







分布式索引构建方法
》大规模的索引构建必须使用一个分布式的计算机集群,比如Web
》利用集群中的主控节点来指挥索引构建工作
》将索引构建过程分解成一组并行的任务
》主控计算机从集群中选取一台空闲的机器并将任务分配给它

文档集分割:基于词项,文档
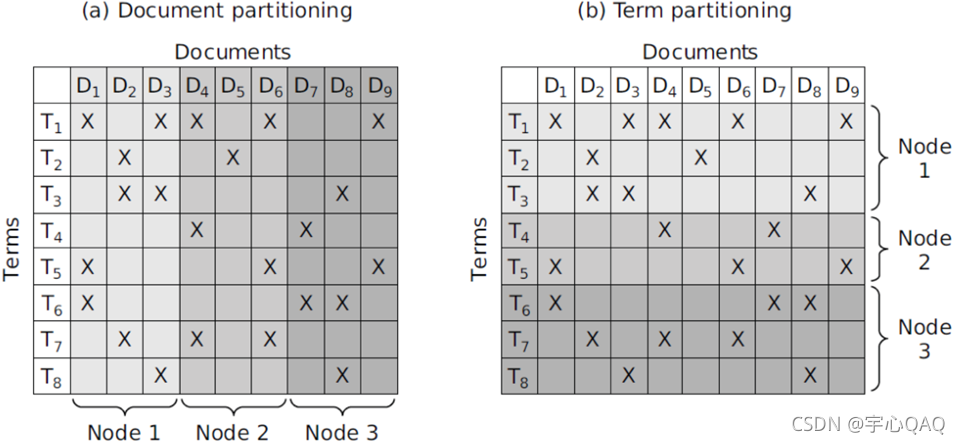
分析器Parsers .
主节点将一个数据片分配给一台空闲的分析服务器
分析器依次读取文档并生成<词项,文档>对
分析器将这些<词项,文档>对分成j个段
每一段是按照词项首字母划分的一个区间,例如: a-f, g-p, q-z,这里j=3
然后可以进行索引的倒排
倒排器:
对于一个词项分区,倒排器收集所有的<词项,文档>对(也就是“倒排记录")排序,并写入最终的倒排记录表
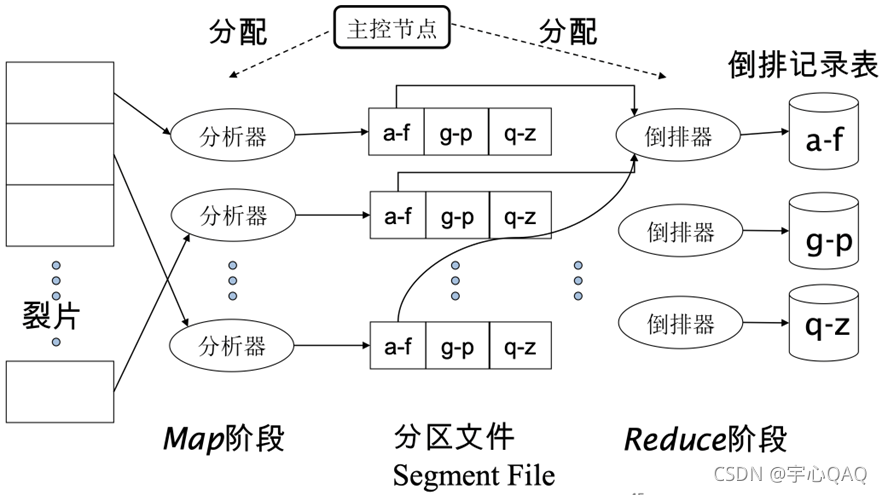

MapReduce
Google索引系统由各个不同的阶段组成,每个阶段都是MapReduce的一个应用,索引构建只是其中的一个阶段,另一个阶段是:将基于词项划分的索引表转换成基于文档划分的索引表
■基于词项划分的:一台机器处理所有词项的一个子区间
■基于文档划分的:一台机器处理所有文档的一个子区间
大部分搜索引擎都是采用基于文档划分的索引表-为什么?
更好的负载平衡
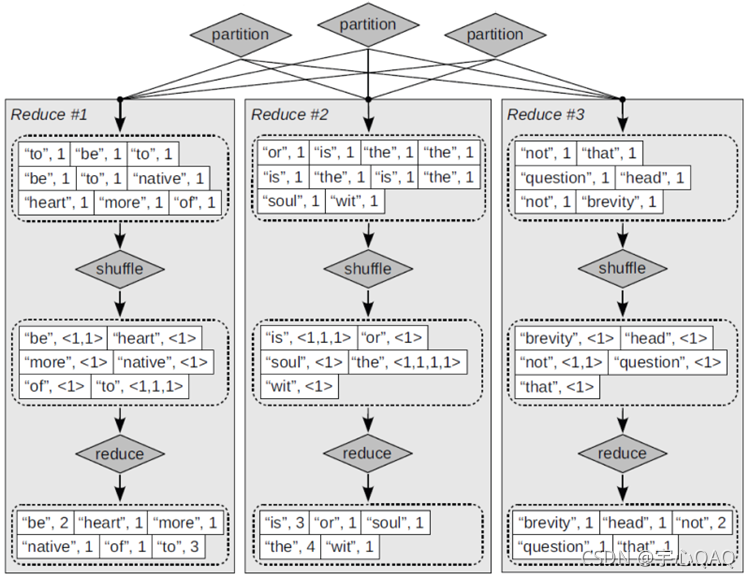
Map和Reduce函数的架构
■Map:输入->list(k,v) Reduce:(k,list(v))->输出
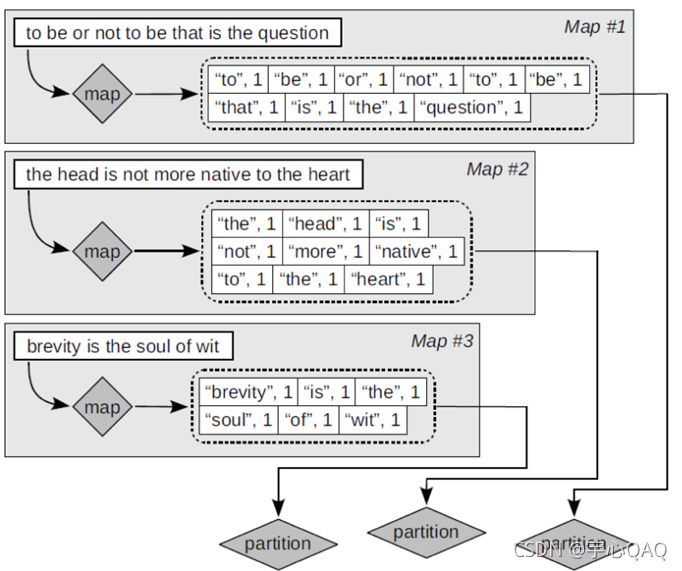
索引构建中上述架构的实例化
■Map: Web文档集—> list(词项,文档1D)
■Reduce: (<词项1 ,list(文档ID)>,<词项2,list(文档1D)…)—> (倒排记录表1,倒排记录表2…)
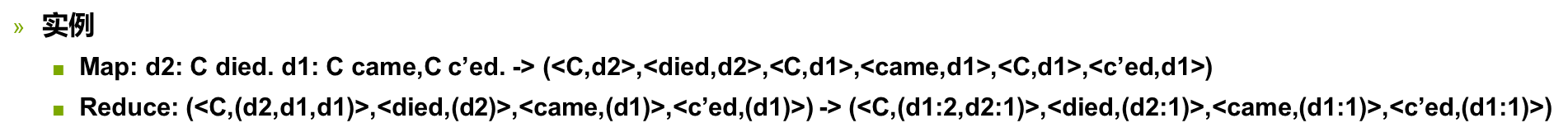
MAP:
Reduce:















 2265
2265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











