







PyTorch学习
一、线性回归
1、y = w1 * x^2 + w2 * x + b的线性模型
import torch
x_data = [1.0,2.0,3.0] #数据集
y_data = [2.0,4.0,6.0]
w1 = torch.Tensor([1.0])
w1.requires_grad = True #是否计算梯度
w2 = torch.Tensor([1.0])
w2.requires_grad = True
b = torch.Tensor([1.0])
b.requires_grad = True
def forward(x): #➡
return w1 * x * x + w2 * x + b
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) **2
print("predict (before training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y)
l.backward() #⬅
print('\tgrad:', x, y, w1.grad.item(), w2.grad.item(), b.grad.item())
w1.data = w1.data - 0.01 * w1.grad.data
w2.data = w2.data - 0.01 * w2.grad.data
b.data = b.data - 0.01 * b.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
b.grad.data.zero_()
print("progress:", epoch, l.item())
print("predict (after training)", 4, forward(4).item()) #在x等于4时预测y的值(4 8.544...)
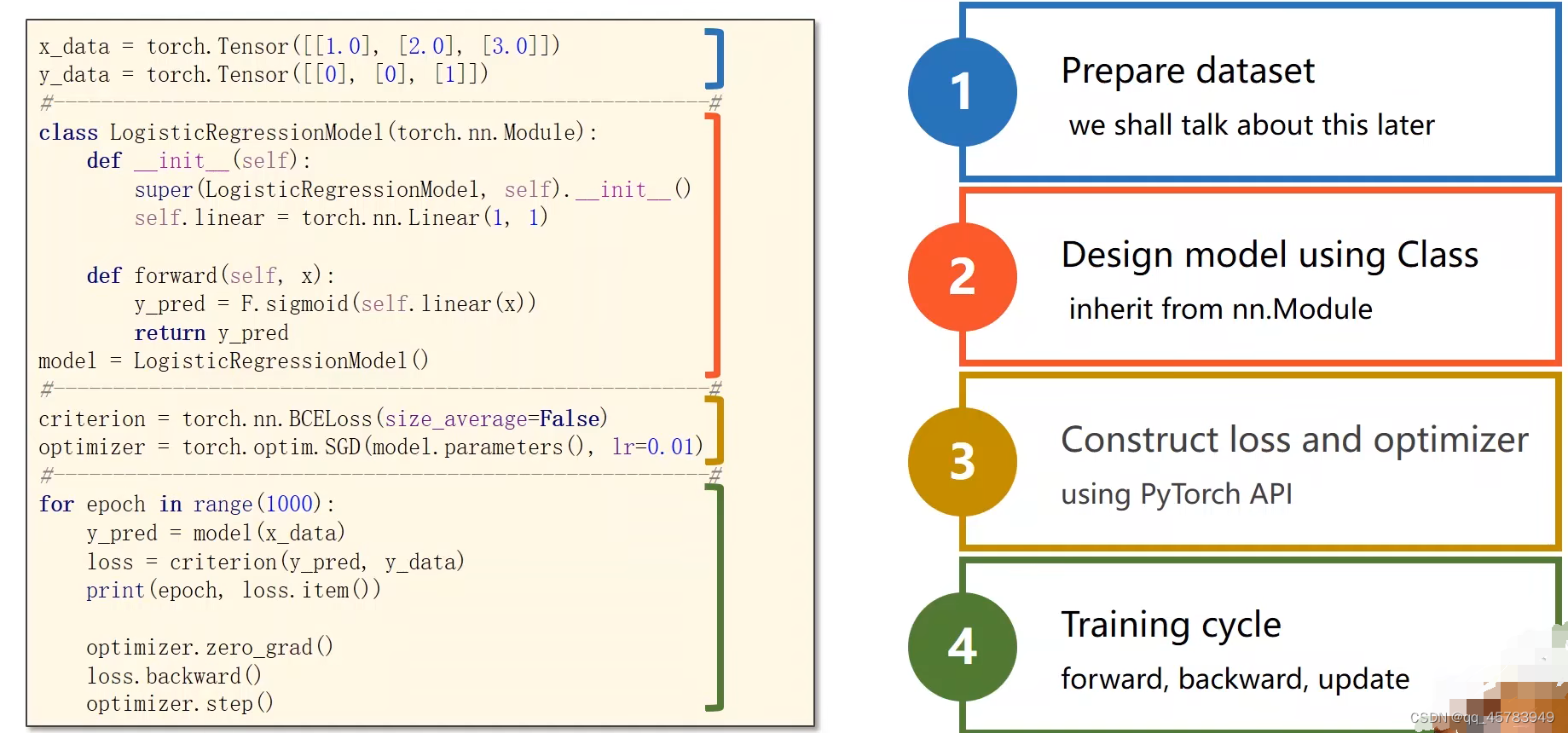
2、用 pytorch中的 module实现线性回归
1. 准备数据集
2. 利用class设计模型
从nn.Module里继承
3. construct loss and optimizer(构造损失和优化器)
using pyTorch API
4. 循环周期
forward,backward,update
代码实现:
import torch
#准备数据集
x_data = torch.Tensor([[1.0], [2.0], [3.0]]) #3行1列的矩阵 !!只能是矩阵
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
#利用class来设计模型
class LinearModel(torch.nn.Module):
def __init__(self): #必有的函数
super(LinearModel,self).__init__()
self.linear = torch.nn.Linear(1,1) #此处1,1代表x和y帽的维度,即列数
def forward(self, x): #必有的函数
y_pred = self.linear(x)
return y_pred
model = LinearModel()
#构造损失 & 优化器
criterion = torch.nn.MSELoss(size_average=False) #不取平均,也可以
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#训练周期
for epoch in range(1000): #迭代1000次 测试4.0,得到结果7.9994已经很接近8了
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item()) #.item取数值
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.Tensor([4.0]) #测试x为4.0时 y的值
y_test = model(x_test)
print('y_pred = ', y_test.data)
二、逻辑回归(分类)代码对比
三、Titanic数据集分类
数据集各列含义:
passengerid: 乘客 ID
class: 舱位等级 (1 = 1st, 2 = 2nd, 3 = 3rd)**
name: 乘客姓名
sex: 性别
age: 年龄
sibsp: 在船上的兄弟姐妹/配偶个数
parch: 在船上的父母/小孩个数
ticket: 船票信息
fare: 票价
cabin: 客舱
embarked: 登船港口 (C = Cherbourg, Q = Queenstown, S = Southampton)
survived: 变量预测为值 0 或 1(这里 1 表示幸存,0 表示遇难)
代码实现:
import numpy as np
import pandas as pd
import torch
from torch.utils.data import Dataset,DataLoader
# 数据预处理 (训练集 + 后期用到的测试集 都要处理)
# 参考链接:https://blog.csdn.net/weixin_44229737/article/details/132590265
# 主要用到了pandas库 经数据分析后,主要采用feature = ["Pclass", "Sex", "Age", "SibSp", "Parch"]作为相关数据特征
data_train = pd.read_csv('Titanic_Dataset/train.csv')
data_test = pd.read_csv('Titanic_Dataset/test.csv')
# 年龄以平均值填补缺失部分
data_train.loc[(data_train.Age.isnull()), 'Age'] = data_train.Age.mean()
data_test.loc[(data_train.Age.isnull()), 'Age'] = data_train.Age.mean()
# 将Sex数据类型转换
data_train['Sex'] = data_train.Sex.map(lambda x: 1 if x == 'male' else 0)
data_test['Sex'] = data_test.Sex.map(lambda x: 1 if x == 'male' else 0)
# 保存处理后的数据集
outputpath_train = 'Titanic_Dataset/train_after.csv'
data_train.to_csv(outputpath_train, sep=',', index=False, header=True)
outputpath_test = 'Titanic_Dataset/test_after.csv'
data_test.to_csv(outputpath_test, sep=',', index=False, header=True)
#准备数据集,此处采用MIni Batch-------------------------------------------------
# 参考链接:https://blog.csdn.net/Learning_AI/article/details/122460458?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-122460458-blog-129856546.235%5Ev43%5Epc_blog_bottom_relevance_base7&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-122460458-blog-129856546.235%5Ev43%5Epc_blog_bottom_relevance_base7&utm_relevant_index=2
class TitanicDataset(Dataset):
def __init__(self, filepath):
xy = pd.read_csv(filepath)
self.len = xy.shape[0]
feature = ["Pclass", "Sex", "Age", "SibSp", "Parch"]
# PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
# np.array()将数据转换成矩阵,方便接下来的计算
self.x_data = torch.from_numpy(np.array(pd.get_dummies(xy[feature])))
self.y_data = torch.from_numpy(np.array(xy["Survived"]))
def __getitem__(self, index): #使用索引拿到数据
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = TitanicDataset('Titanic_Dataset/train_after.csv') #文件名,相对路径
train_loader = DataLoader(dataset=dataset,
batch_size=1, #采用mini Batch的训练方法
shuffle=True, #是否打乱数据:是
num_workers=0)
#设计自己的模型------------------------------------------------------------------
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(5, 3) #降低输出(中间值)维度
self.linear2 = torch.nn.Linear(3, 1) #降低输出维度
self.sigmoid = torch.nn.Sigmoid() #线性→非线性 的函数(有多种,可以尝试采用其他种)
#前馈
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x)) #注意这种写法,一直使用x ,x的值一次次改变,此处不用中间值,避免引用出错
return x
#测试函数
def test(self, x):
with torch.no_grad():
x=self.sigmoid(self.linear1(x))
x=self.sigmoid(self.linear2(x))
y=[]
#根据二分法原理,划分y的值
for i in x:
if i > 0.5:
y.append(1)
else:
y.append(0)
return y
model = Model() # 实例化模型
#构造损失函数和优化器----------------------------------------------------------
criterio = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#训练周期--------------------------------------------------------------------
#防止Windows系统报错
if __name__ == '__main__':
#采用MiniBatch的方法要采用多层嵌套循环
for epoch in range(100):
for i, data in enumerate(train_loader, 0): #data从train_loader中取出的数据是一个元组(x,y)
#1、Prepare data
inputs, survivals = data
inputs = inputs.float()
survivals = survivals.float()
#2、Forward
y_pred = model(inputs)
y_pred = y_pred.squeeze(-1)
loss = criterio(y_pred, survivals)
print(epoch, i, loss.item())
#3、Backward
optimizer.zero_grad()
loss.backward()
#4、Update
optimizer.step()
# 测试
test_data=pd.read_csv('Titanic_Dataset/test_after.csv')
feature = ["Pclass", "Sex", "Age", "SibSp", "Parch"]
test = torch.from_numpy(np.array(pd.get_dummies(test_data[feature])))
y=model.test(test.float())
# 输出预测结果
output=pd.DataFrame({'PassengerId':test_data.PassengerId,'Survived':y})
output.to_csv('Titanic_Dataset/my_predict.csv',index=False)
四、卷积神经网络CNN
PyTorch实现MINIST数据集训练,采用GPU加速
代码如下:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
# 准备数据集
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(), # convert PIL image to Tensor
transforms.Normalize((0.1307, ), (0.3081 ))
])
train_dataset = datasets.MNIST(root='CNN_Dataset/minist/',
train=True,
download=False, # True, 第一次,无数据集,自动下载
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='CNN_Dataset/minist/',
train=False,
download=False, # True, 第一次,无数据集,自动下载
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
# 设计自己的模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320,10) # 此处输入值320可以根据卷积过程自己计算,也可以在全连接之前进行代码输出
def forward(self, x):
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) # 此处自动计算出的是320
# print("x.shape= ",x.shape)
x = self.fc(x)
return x
model = Net() # 模型实例化
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device) # 使用GPU
# 构造损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 训练周期
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# Forward
outputs = model(inputs)
loss = criterion(outputs, target)
# Backward
loss.backward()
# Update
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss/2000))
running_loss = 0.0
# 测试
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
_,predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
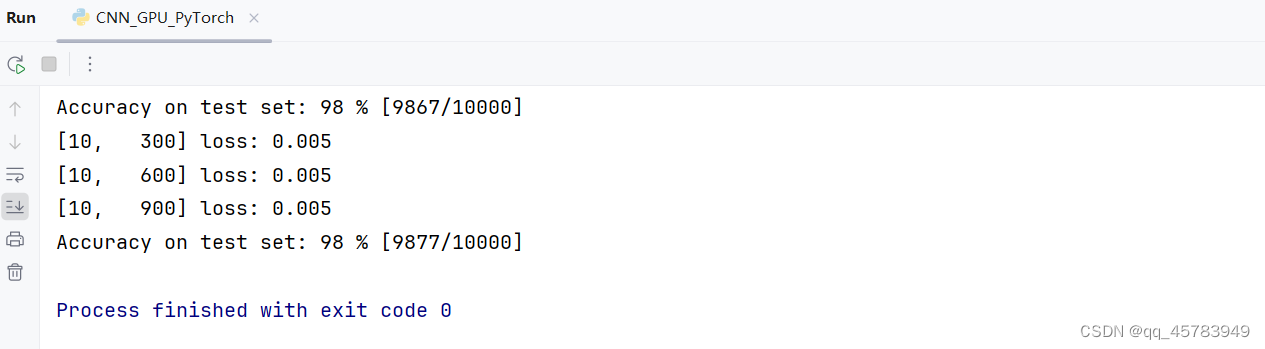
print('Accuracy on test set: %d %% [%d/%d]' % (100 * correct / total, correct, total))
if __name__ == '__main__':
epoch_list = []
acc_list = []
for epoch in range(3):
train(epoch)
acc = test()
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list, acc_list)
plt.ylabel('Accuracy')
plt.xlabel('epoch')
plt.show()
此处并未实现图像绘制,错误如下:“OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.”
解决方法参考链接:https://blog.csdn.net/zhuma237/article/details/128271897















 527
527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









