







 本文介绍了使用Python的pyppeteer库模拟浏览器填答问卷星问卷的过程,包括如何处理智能验证,以及通过BeautifulSoup解析网页源码定位填写字段。代码示例展示了如何设置浏览器头、模拟用户代理以及填写表单。
本文介绍了使用Python的pyppeteer库模拟浏览器填答问卷星问卷的过程,包括如何处理智能验证,以及通过BeautifulSoup解析网页源码定位填写字段。代码示例展示了如何设置浏览器头、模拟用户代理以及填写表单。
本代码仅供学习交流!
前言
尝试一下程序提交问卷星的可能。本来想的是post提交,小伙伴们有没有发现问卷星的加密难度是螺旋式升天,对于我这种小白来说极为的不友好。
一、post失败
个人感觉最难的是jqparm参数,百度到一位大佬破解成功了,不过现在好像不行了。但是思路还是可以大致了解下的。传送门
二、转向模拟浏览器
本来是用的selenium,代码都即将完工,但是偏偏来了一个智能验证,相信试过的小伙伴都知道了,会跳出来一个智能验证,它能识别出我们使用了selenium,就算你是真人点击也无法通过验证,此刻我的心情就只能草和一种四腿动物来表示。
如下图

最终在网上发现了一个库pyppeteer可以较为舒服的解决问题,大致思路就是让浏览器打开网址,根据网页的源代码来判断并进行填写,由于最后还有一个未知的选时间段的,最后就自己选下并提交,解决战斗。
代码如下:
import asyncio
from pyppeteer import launch
from pyppeteer_stealth import stealth
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import re
import time
url = "https://www.wjx.top/m/91040160.aspx" #测试网址
name = "问卷星"
number = "11012011966"
QQ = "1111111111"
class_data = "摸鱼专业11-1班"
student_id="111111111"
async def run():
driver = await launch({
# 谷歌浏览器的安装路径
'executablePath': r'D:\360\Google\Chrome\Application\chrome.exe',
# Pyppeteer 默认使用的是无头浏览器
'headless': False,
# 设置Windows-size和Viewport大小来实现网页完整显示
'args': ['--no-sandbox', '--window-size=1024,768', '--disable-infobars'],
'dumpio': True,
})
# 用 newPage 方法相当于浏览器中新建了一个选项卡,同时新建了一个Page对象
page = await driver.newPage()
#简称换头
await page.setUserAgent(
UserAgent().random)
await page.setViewport({'width': 1024, 'height': 768})
# 反爬虫跳入网页
await stealth(page)
await page.goto(url) #问卷星网址
page_text = await page.content() # 获取网页源码
'''
下面的都是对文本的判断,大佬们直接忽略自己写就行了。
'''
Soup = BeautifulSoup(page_text, 'lxml')
list_judge_email = [] # 位置
list_ques = Soup.find_all(text=re.compile("姓名"))
list_ques.extend(Soup.find_all(text=re.compile("学号")))
list_ques.extend(Soup.find_all(text=re.compile("QQ")))
list_ques.extend(Soup.find_all(text=re.compile("qq")))
list_ques.extend(Soup.find_all(text=re.compile("号码" or "电话" or "联系方式")))
list_ques.extend(Soup.find_all(text=re.compile("班级" or "专业")))
list_judge_email.extend(Soup.find_all(verify=re.compile("Email")))
print(list_ques)
for i in list_ques:
if len(i) > 20: #有某些含有qq字眼但是却不是问题,直接排除
continue
print(i + "----------------")
if '姓名' in i:
da_name = 'q' + i[0]
if 'qq' in i or 'QQ' in i:
da_qq = 'q' + i[0]
if '班级' in i or '专业' in i:
da_class = 'q' + i[0]
if '学号' in i:
da_studentid = 'q' + i[0]
if '电话' in i or '手机' in i:
da_number = 'q' + i[0]
try:
await page.type('[name="' + da_name + '"]', name)
except:
print('找不到姓名')
try:
await page.type('[name="' + da_number + '"]', number)
except:
print('找不到手机号码')
try:
if list_judge_email: # 不为空要加@qq.com
await page.type('[name="' + da_qq + '"]', QQ + '@qq.com')
else: # 为空正常的qq号
await page.type('[name="' + da_qq + '"]', QQ)
except:
print('找不到QQ')
try:
await page.type('[name="' + da_class + '"]', class_data)
except:
print('找不到专业班级')
try:
await page.type('[name="' + da_studentid + '"]', student_id)
except:
print('找不到学号')
#定义在函数体内运行结束会直接退出浏览器,所以需要延时让我们完成时间段的选择,并提交
time.sleep(200)
asyncio.get_event_loop().run_until_complete(run())
2.运行结果
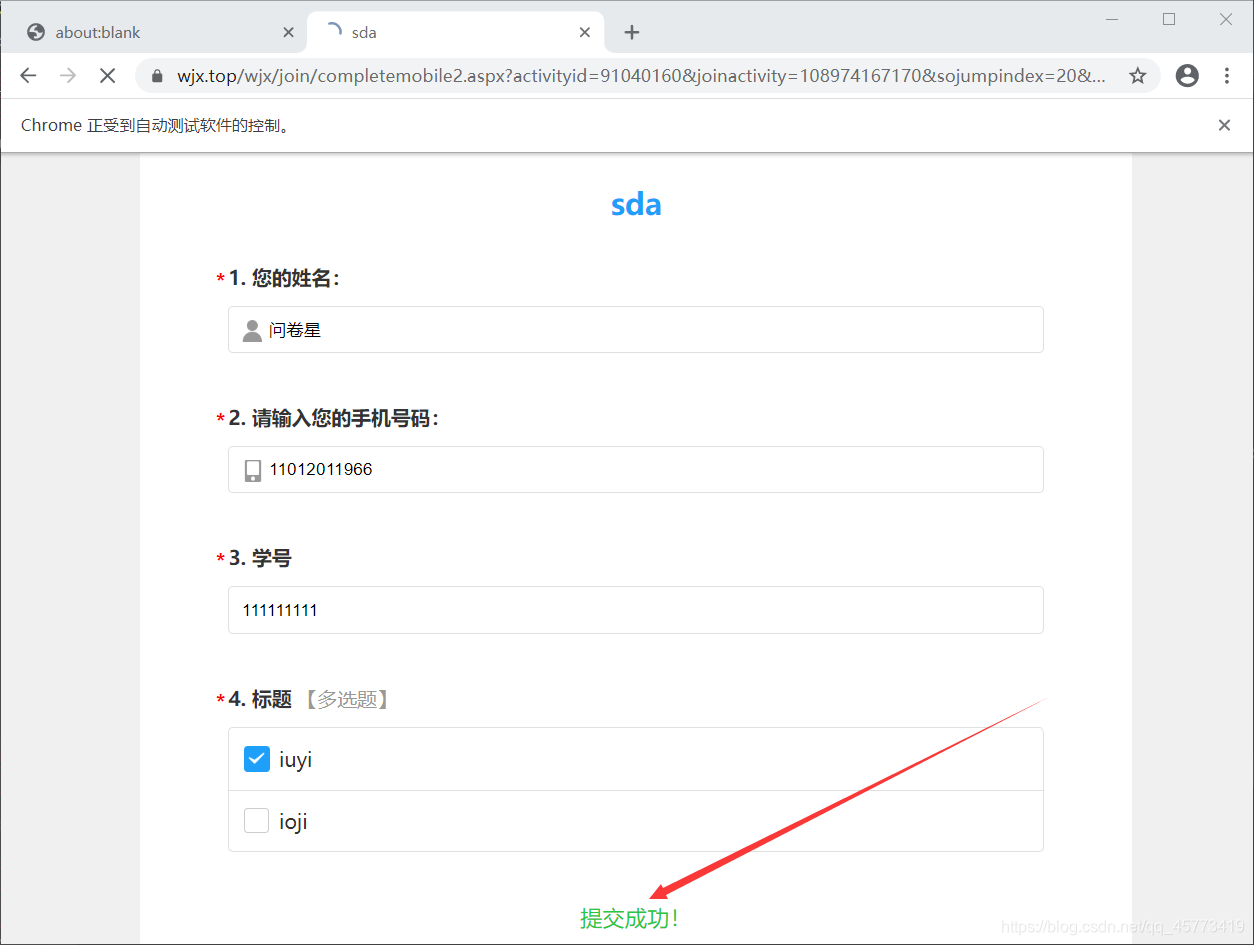
总结
又是很愉快的一次尝试呢!很多时候完成一件事情要考虑到它的时间成本以及收益,明显自己不会解js混淆,不过用浏览器也不赖啊。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











