








-cvpr2023
-当前attention机制存在的问题:
①利用im2col方式计算local attention 需要消耗很大的计算资源
② window attention存在固定的设计模式,如窗口应该如何移动,引入人工干涉。
-Method
-.Shift as Depthwise Convolution
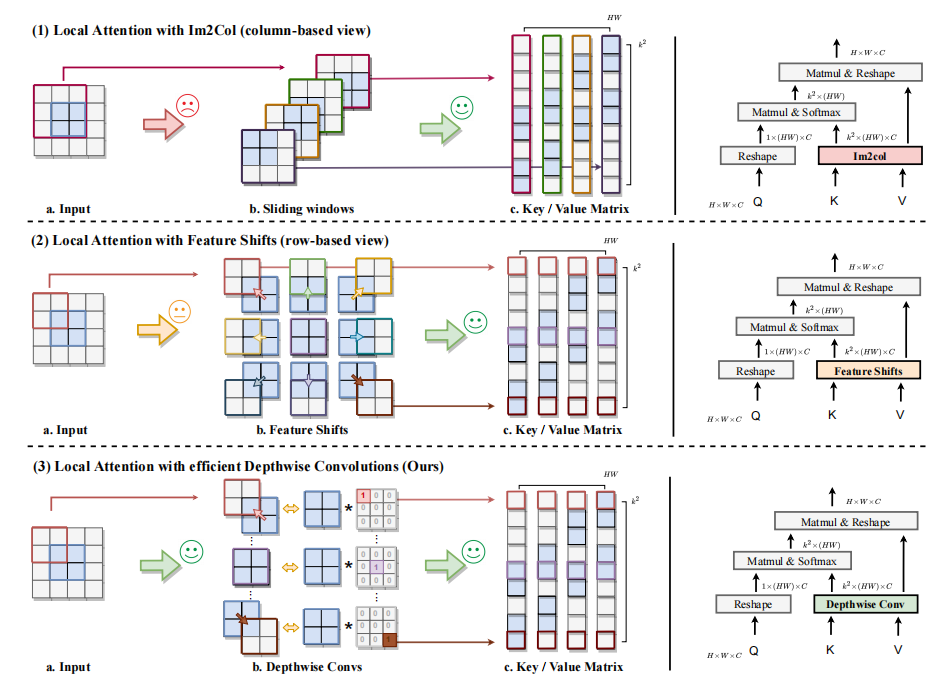
作者首先从新的角度上剖析了im2col的原理,并用深度卷积重新实现local attention 机制。
①im2col实现的local attention:以2*2的特征图为例,先进行padding,而后通过3*3的滑动窗口得到H*W个窗口值,再进行展平,得到键值对。
②feature shift实现的local attention:以2*2的特征图为例,按照左上,上,右上,左,中,右,左下,下,右下的方式移动特征图窗口。得到九个不同的特征,再生成键值对。
③作者提出的利用Depthwise实现的local attention:以2*2的特征图为例,先进行padding,而后通过不同的固定权重的3*3的窗口得到九个不同的特征,再生成键值对。
-Deformed Shifting Module
通过将原来的 Im2Col 函数切换为 depthwise convolutions,局部注意力的效率得到了极大的提升。尽管如此,精心设计的内核权重仍然将键和值限制在固定的相邻位置,这可能不是捕获不同特征的最佳解决方案。因此,本文提出了一种新颖的可变形移位模块,以进一步增强局部注意力的灵活性。具体来说,我们在 shiftwise 卷积中利用设计范例,并引入并行卷积路径,其中内核参数在训练过程中随机初始化和学习。与将特征向不同方向移动的固定核相比,可学习内核可以解释为所有局部特征的线性组合。这类似于可变形卷积网络 中的不规则感受野。
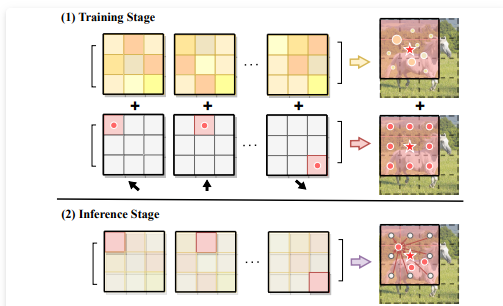
①局部注意力中的键值对是利用一个更灵活的模块来提取的,该模块可以提高模型的容量和捕获更多样性的特征。
②可学习的卷积核与DCN中的可变形技术很相似。类似于DCN中四个相邻像素的双线性插值,我们的变形移位模块可以看作是局部窗口内特征的线性组合。这最终有助于增强空间采样位置和模型输入的几何变换。
③使用重新参数化技术来将这两条并行路径转换为一个单一的卷积。这样,我们就可以在保持推理效率的同时提高模型的计算能力














 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









