







本文发表于CVPR 2024,其主要的内容是在stable diffusion上实现个性化图像生成

一、Introduction
传统的个性化方法通常通过优化文本嵌入或扩散模型参数来生成独特的视觉表示,但这些方法往往无法准确模仿主题的外观。为了克服这一问题,近期的研究工作采用大规模数据集训练T2I模型以增强表现力,但需要大量文本图像对进行训练。为了解决这一挑战,可以使用主题驱动的图像编辑技术,通过自注意模块调节参考图像以在生成过程中与目标匹配。然而,关键观察结果表明,用参考键替换目标键会影响生成模型的结构路径,导致无法有效匹配。为了解决这个问题,ViCo提出了一种结合调整模型权重子集和键值替换的方法,但需要独特的调优过程。
本文提出一种名为DreamMatcher的插件方法,旨在实现将参考外观有效地转移到目标结构上,同时产生不同的结构。DreamMatcher专注于自我注意模块中的外观路径,通过匹配感知的值注入来实现个性化,并确保结构路径保持不变。为了解决替换值可能导致结构外观不对齐的问题,作者提出了一种匹配感知的值注入方法,利用语义对应来对齐目标结构的引用外观。另外,为了保留目标的其他结构元素,如遮挡对象或背景变化,引入了语义一致的掩蔽策略。通过正确对齐的参考外观只通过自我注意模块集成到目标结构中,可以实现个性化。作者还引入了一个采样指导技术,称为语义匹配指导,以提供更丰富的参考外观用于目标去噪过程。DreamMatcher与任何现有的T2I个性化模型兼容,无需培训或微调。在三个不同的基线上验证了该方法的有效性,结果表明DreamMatcher具有先进的性能。该方法在极端非刚性个性化场景下仍然有效,并在具有挑战性的个性化场景中展现出鲁棒性。消融研究证实了设计选择的有效性,并突出了每个组件的有效性。
二、Related Work
目前在实现个性化图像生成领域,主要有三种方向,分别是基于优化、基于培训和插件主题驱动的T2I个性化方法。
在基于优化的方法中,早期的技术主要集中在将给定概念封装在文本域中,通过优化文本嵌入生成个性化图像,如Textual Inversion和DreamBooth。一些工作专注于优化权重子集或附加适配器以提高效率和调节性能,例如CustomDiffusion和ViCo。尽管取得一定进展,这些方法通常无法准确模仿对象的外观。
基于培训的方法将重点放在训练具有大规模数据集的T2I个性化模型上,如Taming Encoder、InstantBooth和FastComposer。这些方法避免了微调问题,但需要广泛的预训练以获得良好的性能。
插件主题驱动的方法则致力于实现主题驱动的个性化或非刚性编辑,无需额外的微调或培训。例如,MasaCtrl利用双分支预训练扩散模型来合并图像特征,FreeU基于频率分析重新加权中间特征图,MagicFusion介绍了一种噪声混合方法。论文提出的DreamMatcher方法与这些插件方法一致,旨在与任何现有的T2I个性化模型兼容,无需额外的微调或培训。
三、Preliminary
这部分主要讲了Diffusion Model的基本原理以及自注意力模块,于U-Net架构中,主要包括残差块、交叉注意模块和自注意模块。残差块处理来自先前层的特征,交叉注意模块将这些特征与条件整合,例如,文本提示,自关注模块通过关注操作聚合图像自身特征。
四、Method

直接来看框架图 ,这个图可以被看做两部分,上半部分是输入的参考图像在stable diffusion中的扩散过程,下半部分是使用预训练的个性化扩散模型根据文本提示所得得个性化图像。
首先,利用预训练的扩散模型对输入的参考图像和文本提示提取特征提示符,然后对特征提示符进行语义匹配和一致性建模,得到参考图像和目标图像之间的像素级的位移信息Ft(XY),以及置信度图Ut。通过Ft(X
Y)可以更好的实现图像之间的对齐和匹配,而置信度图Ut,则是表示图像匹配的可靠性和准确程度的。
然后,利用所得到的Ft(XY)以及Ut,结合前景掩码Mt,将参考图像自注意力块中的参数更新到目标图像自注意力块中,也就是论文中所提出的AMA方法,最后为了能够更好的生成图像,论文提出了语义匹配引导技术,这个语义匹配引导技术不但利用了先前所得的Ft(X
Y)、Ut以及Mt,还利用了参考图像最后的潜在向量Z0x以及经过重参数化后得到的在时间步t时,目标图像的潜在张量Z^0,t Y。通过语义匹配引导技术,从而更好的实现个性化图像的生成。
语义匹配引导技术的指导函数gt的具体计算原理如下(W表示扭曲操作):



然后我们详细的来看语义匹配和一致性建模以及AMA方法的详细内容:

上图是语义匹配和一致性建模的流程图,首先从预训练扩散模型中提取特征图描述符x,
y。然后计算匹配成本Ct+1;
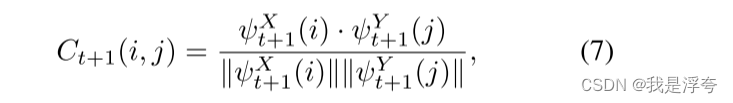
然后通过argmax操作得到参考图像和目标图像之间的像素级位移信息Ft(XY)和Ft(Y
X),最后通过循环一致性操作计算得到置信度图Ut。
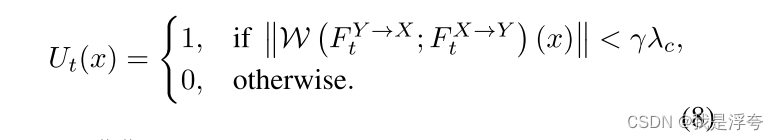
AMA方法:
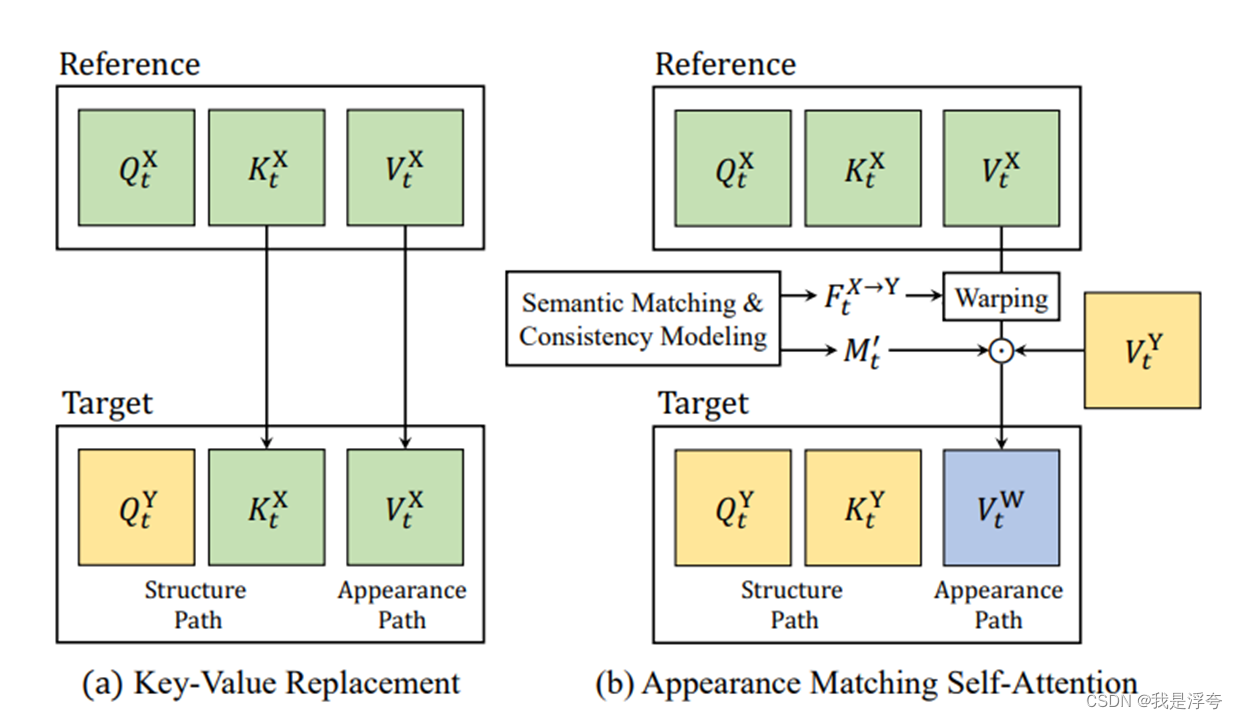
AMA方法与普通的键值替换不一样,它只需要更新V即可,但如果直接替换V,并不能达到很好的效果,因此论文中提到在替换时结合Ft(XY)以及Mt'来进行替换:
直接替换V的自注意力计算:

最终得到的自注意力计算:

五、Experiments
首先与三个Baselines进行比较:
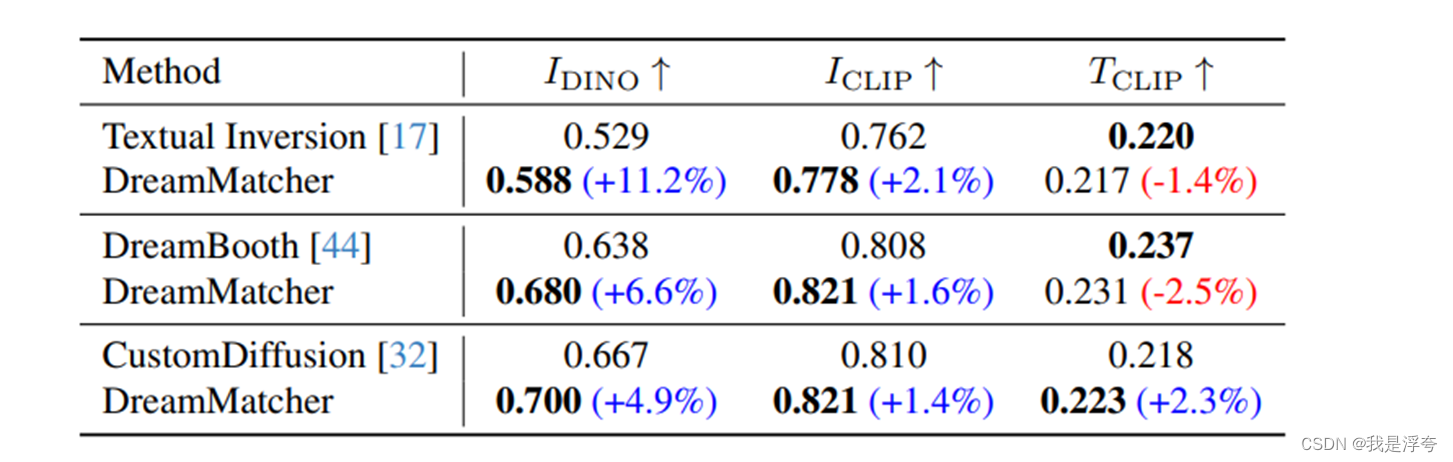
虽然在CLIP-T上有一定的下降,但是实际上它的表现是比较好的。

然后与一些通过其他方式实现个性化图像生成的方法进行比较:
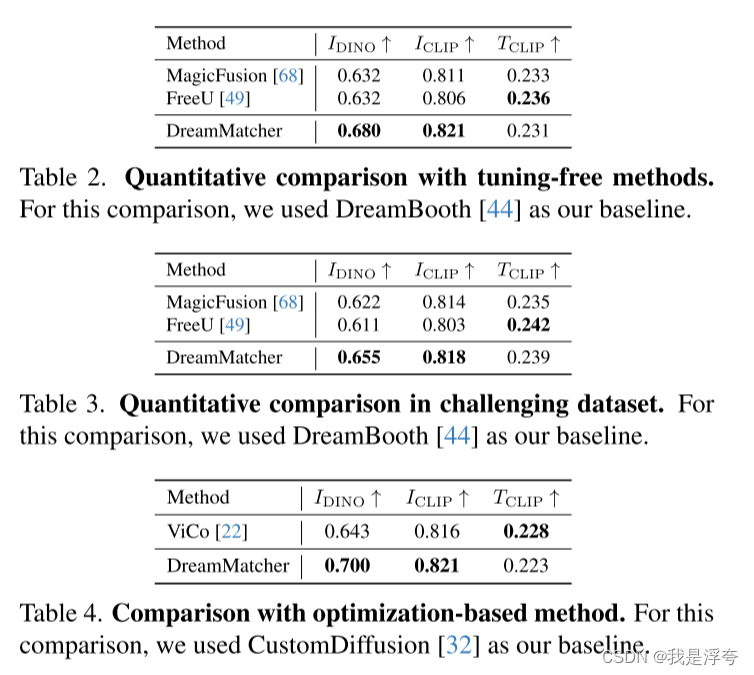 总体来说,论文所提出的这个DreamMatcher方法的效果是优于其他方法的。
总体来说,论文所提出的这个DreamMatcher方法的效果是优于其他方法的。

最后来看消融实验:
 这里,图片和表是对应的,所用的指标仍然是DINO-I、CLIP-I、CLIP-T。消融实验验证了论文所提出的三个组件的重要性,同时显现了DreamMatcher方法的优越性。
这里,图片和表是对应的,所用的指标仍然是DINO-I、CLIP-I、CLIP-T。消融实验验证了论文所提出的三个组件的重要性,同时显现了DreamMatcher方法的优越性。
















 2933
2933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











