







本文是发表于ICCV 2023的一篇文章,主要是讲述实现图像生成中对象级形状变化。
论文源地址 https://doi.org/10.48550/arXiv.2303.11306
论文在GitHub地址:orpatashnik/local-prompt-mixing (github.com)

一、Intorduction
在这部分里,首先就是说基于扩散模型的图像生成在目前无论是质量还是多样性上都有了很出色的表现,但是在可控的图像生成上还需要提高。然后提到了文本到图像模型在生成图像时的全局性质限制了用户对特定对象的探索能力。然后,论文介绍了一种通过混合不同的提示来生成具有形状变化的对象集合的技术。该技术可以在保持对象语义的前提下,对生成的对象形状进行控制。此外,论文还提出了两种使用自注意力层和交叉注意力层的定位技术,以实现对图像空间操作的定位。最后,论文通过广泛的实验和比较,展示了该方法在生成对象变化和定位技术方面的有效性。
二、Related Work
Localizing Prompt Mixing (orpatashnik.github.io) 这部分主要就是讲了基于文本的图像生成、编辑方面的一些工作。
三、Preliminaries
这部分首先讲了潜在扩展模型的相关内容,因为论文是在开源的stable-diffuison上开展的工作,而stable-diffusion又是基于潜在扩散模型实现的。
然后讲述了自注意力机制和交叉注意力机制在LDM中的应用以及它们的功能。
四、Prompt-Mixing
这部分主要讲述的就是论文的核心方法:提示混合。为了生成对象级的变化,论文提出了一种在推理时间内操作的方法,不需要任何的优化或者模型训练。只需要给定文本提示P以及单词w表示的感兴趣对象,然后操纵去噪过程从而实现改变对象的形状。
具体实现是论文将整个去噪过程定义成了三个时间步长间隔,[T,T3],[T3,T2],[T2,0],并且在每个间隔中使用不同的提示指导去噪过程。

上图清晰的表现了这个方法,左边三幅图是使用一个提示来生成的图像,右边两幅图是使用多个提示混合生成的图像。下方的颜色对应了在某个去噪间隔中使用的对应提示词。
从图中我们可以很好的看出,在三个去噪间隔中,第一个间隔[T,T3]控制图像布局,第二个[T3,T2]控制对象的形状,第三个[T2,0]控制精细的视觉细节(例如,纹理)。
五、Attention-Based Shape Localization
在去噪过程中,由于我们只想改变特定对象的形状,所以我们必须保证其他的对象的形状没有发生变化,所以作者在这里用了一个基于注意力机制的形状定位技术。

具体实现如上图,首先通过自注意力机制生成注意力图,然后将图像分割成语义分割图,然后利用交叉注意力机制来将每个分割区域与输入提示中的名词进行匹配,以确定每个分割区域的标签。最后,利用这些标签来选择性地保留或修改图像中的对象。
六、Controllable Background Preservation
为了实现可控的背景保留,论文中主要也是利用注意力机制来实现图像背景的保留,简而言之就是利用注意力机制来对图像进行语义区域分割,然后根据输入提示中的名词来确定每个区域的标签,最后选择性地混合原始图像和生成图像,以实现对图像生成过程的更精细的控制,如此就可以使得新生成的图像与原始图像的背景保持一致。

七、 Overall framework

上图是整个工作的框架图,依据我自己的理解来说:
首先论文给了两个噪声的去噪过程,上面的是原始图像的去噪过程,而下面是混合提示生成图像的去噪过程,之所以要给出原始图像的去噪过程主要是提供参考以及后续实现形状定位、背景保留所用。
然后我们按照去噪时间间隔来讲述,以图中给的为例,在第一个间隔[T,T3]中,主要是控制图像布局,这里所输入的提示词没有发生变化,都是basket。然后第二个间隔[T3,T2]中,主要控制对象的形状,这里将提示词从basket改成了tray,从而改变了图像的生成,这个阶段以及[T2,T1]阶段,都利用了基于注意力的形状定位来实现对其他的对象的形状保留。第三个[T2,0]间隔,主要是控制精细的视觉细节,这里实现了可控的图像背景保留,也就是利用注意力机制和图像分割技术来实现。最后将原始图像和新生成的图像根据语义分割区域来选择性的融合,从而实现图像背景的保留生成改变形状后的图像。
八、Experiments
这里主要讲一下Figure 10.
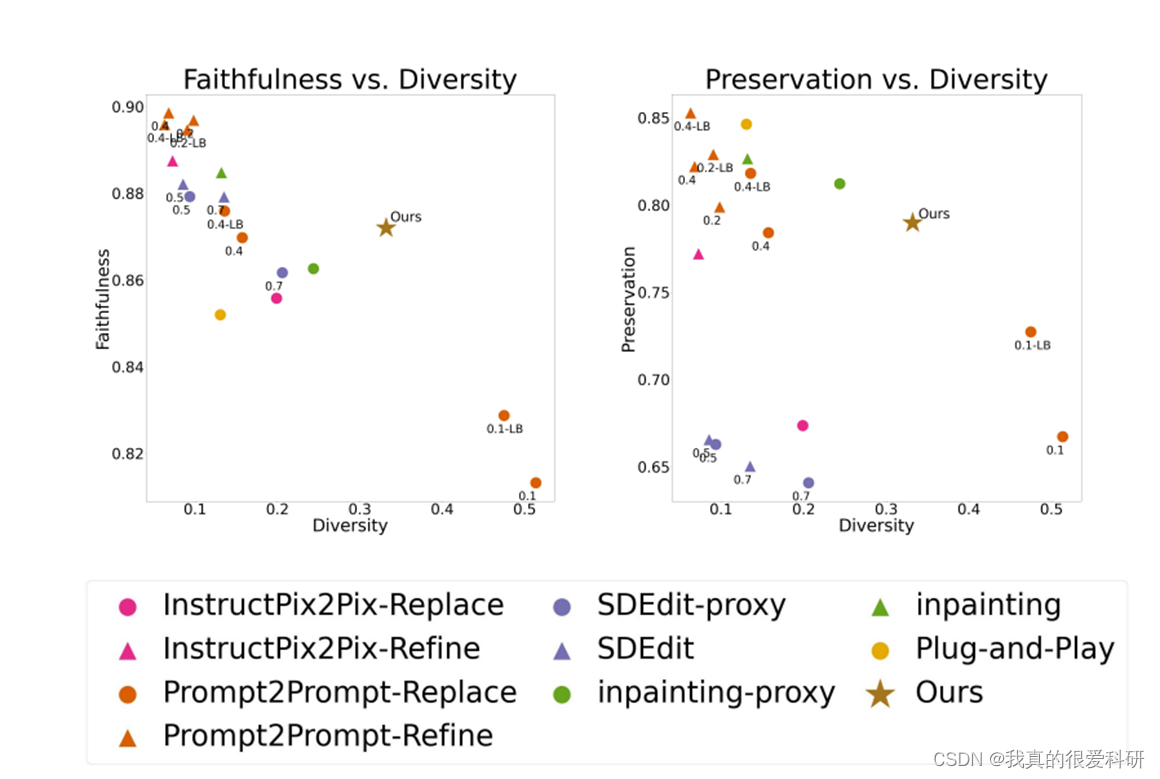
图10主要是将论文所提的方法与其他方法在三个性能指标上进行了一个比较。
"diversity"(多样性)指的是生成的图像在形状上的差异程度,即生成的图像展现出多样的形状变化。"faithfulness"(忠实度)指的是生成的图像在保持对象类别和语义方面的准确程度,即生成的图像能够忠实地表现出特定对象的类别和语义。"image preservation"(图像保持)指的是生成的图像在保留原始图像背景和其他对象方面的能力,即生成的图像能够有效地保持原始图像的背景和其他对象。
从图中我们可以很好的看出论文所提出的这个方法可以在多样性、忠实度以及保留性之间有一个很好的平衡。
















 1698
1698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











