








-CVPR 2022
-实例:

Image Inpainting任务中,建立像素远距离相互作用,建立上下文信息之间的关系尤为重要。但现有的工作存在以下问题:
①堆叠卷积层来扩大感受野。这种方法在重纹理图像(森林,水)上表现得很好,但在结构复杂的图像上则表现不佳。
②注意力模块进行远距离建模。由于计算能力有限,注意力模块只在小尺寸特征上进行应用,远距离建模没有充分利用。
③Transformer远距离建模。受复杂度影响,现有Transformer只能通过恢复低分辨率图像进行结构预测。
本文贡献:
①提出一种新的框架Mask-aware Transformers(MAT),处理高分辨率图像。
②提出多头上下文注意力模块,只对有效的token进行计算。
③提出改进的Transformer block,提高训练稳定性。
④提出风格操作模块,使得修复结果多元化。
网络结构:
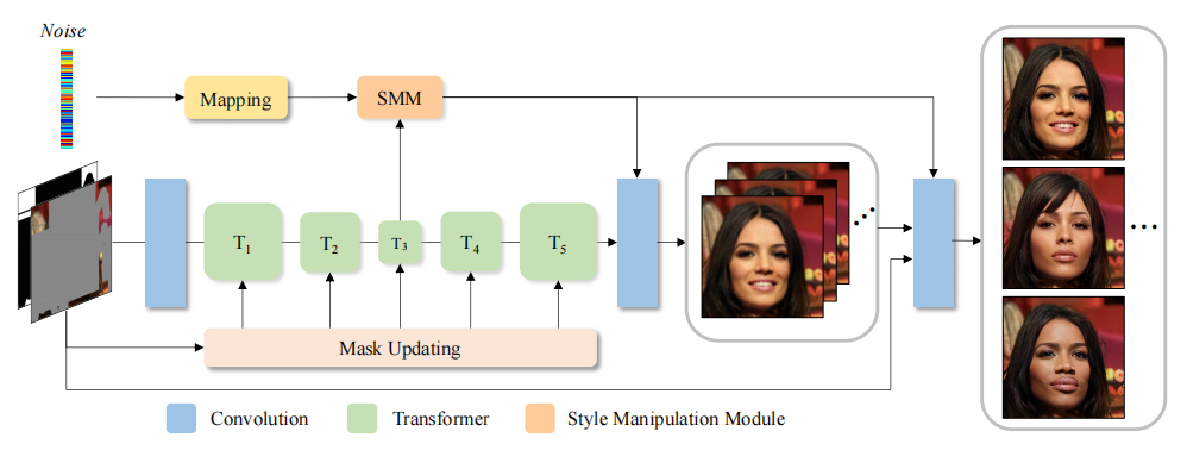
整体结构由 卷积头、Transformer Body、卷积尾和风格操作模块组成。 结合了卷积和Transfomer的优点,对图像进行修复。
-卷积头:
卷积头主要由四个卷积层构成,其中一个卷积层用于改变输入的维度,其他三个卷积层进行下采样操作。以此产生原图八分之一大小分辨率大小的特征图用作输入Transforer块的Tokens。 使用卷积头的两个原因: ①使用卷积层加入局部归纳先验 ②下采样以降低计算成本
-Transformer Body
①改进的transformer 块
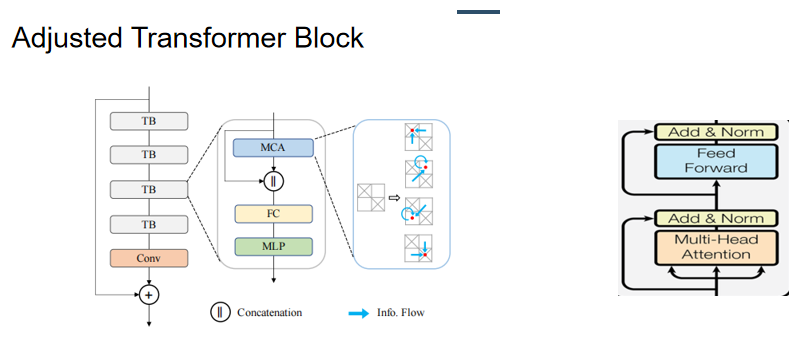
① 删除Layer Normalization层归一化:在大面积缺失的情况下,大部分的token是无效的,层归一化会放大这些无效token
②删除残差连接,改为concat:残差连接鼓励模型学习高频信息,在训练初期,没有低频的基础,很难直接学习高频细节。
②多头上下文注意力模块
利用动态掩模版的方式,只对有效的token进行计算,该部分可表示为:
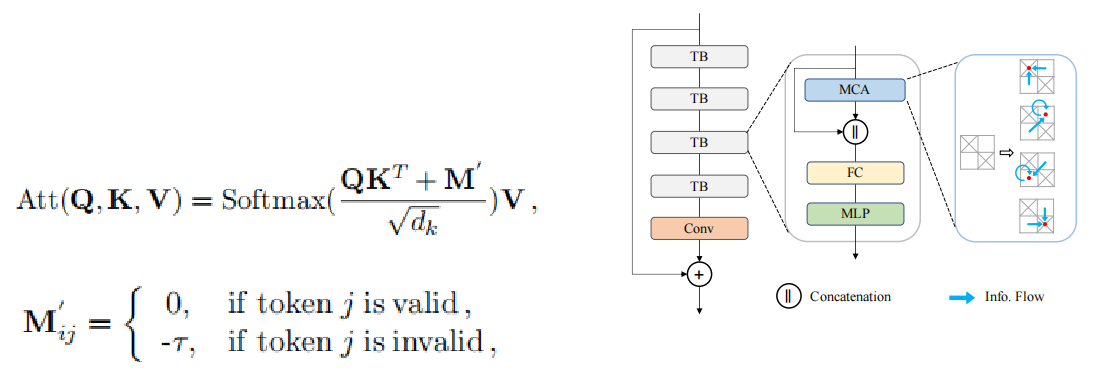

动态掩模版的更新方式:
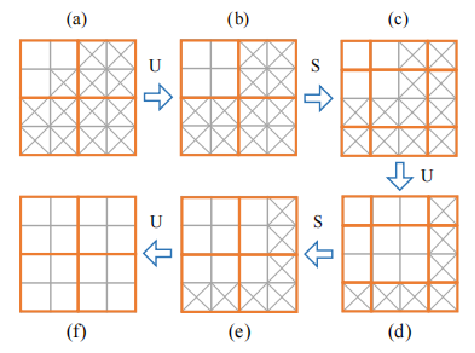
更新规则: 只要当前窗口有一个token是有效的,经过注意力后,该窗口的所有token都会更新为有效的。 如果一个窗口中的所有token都是无效的,经过注意力后,他们仍然无效。
③Style Manipulation Module
SMM通过额外的噪声输入以及改变卷积层的权重归一化来操作输出。为了增强噪声输入的表示能力,图像的条件风格从图像特征X和噪声中进行学习。
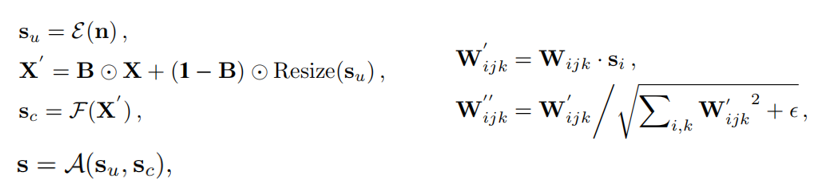
-Loss Function
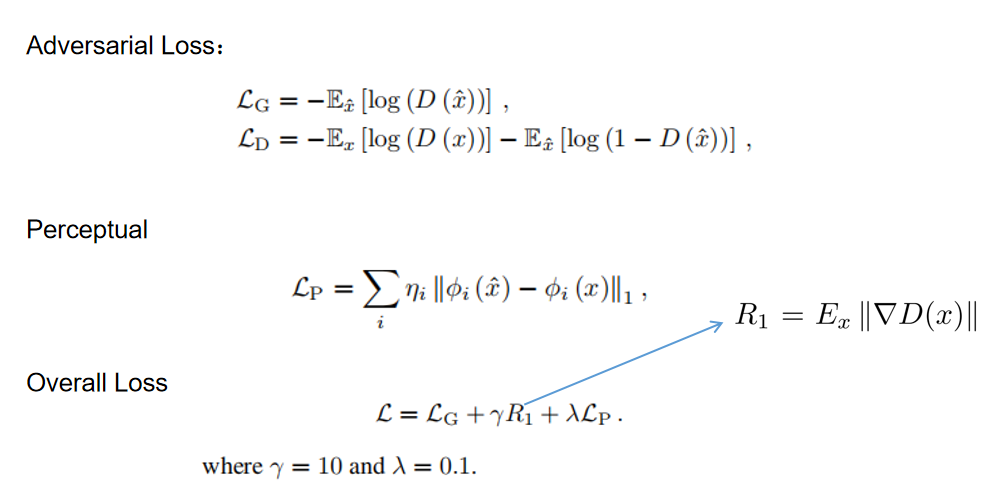














 2196
2196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









