponits, y_)
plt.tick_params(axis='x', colors='white')
plt.tick_params(axis='y', colors='white')
# lr_clf.show.graph()
plt.scatter(X[:50,0],X[:50,1], label='0')
plt.scatter(X[50:,0],X[50:,1], label='1')
plt.legend()

scikit-learn实例
sklearn.linear_model.LogisticRegression
solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
- a) liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- b) lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- c) newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- d) sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(max_iter=200) # https://blog.csdn.net/jark_/article/details/78342644
clf.fit(X_train, y_train)

clf.score(X_test, y_test)
# https://www.jianshu.com/p/6a818b53a37e
# https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html?highlight=logisticregression%20coef_
print(clf.coef_, clf.intercept_)
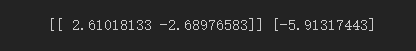
x_ponits = np.arange(4, 8)
y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]
plt.plot(x_ponits, y_)
plt.tick_params(axis='x', colors='white')
plt.tick_params(axis='y', colors='white')
plt.plot(X[:50, 0], X[:50, 1], 'bo', color='blue', label='0')
plt.plot(X[50:, 0], X[50:, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length', color='white')
plt.ylabel('sepal width', color='white')
plt.legend()

最大熵模型
import math
from copy import deepcopy
class MaxEntropy:
def __init__(self, EPS=0.005):
self._samples = []
self._Y = set() # 标签集合,相当去去重后的y
self._numXY = {} # key为(x,y),value为出现次数
self._N = 0 # 样本数
self._Ep_ = [] # 样本分布的特征期望值
self._xyID = {} # key记录(x,y),value记录id号
self._n = 0 # 特征键值(x,y)的个数
self._C = 0 # 最大特征数
self._IDxy = {} # key为(x,y),value为对应的id号
self._w = []
self._EPS = EPS # 收敛条件
self._lastw = [] # 上一次w参数值
def loadData(self, dataset):
self._samples = deepcopy(dataset)
for items in self._samples:
y = items[0]
X = items[1:]
self._Y.add(y) # 集合中y若已存在则会自动忽略
for x in X:
if (x, y) in self._numXY:
self._numXY[(x, y)] += 1
else:
self._numXY[(x, y)] = 1
self._N = len(self._samples)
self._n = len(self._numXY)
self._C = max([len(sample) - 1 for sample in self._samples])
self._w = [0] * self._n # self._n个0
self._lastw = self._w[:]
self._Ep_ = [0] * self._n
# enumerate() 函数用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标
for i, xy in enumerate(self._numXY): # 计算特征函数fi关于经验分布的期望
self._Ep_[i] = self._numXY[xy] / self._N # 出现次数 / 总数
self._xyID[xy] = i
self._IDxy[i] = xy
def _Zx(self, X): # 计算每个Z(x)值
zx = 0
for y in self._Y:
ss = 0
for x in X:
if (x, y) in self._numXY:
ss += self._w[self._xyID[(x, y)]]
zx += math.exp(ss) # 式6.23
return zx
def _model_pyx(self, y, X): # 计算每个P(y|x)
zx = self._Zx(X)
ss = 0
for x in X:
if (x, y) in self._numXY:
ss += self._w[self._xyID[(x, y)]]
pyx = math.exp(ss) / zx # 式6.22
return pyx
def _model_ep(self, index): # 计算特征函数fi关于模型的期望
x, y = self._IDxy[index]
ep = 0
for sample in self._samples:
if x not in sample:
continue
pyx = self._model_pyx(y, sample)
ep += pyx / self._N # 一共循环了x频数的次数
return ep
def _convergence(self): # 判断是否全部收敛
for last, now in zip(self._lastw, self._w):
if abs(last - now) >= self._EPS:
return False
return True
def predict(self, X): # 计算预测概率
Z = self._Zx(X)
result = {}
for y in self._Y:
ss = 0
for x in X:
if (x, y) in self._numXY:
ss += self._w[self._xyID[(x, y)]]
pyx = math.exp(ss) / Z
result[y] = pyx
return result
def train(self, maxiter=1000): # 训练数据
for loop in range(maxiter): # 最大训练次数
print("iter:%d" % loop)
self._lastw = self._w[:]
for i in range(self._n):
ep = self._model_ep(i) # 计算第i个特征的模型期望
self._w[i] += math.log(self._Ep_[i] / ep) / self._C # 更新参数,IIS算法,式6.34
print("w:", self._w)
if self._convergence(): # 判断是否收敛
break
dataset = [['no', 'sunny', 'hot', 'high', 'FALSE'],
['no', 'sunny', 'hot', 'high', 'TRUE'],
['yes', 'overcast', 'hot', 'high', 'FALSE'],
['yes', 'rainy', 'mild', 'high', 'FALSE'],
['yes', 'rainy', 'cool', 'normal', 'FALSE'],
['no', 'rainy', 'cool', 'normal', 'TRUE'],
['yes', 'overcast', 'cool', 'normal', 'TRUE'],
['no', 'sunny', 'mild', 'high', 'FALSE'],
['yes', 'sunny', 'cool', 'normal', 'FALSE'],
['yes', 'rainy', 'mild', 'normal', 'FALSE'],
['yes', 'sunny', 'mild', 'normal', 'TRUE'],
['yes', 'overcast', 'mild', 'high', 'TRUE'],
['yes', 'overcast', 'hot', 'normal', 'FALSE'],
['no', 'rainy', 'mild', 'high', 'TRUE']]
maxent = MaxEntropy()
x = ['overcast', 'mild', 'high', 'FALSE']
maxent.loadData(dataset)
maxent.train()

print('predict:', maxent.predict(x))

第6章Logistic回归与最大熵模型-习题
习题6.1
确认Logistic分布属于指数分布族。
解答:
第1步:
首先给出指数分布族的定义:
对于随机变量
x
x
x,在给定参数
η
\eta
η下,其概率分别满足如下形式:
p
(
x
∣
η
)
=
h
(
x
)
g
(
η
)
exp
(
η
T
u
(
x
)
)
p(x|\eta)=h(x)g(\eta)\exp(\eta^Tu(x))
p(x∣η)=h(x)g(η)exp(ηTu(x))我们称之为指数分布族。
其中:
x
x
x:可以是标量或者向量,可以是离散值也可以是连续值
η
\eta
η:自然参数
g
(
η
)
g(\eta)
g(η):归一化系数
h
(
x
)
,
u
(
x
)
h(x),u(x)
h(x),u(x):
x
x
x的某个函数
第2步: 证明伯努利分布属于指数分布族
伯努利分布:
φ
\varphi
φ是
y
=
1
y=1
y=1的概率,即
P
(
Y
=
1
)
=
φ
P(Y=1)=\varphi
P(Y=1)=φ
P
(
y
∣
φ
)
=
φ
y
(
1
−
φ
)
(
1
−
y
)
=
(
1
−
φ
)
φ
y
(
1
−
φ
)
(
−
y
)
=
(
1
−
φ
)
(
φ
1
−
φ
)
y
=
(
1
−
φ
)
exp
(
y
ln
φ
1
−
φ
)
=
1
1
+
e
η
exp
(
η
y
)
\begin{aligned} P(y|\varphi) &= \varphi^y (1-\varphi)^{(1-y)} \\ &= (1-\varphi) \varphi^y (1-\varphi)^{(-y)} \\ &= (1-\varphi) (\frac{\varphi}{1-\varphi})^y \\ &= (1-\varphi) \exp\left(y \ln \frac{\varphi}{1-\varphi} \right) \\ &= \frac{1}{1+e^\eta} \exp (\eta y) \end{aligned}
P(y∣φ)=φy(1−φ)(1−y)=(1−φ)φy(1−φ)(−y)=(1−φ)(1−φφ)y=(1−φ)exp(yln1−φφ)=1+eη1exp(ηy)
其中,
η
=
ln
φ
1
−
φ
⇔
φ
=
1
1
+
e
−
η
\displaystyle \eta=\ln \frac{\varphi}{1-\varphi} \Leftrightarrow \varphi = \frac{1}{1+e^{-\eta}}
η=ln1−φφ⇔φ=1+e−η1
将
y
y
y替换成
x
x
x,可得
P
(
x
∣
η
)
=
1
1
+
e
η
exp
(
η
x
)
\displaystyle P(x|\eta) = \frac{1}{1+e^\eta} \exp (\eta x)
P(x∣η)=1+eη1exp(ηx)
对比可知,伯努利分布属于指数分布族,其中
h
(
x
)
=
1
,
g
(
η
)
=
1
1
+
e
η
,
u
(
x
)
=
x
\displaystyle h(x) = 1, g(\eta)= \frac{1}{1+e^\eta}, u(x)=x
h(x)=1,g(η)=1+eη1,u(x)=x
第3步:
广义线性模型(GLM)必须满足三个假设:
- y ∣ x ; θ ∼ E x p o n e n t i a l F a m i l y ( η ) y | x;\theta \sim ExponentialFamily(\eta) y∣x;θ∼ExponentialFamily(η),即假设预测变量 y y y在给定 x x x,以 θ \theta θ为参数的条件概率下,属于以 η \eta η作为自然参数的指数分布族;
- 给定 x x x,求解出以 x x x为条件的 T ( y ) T(y) T(y)的期望 E [ T ( y ) ∣ x ] E[T(y)|x] E[T(y)∣x],即算法输出为 h ( x ) = E [ T ( y ) ∣ x ] h(x)=E[T(y)|x] h(x)=E[T(y)∣x]
- 满足 η = θ T x \eta=\theta^T x η=θTx,即自然参数和输入特征向量 x x x之间线性相关,关系由 θ \theta θ决定,仅当 η \eta η是实数时才有意义,若 η \eta η是一个向量,则 η i = θ i T x \eta_i=\theta_i^T x ηi=θiTx
第4步: 推导伯努利分布的GLM
已知伯努利分布属于指数分布族,对给定的
x
,
η
x,\eta
x,η,求解期望:
h
θ
(
x
)
=
E
[
y
∣
x
;
θ
]
=
1
⋅
p
(
y
=
1
)
+
0
⋅
p
(
y
=
0
)
=
φ
=
1
1
+
e
−
η
=
1
1
+
e
−
θ
T
x
\begin{aligned} h_{\theta}(x) &= E[y|x;\theta] \\ &= 1 \cdot p(y=1)+ 0 \cdot p(y=0) \\ &= \varphi \\ &= \frac{1}{1+e^{-\eta}} \\ &= \frac{1}{1+e^{-\theta^T x}} \end{aligned}
hθ(x)=E[y∣x;θ]=1⋅p(y=1)+0⋅p(y=0)=φ=1+e−η1=1+e−θTx1可得到Logistic回归算法,故Logistic分布属于指数分布族,得证。
习题6.2
写出Logistic回归模型学习的梯度下降算法。
解答:
对于Logistic模型:
P
(
Y
=
1
∣
x
)
=
exp
(
w
⋅
x
+
b
)
1
+
exp
(
w
⋅
x
+
b
)
P
(
Y
=
0
∣
x
)
=
1
1
+
exp
(
w
⋅
x
+
b
)
P(Y=1 | x)=\frac{\exp (w \cdot x+b)}{1+\exp (w \cdot x+b)} \\ P(Y=0 | x)=\frac{1}{1+\exp (w \cdot x+b)}
P(Y=1∣x)=1+exp(w⋅x+b)exp(w⋅x+b)P(Y=0∣x)=1+exp(w⋅x+b)1对数似然函数为:
L
(
w
)
=
∑
i
=
1
N
[
y
i
(
w
⋅
x
i
)
−
log
(
1
+
exp
(
w
⋅
x
i
)
)
]
\displaystyle L(w)=\sum_{i=1}^N \left[y_i (w \cdot x_i)-\log \left(1+\exp (w \cdot x_i)\right)\right]
L(w)=i=1∑N[yi(w⋅xi)−log(1+exp(w⋅xi))]
似然函数求偏导,可得
∂
L
(
w
)
∂
w
(
j
)
=
∑
i
=
1
N
[
x
i
(
j
)
⋅
y
i
−
exp
(
w
⋅
x
i
)
⋅
x
i
(
j
)
1
+
exp
(
w
⋅
x
i
)
]
\displaystyle \frac{\partial L(w)}{\partial w^{(j)}}=\sum_{i=1}^N\left[x_i^{(j)} \cdot y_i-\frac{\exp (w \cdot x_i) \cdot x_i^{(j)}}{1+\exp (w \cdot x_i)}\right]
∂w(j)∂L(w)=i=1∑N[xi(j)⋅yi−1+exp(w⋅xi)exp(w⋅xi)⋅xi(j)]
梯度函数为:
∇
L
(
w
)
=
[
∂
L
(
w
)
∂
w
(
0
)
,
⋯
,
∂
L
(
w
)
∂
w
(
m
)
]
\displaystyle \nabla L(w)=\left[\frac{\partial L(w)}{\partial w^{(0)}}, \cdots, \frac{\partial L(w)}{\partial w^{(m)}}\right]
∇L(w)=[∂w(0)∂L(w),⋯,∂w(m)∂L(w)]
Logistic回归模型学习的梯度下降算法:
(1) 取初始值
x
(
0
)
∈
R
x^{(0)} \in R
x(0)∈R,置
k
=
0
k=0
k=0
(2) 计算
f
(
x
(
k
)
)
f(x^{(k)})
f(x(k))
(3) 计算梯度
g
k
=
g
(
x
(
k
)
)
g_k=g(x^{(k)})
gk=g(x(k)),当
∥
g
k
∥
<
ε
\|g_k\| < \varepsilon
∥gk∥<ε时,停止迭代,令
x
∗
=
x
(
k
)
x^* = x^{(k)}
x∗=x(k);否则,求
λ
k
\lambda_k
λk,使得
f
(
x
(
k
)
+
λ
k
g
k
)
=
max
λ
⩾
0
f
(
x
(
k
)
+
λ
g
k
)
\displaystyle f(x^{(k)}+\lambda_k g_k) = \max_{\lambda \geqslant 0}f(x^{(k)}+\lambda g_k)
f(x(k)+λkgk)=λ⩾0maxf(x(k)+λgk)
(4) 置
x
(
k
+
1
)
=
x
(
k
)
+
λ
k
g
k
x^{(k+1)}=x^{(k)}+\lambda_k g_k
x(k+1)=x(k)+λkgk,计算
f
(
x
(
k
+
1
)
)
f(x^{(k+1)})
f(x(k+1)),当
∥
f
(
x
(
k
+
1
)
)
−
f
(
x
(
k
)
)
∥
<
ε
\|f(x^{(k+1)}) - f(x^{(k)})\| < \varepsilon
∥f(x(k+1))−f(x(k))∥<ε或
∥
x
(
k
+
1
)
−
x
(
k
)
∥
<
ε
\|x^{(k+1)} - x^{(k)}\| < \varepsilon
∥x(k+1)−x(k)∥<ε时,停止迭代,令
x
∗
=
x
(
k
+
1
)
x^* = x^{(k+1)}
x∗=x(k+1)
(5) 否则,置
k
=
k
+
1
k=k+1
k=k+1,转(3)
%matplotlib inline
import numpy as np
import time
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from pylab import mpl
# 图像显示中文
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']
class LogisticRegression:
def __init__(self, learn_rate=0.1, max_iter=10000, tol=1e-2):
self.learn_rate = learn_rate # 学习率
self.max_iter = max_iter # 迭代次数
self.tol = tol # 迭代停止阈值
self.w = None # 权重
def preprocessing(self, X):
"""将原始X末尾加上一列,该列数值全部为1"""
row = X.shape[0] # 0:输出行数,1:输出列数
y = np.ones(row).reshape(row, 1)
X_prepro = np.hstack((X, y)) # https://blog.csdn.net/m0_37393514/article/details/79538748
return X_prepro
def sigmod(self, x):
return 1 / (1 + np.exp(-x))
def fit(self, X_train, y_train):
X = self.preprocessing(X_train)
y = y_train.T
# 初始化权重w
self.w = np.array([[0] * X.shape[1]], dtype=np.float)
k = 0
for loop in range(self.max_iter):
# 计算梯度
z = np.dot(X, self.w.T)
grad = X * (y - self.sigmod(z))
grad = grad.sum(axis=0)
# 利用梯度的绝对值作为迭代中止的条件
# all() 函数用于判断给定的可迭代参数中的所有元素是否都为TRUE,如果是返回True,否则返回False。
if (np.abs(grad) <= self.tol).all():
break
else:
# 更新权重w 梯度上升——求极大值
self.w += self.learn_rate * grad
k += 1
print("迭代次数:{}次".format(k))
print("最终梯度:{}".format(grad))
print("最终权重:{}".format(self.w[0]))
def predict(self, x):
p = self.sigmod(np.dot(self.preprocessing(x), self.w.T))
print("Y=1的概率被估计为:{:.2%}".format(p[0][0])) # 调用score时,注释掉
p[np.where(p > 0.5)] = 1 # https://blog.csdn.net/island1995/article/details/90200151
p[np.where(p < 0.5)] = 0
return p
def score(self, X, y):
y_c = self.predict(X)
error_rate = np.sum(np.abs(y_c - y.T)) / y_c.shape[0]
return 1 - error_rate
def draw(self, X, y):
# 分离正负实例点
y = y[0]
X_po = X[np.where(y == 1)]
X_ne = X[np.where(y == 0)]
# 绘制数据集散点图
ax = plt.axes(projection='3d')
x_1 = X_po[0, :]
y_1 = X_po[1, :]
z_1 = X_po[2, :]
x_2 = X_ne[0, :]
y_2 = X_ne[1, :]
z_2 = X_ne[2, :]
ax.scatter(x_1, y_1, z_1, c="r", label="正实例")
ax.scatter(x_2, y_2, z_2, c="b", label="负实例")
ax.legend(loc='best')
# 绘制p=0.5的区分平面
x = np.linspace(-3, 3, 3)
y = np.linspace(-3, 3, 3)
x_3, y_3 = np.meshgrid(x, y)
a, b, c, d = self.w[0]
z_3 = -(a * x_3 + b * y_3 + d) / c
ax.plot_surface(x_3, y_3, z_3, alpha=0.5) # 调节透明度
plt.show()
# 训练数据集
X_train = np.array([[3, 3, 3], [4, 3, 2], [2, 1, 2], [1, 1, 1], [-1, 0, 1],
[2, -2, 1]])
y_train = np.array([[1, 1, 1, 0, 0, 0]])
# 构建实例,进行训练
clf = LogisticRegression()
clf.fit(X_train, y_train)
clf.draw(X_train, y_train)

习题6.3
写出最大熵模型学习的DFP算法。
解答:
第1步:
最大熵模型为:
max
H
(
p
)
=
−
∑
x
,
y
P
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
st.
E
p
(
f
i
)
−
E
p
^
(
f
i
)
=
0
,
i
=
1
,
2
,
⋯
,
n
∑
y
P
(
y
∣
x
)
=
1
\begin{array}{cl} {\max } & {H(p)=-\sum_{x, y} P(x) P(y | x) \log P(y | x)} \\ {\text {st.}} & {E_p(f_i)-E_{\hat{p}}(f_i)=0, \quad i=1,2, \cdots,n} \\ & {\sum_y P(y | x)=1} \end{array}
maxst.H(p)=−∑x,yP(x)P(y∣x)logP(y∣x)Ep(fi)−Ep^(fi)=0,i=1,2,⋯,n∑yP(y∣x)=1引入拉格朗日乘子,定义拉格朗日函数:
L
(
P
,
w
)
=
∑
x
y
P
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
+
w
0
(
1
−
∑
y
P
(
y
∣
x
)
)
+
∑
i
=
1
w
i
(
∑
x
y
P
(
x
,
y
)
f
i
(
x
,
y
)
−
∑
x
y
P
(
x
,
y
)
P
(
y
∣
x
)
f
i
(
x
,
y
)
)
L(P, w)=\sum_{xy} P(x) P(y | x) \log P(y | x)+w_0 \left(1-\sum_y P(y | x)\right) \\ +\sum_{i=1} w_i\left(\sum_{xy} P(x, y) f_i(x, y)-\sum_{xy} P(x, y) P(y | x) f_i(x, y)\right)
L(P,w)=xy∑P(x)P(y∣x)logP(y∣x)+w0(1−y∑P(y∣x))+i=1∑wi(xy∑P(x,y)fi(x,y)−xy∑P(x,y)P(y∣x)fi(x,y))
最优化原始问题为:
min
P
∈
C
max
w
L
(
P
,
w
)
\min_{P \in C} \max_{w} L(P,w)
P∈CminwmaxL(P,w)对偶问题为:
max
w
min
P
∈
C
L
(
P
,
w
)
\max_{w} \min_{P \in C} L(P,w)
wmaxP∈CminL(P,w)令
Ψ
(
w
)
=
min
P
∈
C
L
(
P
,
w
)
=
L
(
P
w
,
w
)
\Psi(w) = \min_{P \in C} L(P,w) = L(P_w, w)
Ψ(w)=P∈CminL(P,w)=L(Pw,w)
Ψ
(
w
)
\Psi(w)
Ψ(w)称为对偶函数,同时,其解记作
P
w
=
arg
min
P
∈
C
L
(
P
,
w
)
=
P
w
(
y
∣
x
)
P_w = \mathop{\arg \min}_{P \in C} L(P,w) = P_w(y|x)
Pw=argminP∈CL(P,w)=Pw(y∣x)求
L
(
P
,
w
)
L(P,w)
L(P,w)对
P
(
y
∣
x
)
P(y|x)
P(y∣x)的偏导数,并令偏导数等于0,解得:
P
w
(
y
∣
x
)
=
1
Z
w
(
x
)
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
P_w(y | x)=\frac{1}{Z_w(x)} \exp \left(\sum_{i=1}^n w_i f_i (x, y)\right)
Pw(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))其中:
Z
w
(
x
)
=
∑
y
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
Z_w(x)=\sum_y \exp \left(\sum_{i=1}^n w_i f_i(x, y)\right)
Zw(x)=y∑exp(i=1∑nwifi(x,y))则最大熵模型目标函数表示为
φ
(
w
)
=
min
w
∈
R
n
Ψ
(
w
)
=
∑
x
P
(
x
)
log
∑
y
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
−
∑
x
,
y
P
(
x
,
y
)
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
\varphi(w)=\min_{w \in R_n} \Psi(w) = \sum_{x} P(x) \log \sum_{y} \exp \left(\sum_{i=1}^{n} w_{i} f_{i}(x, y)\right)-\sum_{x, y} P(x, y) \sum_{i=1}^{n} w_{i} f_{i}(x, y)
φ(w)=w∈RnminΨ(w)=x∑P(x)logy∑exp(i=1∑nwifi(x,y))−x,y∑P(x,y)i=1∑nwifi(x,y)
第2步:
DFP的
G
k
+
1
G_{k+1}
Gk+1的迭代公式为:
G
k
+
1
=
G
k
+
δ
k
δ
k
T
δ
k
T
y
k
−
G
k
y
k
y
k
T
G
k
y
k
T
G
k
y
k
G_{k+1}=G_k+\frac{\delta_k \delta_k^T}{\delta_k^T y_k}-\frac{G_k y_k y_k^T G_k}{y_k^T G_k y_k}
Gk+1=Gk+δkTykδkδkT−ykTGkykGkykykTGk
最大熵模型的DFP算法:
输入:目标函数
φ
(
w
)
\varphi(w)
φ(w),梯度
g
(
w
)
=
∇
g
(
w
)
g(w) = \nabla g(w)
g(w)=∇g(w),精度要求
ε
\varepsilon
ε;
输出:
φ
(
w
)
\varphi(w)
φ(w)的极小值点
w
∗
w^*
w∗
(1)选定初始点
w
(
0
)
w^{(0)}
w(0),取
G
0
G_0
G0为正定对称矩阵,置
k
=
0
k=0
k=0
(2)计算
g
k
=
g
(
w
(
k
)
)
g_k=g(w^{(k)})
gk=g(w(k)),若
∥
g
k
∥
<
ε
\|g_k\| < \varepsilon
∥gk∥<ε,则停止计算,得近似解
w
∗
=
w
(
k
)
w^*=w^{(k)}
w∗=w(k),否则转(3)
(3)置
p
k
=
−
G
k
g
k
p_k=-G_kg_k
pk=−Gkgk
(4)一维搜索:求
λ
k
\lambda_k
λk使得
φ
(
w
(
k
)
+
λ
k
P
k
)
=
min
λ
⩾
0
φ
(
w
(
k
)
+
λ
P
k
)
\varphi\left(w^{(k)}+\lambda_k P_k\right)=\min _{\lambda \geqslant 0} \varphi\left(w^{(k)}+\lambda P_{k}\right)
φ(w(k)+λkPk)=λ⩾0minφ(w(k)+λPk)(5)置
w
(
k
+
1
)
=
w
(
k
)
+
λ
k
p
k
w^{(k+1)}=w^{(k)}+\lambda_k p_k
w(k+1)=w(k)+λkpk
(6)计算
g
k
+
1
=
g
(
w
(
k
+
1
)
)
g_{k+1}=g(w^{(k+1)})
gk+1=g(w(k+1)),若
∥
g
k
+
1
∥
<
ε
\|g_{k+1}\| < \varepsilon
∥gk+1∥<ε,则停止计算,得近似解
w
∗
=
w
(
k
+
1
)
w^*=w^{(k+1)}
w∗=w(k+1);否则,按照迭代式算出
G
k
+
1
G_{k+1}
Gk+1
(7)置
k
=
k
+
1
k=k+1
k=k+1,转(3)
数据来源:统计学习方法(第二版) &
https://github.com/fengdu78/lihang-code















 2571
2571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









