








实例:
网络结构:
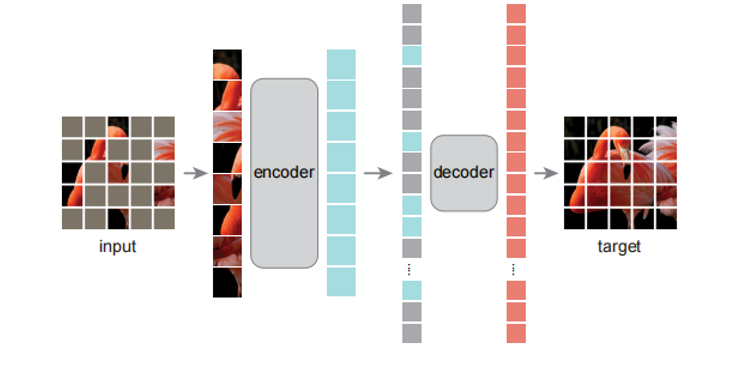
掩码自动编码器(MAE)是一种Denoising Auto encoder,它可以重构原始信号。像所有的Auto encoder一样,MAE利用编码器将观察到的信号映射到一个潜在的表示,再利用解码器,从潜在的表示重构原始信号。
MAE模型架构基于两个核心设计:
首先,提出了一个非对称的编码-解码结构,encoder只对未掩盖的patch部分的子集进行操作;然后通过一个轻量级的decoder从潜表示和mask token对图像进行重建。
其次,会掩盖大部分输入图像(高达75%),以此减少冗余,依旧能获得有意义的自监督结果。
Encoder端:
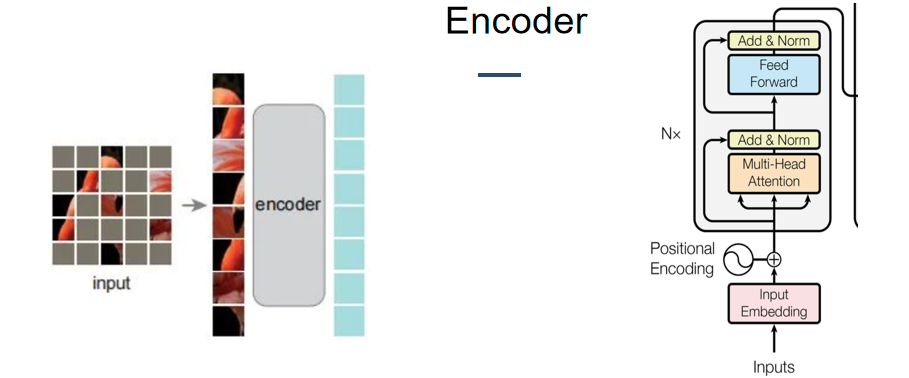
同样,编码器结构也是利用ViT进行搭建,但不同的是,MAE的编码器只应用于可见的(没有隐蔽)的patch,将可见的patch进行token embbeding,然后通过一系列的Transformer块的处理。由于encoder端接收可见的patch 允许我们只用一小部分的计算和内存来训练非常大的编码器。
Decoder端:

Decoder同样也是由多个Transformer块组成的。与Encoder不同的是,Decoder输入是由完整的patch组成,即visible token和mask token。每一个mask token都是一个需要学习的向量。 而后再将位置编码positional embedding 加入到patch当中,表示每个token在图片中的位置信息。最后通过一系列的Transfomer块处理。
Decoder模块只存在于预训练的重建图像任务中,因此可以独立于encoder去设计decoder,文中采用轻量级的decoder,即Transformer块的数量更少
Reconstruction:
MAE通过预测每个掩码块的像素值进行原始信息重建 。解码器的最后一层为线性投影,其输出通道数等于每个块的像素数量。编码器的输出将通过reshape构建重建图像。损失函数则采用了MSE,注:类似于BERT仅在掩码块计算损失。
Experiment:
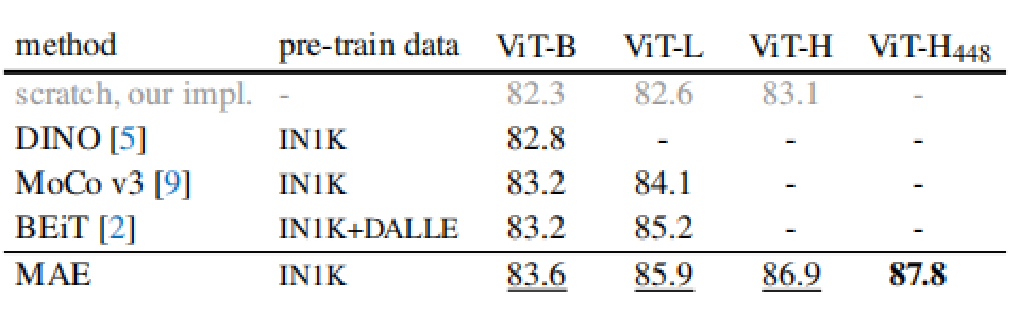
 MAE可以较为轻易的扩展到更大模型并具有稳定的性能提升
MAE可以较为轻易的扩展到更大模型并具有稳定的性能提升
个人测试结果:



















 3548
3548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









