







“物以类聚,人以群分”。包罗万象的数据也是如此,数据本身是凌乱的,如何在凌乱之中去发掘数据的信息呢?本文将介绍聚类模型。
所谓聚类,就是将样本划分为由类似对象组成的多个类的过程。聚类后,我们就可以更加准确地在每个类中单独使用统计模型进行估计、分析或预测;也可以探究不同类之间地相关性和差异性。
K-means聚类算法
算法流程:
(1)指定需要划分地簇地个数K值(即为类地个数)
(2)随机地选择K个数据对象作为初始的聚类中心
(3)计算其余的各数据对象到这K个聚类中心的距离,把数据对象划归到距离它最近的那个中心所在的簇类中
(4)调整新类并重新计算新类的中心
(5)循环步骤3、4,看中心是否收敛,如果收敛或者达到迭代次数则停止循环
(6)OVER

优点:
(1)算法简单、快速。
(2)对处理大数据集,该算法是相对高效率的。
缺点:
(1)要求用户必须事先给出要生成的簇的数目K。
(2)对初值敏感。
(3)对于孤立点数据敏感。
K‐means++ 算法
K‐means++算法可解决2和3这两个缺点。
K‐means++算法选择聚类中心的基本原则是:初始的聚类中心之间的相互距离要尽可能远

附:Spss软件操作
注:Spss默认使用的就是K-means++算法
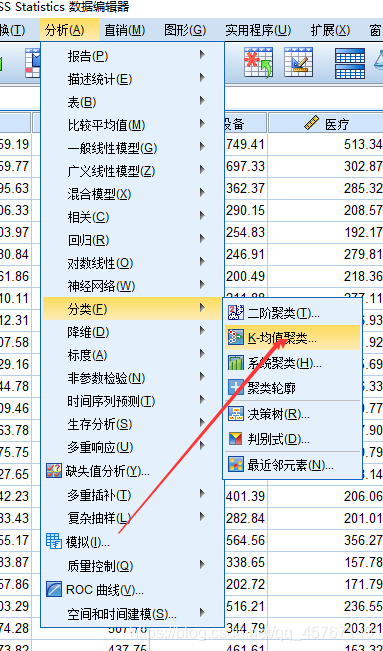
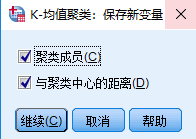
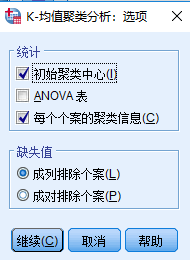
数据的量纲不一致怎么办?
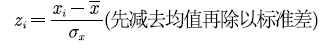
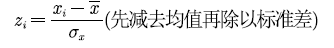
系统(层次)聚类
系统聚类的合并算法是通过计算两类数据点之间的距离,对距离最为接近的两类数据进行组合,并反复迭代这一过程,直到所有的数据点合成一类,并生成聚类谱系图。
附:Spss软件操作




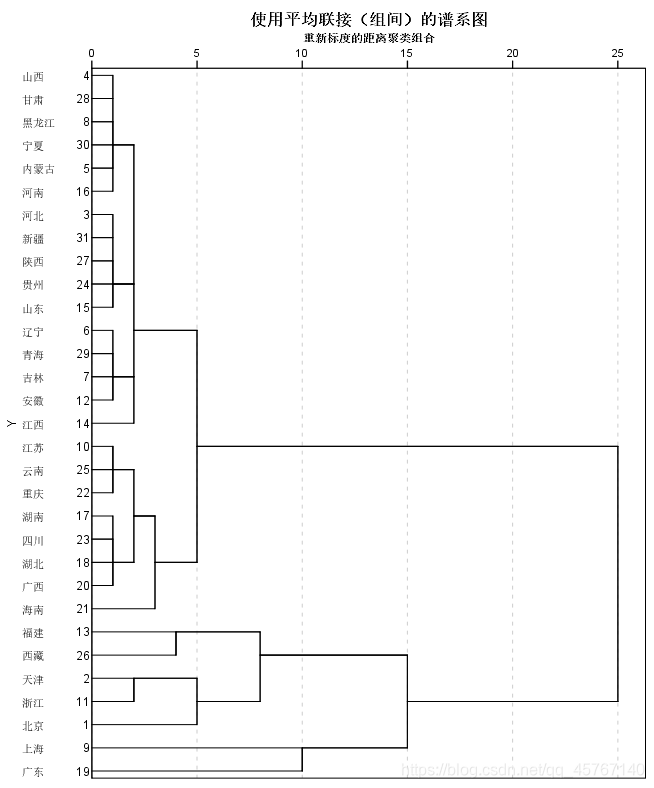
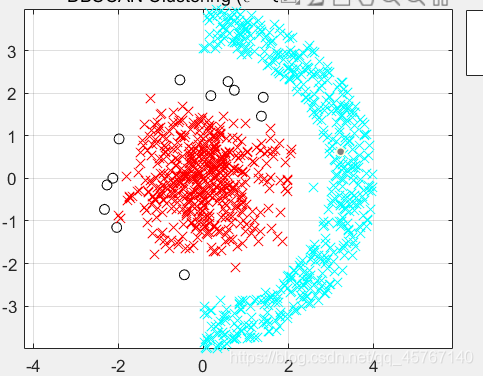
DBSCAN算法
一种基于密度的聚类方法,聚类前不需要预先指定聚类的个数,生成的簇的个数不定(和数据有关)。该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。该方法能在具有噪声的空间数据库中发现任意形状的簇,可将密度足够大的相邻区域连接,能有效处理异常数据。

DBSCAN算法将数据点分为三类:
• 核心点:在半径Eps内含有不少于MinPts数目的点
• 边界点:在半径Eps内点的数量小于MinPts,但是落在核心
点的邻域内
• 噪音点:既不是核心点也不是边界点的点
优点:
1、基于密度定义,能处理任意形状和大小的簇
2、可在聚类的同时发现异常点
3、与K-means相比,不需要输入要划分的聚类个数
缺点:
1、对于阈值和半径敏感,确定参数困难
2、当聚类的密度不均匀时,聚类距离相差很大时,聚类质量差;
3、 当数据量大时,计算密度单元的计算复杂度大。
DBSCAN 也可用于异常点分析。
function [IDX, isnoise]=DBSCAN(X,epsilon,MinPts)
C=0;
n=size(X,1);
IDX=zeros(n,1); % 初始化全部为0,即全部为噪音点
D=pdist2(X,X);
visited=false(n,1);
isnoise=false(n,1);
for i=1:n
if ~visited(i)
visited(i)=true;
Neighbors=RegionQuery(i);
if numel(Neighbors)<MinPts
% X(i,:) is NOISE
isnoise(i)=true;
else
C=C+1;
ExpandCluster(i,Neighbors,C);
end
end
end
function ExpandCluster(i,Neighbors,C)
IDX(i)=C;
k = 1;
while true
j = Neighbors(k);
if ~visited(j)
visited(j)=true;
Neighbors2=RegionQuery(j);
if numel(Neighbors2)>=MinPts
Neighbors=[Neighbors Neighbors2]; %#ok
end
end
if IDX(j)==0
IDX(j)=C;
end
k = k + 1;
if k > numel(Neighbors)
break;
end
end
end
function Neighbors=RegionQuery(i)
Neighbors=find(D(i,:)<=epsilon);
end
end















 9218
9218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









