






一.欧氏空间和非欧氏空间
-
欧氏空间: 欧氏空间是我们熟悉的三维几何空间,也可以推广到更高维度。在欧氏空间中,我们使用欧几里得距离(即直线距离)来度量两点之间的距离。例如,我们通常熟悉的平面几何和立体几何就是欧氏空间的例子。
举例:假设有一张平面纸上的两个点A和B,我们可以用尺子直接测量点A到点B的距离,这就是欧氏空间的应用。
-
非欧氏空间: 非欧氏空间是一类不满足欧几里得几何公理的几何空间。在非欧氏空间中,点之间的距离和角度可能会有不同的定义,导致其几何性质与欧氏空间不同。非欧氏几何学由19世纪数学家发展而来,是对传统欧氏几何的一种拓展。
举例:一个常见的非欧氏空间是球面上的几何。在球面上,两点之间的最短距离不再是直线,而是沿着球面上的大圆弧(类似于地球上两点之间的最短距离是沿着经线和纬线行走)。在球面上的角度也遵循特定的非欧氏几何规则。
总结:欧氏空间是我们通常所接触到的几何空间,其中点之间的距离是直线距离。而非欧氏空间则是一类拓展了欧氏空间概念的几何空间,它的度量和几何性质可能会有所不同,例如球面几何。
二.欧式数据和非欧式数据
"欧式数据"和"非欧数据"这两个术语并不是普遍使用的标准术语,因此在不同上下文中可能有不同的含义。以下是在机器学习和数据分析领域中可能涉及到的一种解释:
-
欧式数据(Euclidean data): 在机器学习中,欧式数据通常指的是数据样本在欧式空间中的表示。欧式空间是一个常见的几何空间,其中的数据表示为向量,且满足欧氏几何的度量。在欧式空间中,我们可以使用欧几里得距离来度量数据样本之间的相似性。
举例:在一个简单的二维平面上,每个数据样本可以由两个实数构成,比如(x, y)坐标点,这样的数据就是欧式数据。在欧式空间中,我们可以计算这些点之间的距离,比如欧几里得距离:√((x2 - x1)^2 + (y2 - y1)^2)。
-
非欧数据(Non-Euclidean data): 非欧数据则是指在非欧式空间中表示的数据样本。非欧式空间是一类不满足欧几里得几何的几何空间,点之间的距离和度量可能具有不同的定义。在非欧式空间中,数据样本的表示可能不再是向量。
举例:在机器学习中,某些问题可能涉及到图数据、文本数据或时间序列数据等,这些数据样本可能不容易用向量表示,并且在处理这些数据时需要考虑非欧式空间的度量和几何性质。
总结:在机器学习和数据分析中,"欧式数据"通常指的是在欧式空间中用向量表示的数据,而"非欧数据"指的是在非欧式空间中表示的数据,比如图数据、文本数据等。这些术语用于强调数据样本的表示和处理可能涉及的不同几何结构和度量方法。请注意,这些术语的具体含义可能因上下文而异。

下面内容参考自:数据域(欧几里得数据与非欧几里得数据) - 知乎 (zhihu.com)
随着网络时代的发展,生活中产生的数据量越来越多,但数据大体分为两类:欧几里得数据、非欧几里得数据。如下图为两类常见的数据:
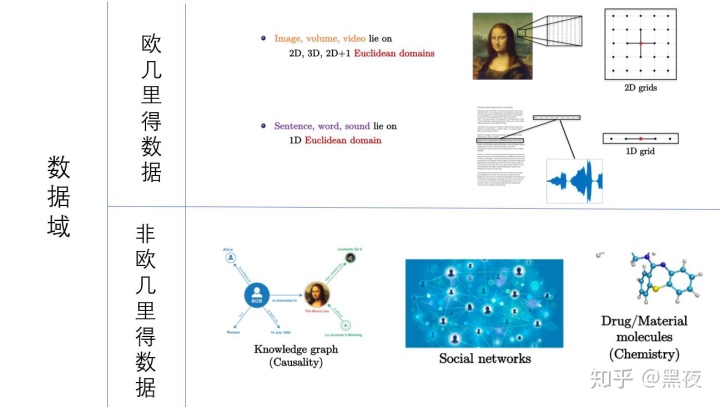
图1 数据类型
上图所示数据主要分为两类:欧几里得数据与非欧几里得数据。
欧几里得数据
它是一类具有很好的平移不变性的数据。对于这类数据以其中一个像素为节点,其邻居节点的数量相同。所以可以很好的定义一个全局共享的卷积核来提取图像中相同的结构。常见这类数据有图像、文本、语言。
1. 图像中的平移不变性:即不管图像中的目标被移动到图片的哪个位置,得到的结果(标签)应该相同的。
2. 卷积被定义为不同位置的特征检测器。
图像:图像是一种2D的网格类型数据,通常用矩阵进行存储。
文本:文本是一种1D的网格类型数据,通常可以用向量进行存储。对于文本,我们通常做法是去停用词、以及高频词(DIFT),最后嵌入到一个一维的向量空间。
非欧几里得数据
它是一类不具有平移不变性的数据。这类数据以其中的一个为节点,其邻居节点的数量可能不同。常见这类数据有知识图谱、社交网络、化学分子结构等等。
这类数据由于其不具备平移不变性,不能利用卷积核去提取相同的结构信息,所以卷积神经网络对于这类数据无能为力。所以衍生出了处理这类数据的网络,即图神经网络。















 9630
9630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









