






文章目录
摘要
本周,我通读了论文《ImageNet Classification with Deep Convolutional Neural Networks》。该文献的主要贡献是构建了一个深层神经网络架构,该架构具有几点创新之处。第一,通过减少参数量来加速训练;第二,提出了几种避免过拟合的措施;第三,使用ReLU激活函数取代了tanh和softmax。另外,我还深入学习了CNN的原理。CNN通过卷积和池化等操作,逐步减小图像尺寸,从而大大减少了参数量。总体而言,本周对CNN进行了深入剖析,这个过程让我受益匪浅。
ABSTRACT
This week, I thoroughly read the paper “ImageNet Classification with Deep Convolutional Neural Networks”. The main contribution of this paper is constructing a deep neural network architecture that has several innovations. First, it reduces the number of parameters to accelerate training. Second, it proposes several measures to prevent overfitting. Third, it uses the ReLU activation function instead of tanh and softmax. In addition, I studied the principles of CNN in depth. CNN gradually reduces image size through operations like convolution and pooling, thus greatly reducing the number of parameters. Overall, this week I gained deep insights into CNN through in-depth analysis, which benefited me tremendously.
一、文献阅读
1、题目
ImageNet Classification with Deep Convolutional Neural Networks
期刊:Communications of the ACM
论文链接:https://dl.acm.org/doi/10.1145/3065386
2、ABSTRACT
This article utilized a deep convolutional neural network for image classification and achieved excellent results. The deep convolutional network consists of 60 million parameters, 650,000 neurons, five convolutional layers, and three fully connected layers. GPU acceleration was employed to speed up the training process. Dropout, a regularization technique, was used to reduce overfitting.
这篇文章利用了一个深度卷积神经网络来进行图片分类,取得了一个非常好的效果。深度卷积网络由60million个参数,65w个神经元,以及五个卷积层和三个全连接层组成。为了加快训练,用到了GPU加速实现。用了dropout这个正则化方法来减少过拟合。
3、网络架构
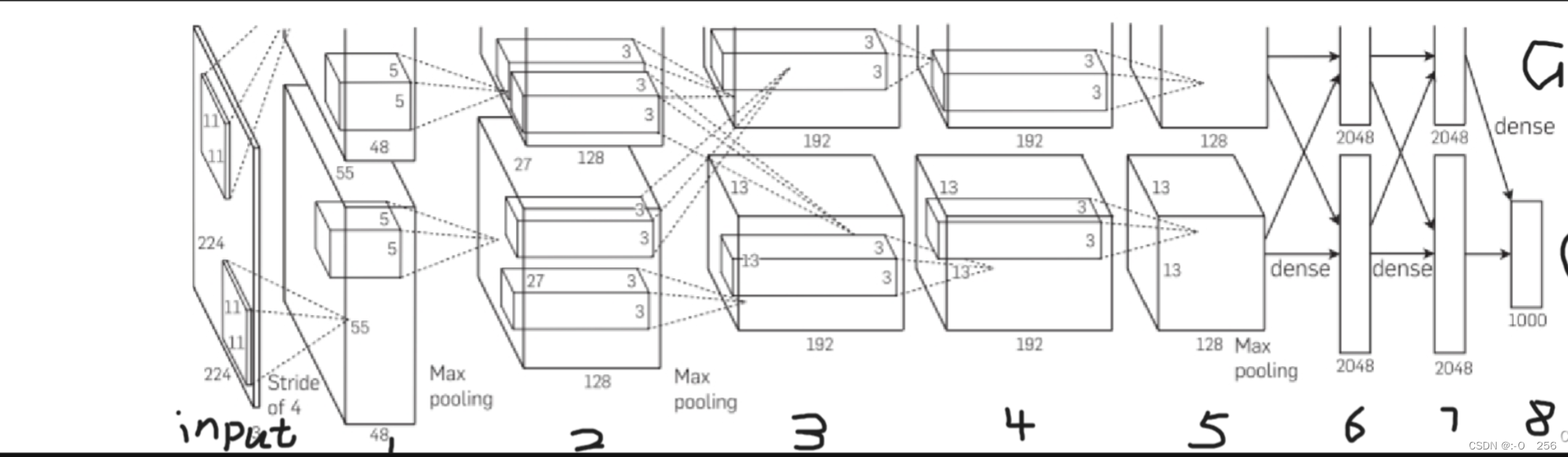
网络架构分为八个层,其中有五个卷积层和三个全连接层。
分析:
输入为224×224×3的图像
卷积层1的卷积核为11×11×3,strde=4,每个GPU内输出55×55×48,响应规范化,池化
卷积层2:256个卷积核,大小为5×5×48;响应规范化,池化
卷积层3,4:384个卷积核,大小为3×3×256;无池化
卷积层5:256个卷积核,大小为3×3×192
全连接层6,7:每个GPU内有2048个神经元,共4096个
全连接层8:输出与1000个softmax相连
输出:关于1000个类的分布
注:整个架构被分为2路来进行,分别为GPU1和GPU2。两者的架构层次是完全相同的。
4、文献解读
1、Introduce
文章主要任务就是利用深度卷积神经网络进行分类任务,作者首先确定使用CNN的架构,这样做减少了神经层之间的连接以及参数量,便于训练,且性能相比标准的具有相似尺寸大小的网络层的前馈神经网络只是轻微的下降。之后作者在框架中引入了几个设计,如ReLU的使用,数据集的扩增等等,提高了CNN网络的性能,还有就是GPU的使用硬性保证了大规模网络能够train起来。
2、创新点
1、使用ReLU函数替代softmax和tanh函数
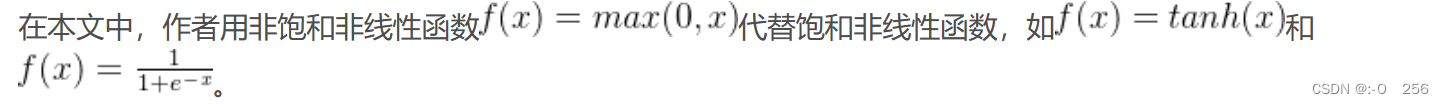
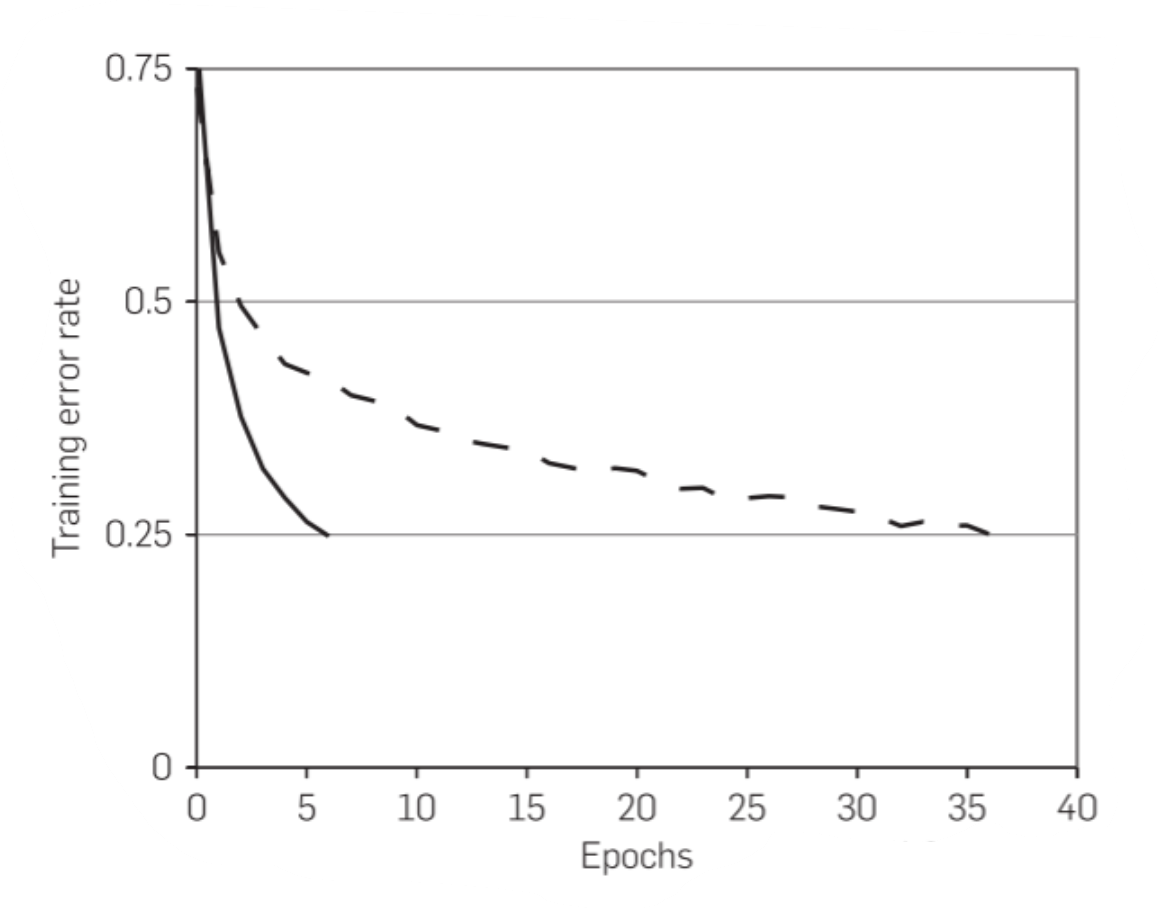
实线为用ReLU函数的误差下降率,虚线为tanh函数的误差下降率,从图中可以看出,用ReLU函数误差下降会比tanh函数快好多倍。
2、在多个GPU上训练
从网络框架图中我们可以看出,整个网络被分为两个来进行训练,然后把切完之后的网络用两个GPU来训练。
3、局部响应归一化
在ReLU层之前我们应用了normalization得到了一个更好的效果,文章中说,使用局部响应归一化比没有使用局部响应归一化的错误率要低%2左右。
局部响应归一化的好处:它的作用是对每个神经元的输出进行归一化,使得较大的响应值相对较小,较小的响应值相对较大。这样做的好处是可以抑制较大的响应,使得其他神经元的响应更加突出,从而增强网络对不同特征的敏感性。
4、重叠池化
一般来说两个pooling是不重叠的,但是这里采用了一种对传统的pooling改进的方式。文章中通过重叠池化,得出top-1和top-5错误率分别降低0.4%和0.3%。
3、实验过程
一、数据集
本文使用的数据集是ILSVRC-2010,LSVRC使用ImageNet的一个子集,1000个类别中的每个类别大约有1000个图像。总共大约有120万个训练图像、50000个验证图像和150000个测试图像。
由于实验数据中的图像是由可变分辨率的图像组成,所以我们在输入数据之前要先固定分辨率,所以我们就把所有的图像裁剪成256256的面片。具体裁剪方法:先对原始图片进行缩放,将短边变成256的大小,另一个长边在这一步操作中也会根据长宽比进行调整,然后第二步从图片中心对长边进行两侧的裁剪,得到256256的尺寸大小。
二、评估指标
ImageNet通常用两个指标来代表错误率:top-1和top-5。top-5表示正确标签不在网络模型认为的最有可能的五个标签内的比例。
三、实验数据
1、ILSVRC-2010测试集的结果比较。
一、数据集
本文使用的数据集是ILSVRC-2010,LSVRC使用ImageNet的一个子集,1000个类别中的每个类别大约有1000个图像。总共大约有120万个训练图像、50000个验证图像和150000个测试图像。
由于实验数据中的图像是由可变分辨率的图像组成,所以我们在输入数据之前要先固定分辨率,所以我们就把所有的图像裁剪成256256的面片。具体裁剪方法:先对原始图片进行缩放,将短边变成256的大小,另一个长边在这一步操作中也会根据长宽比进行调整,然后第二步从图片中心对长边进行两侧的裁剪,得到256256的尺寸大小。
二、评估指标
ImageNet通常用两个指标来代表错误率:top-1和top-5。top-5表示正确标签不在网络模型认为的最有可能的五个标签内的比例。
三、实验数据
1、ILSVRC-2010测试集的结果比较。

从图中可以看出,本文所用的模型CNN的表现结果要比之前最优的模型的表现结果还要好。
2、ILSVRC-2012验证集和测试集的错误率比较。
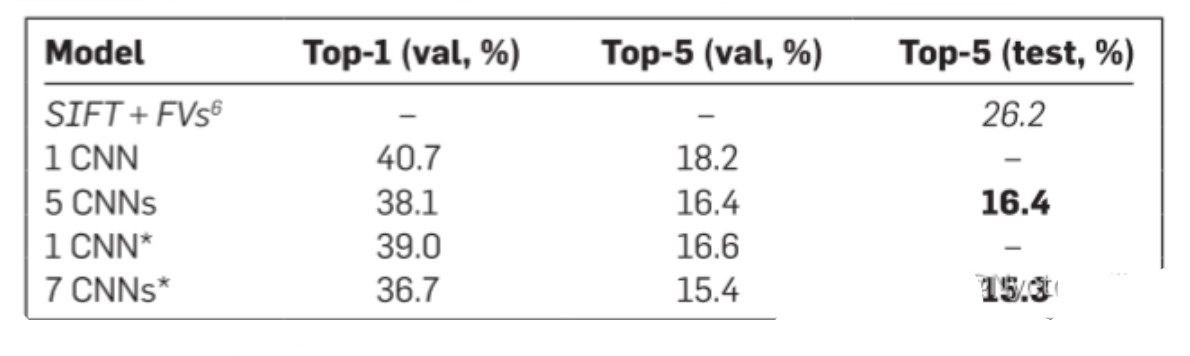
文章中作者做了很多组相似网络的实验 ,因为测试集不公开,但测试集与验证集数据接近,所以1 CNNs和 1CNN*用验证集的数据来表示
1 CNN是本文描述的模型,5 CNNs是五个相似CNN的预测平均值,1 CNNs是在1CNN基础上,在最后一个池化层后接了一个新的卷积层(第六层卷积层),用整个ImageNet Fall 2011 release训练(15M images 22K categories)然后在ILSVRC-2012上进行"fine-tuning"的结果,7 CNNs* 两个在Fall 2011上与训练的模型和5CNNs的预测平均值。
四、超参数的设定
我们使用随机梯度下降训练我们的模型,批量大小为128个示例,动量为0.9,权重衰减为0.0005。
初始化参数:用均值为0 ,方差为0.01的高斯随机变量去初始化了权重参数
学习率:我们在所有层上使用相同的学习率,设为0.01。但验证误差不降的时候我们就手动的乘以0.1,也就是降低十倍。也有自动的方法,例如Resnet,训练120轮epoch,初始学习率也是设为0.01,每30轮降低十倍,本文是训练了90个epoch,每一次是120w张图片。
4、Discussion
1、如何防止过拟合?
神经网络架构有6千万个参数,但这被证明不足以在没有相当大的过拟合的情况下学习如此多的参数,那么文章中是如何做到防止过拟合的呢?
1.1、数据增强
减少图像数据过度拟合的最简单也是最常见的方法是使用保留标签的变换人为地放大数据集。这里用了两种方式:
1、通过从256×256图像中随机提取224×224的图像,并在这些提取的图像上训练我们的网络来实现这一点。这将使我们的培训集的规模增加了2048倍。但是有个问题也不能说就是2048倍,因为很多图片都是相似的。
2、采用PCA的方式对RGB图像的channel进行了一些改变,使图像发生了一些变化,从而扩大了数据集。
1.2、Dropout
随机的将隐藏层的输出以50%的概率设为0,相当于一个L2的正则化,只不过用了这种方式实现了L2正则化的功能。
5、结论
我们的研究结果表明,一个大型的深度CNN能够使用纯粹的监督学习在一个具有高度挑战性的数据集上实现破纪录的结果。值得注意的是,如果删除单个卷积层,我们的网络性能会下降。例如,移除任何中间层导致网络的前1个性能损失约2%。因此,深度对于实现我们的结果非常重要。
二、深入学习CNN
一、神经网络基本结构
一个最简单的神经网络由输入层、隐含层以及输出层组成,其中每一层都包含多个神经元,上一层的神经元经过激活函数映射到下一层神经元,每个神经元之间都有相应的权值,输出的就是我们的分类类别。
二、前向传播与反向传播数学推导
如果我们有一个这样的网络层:
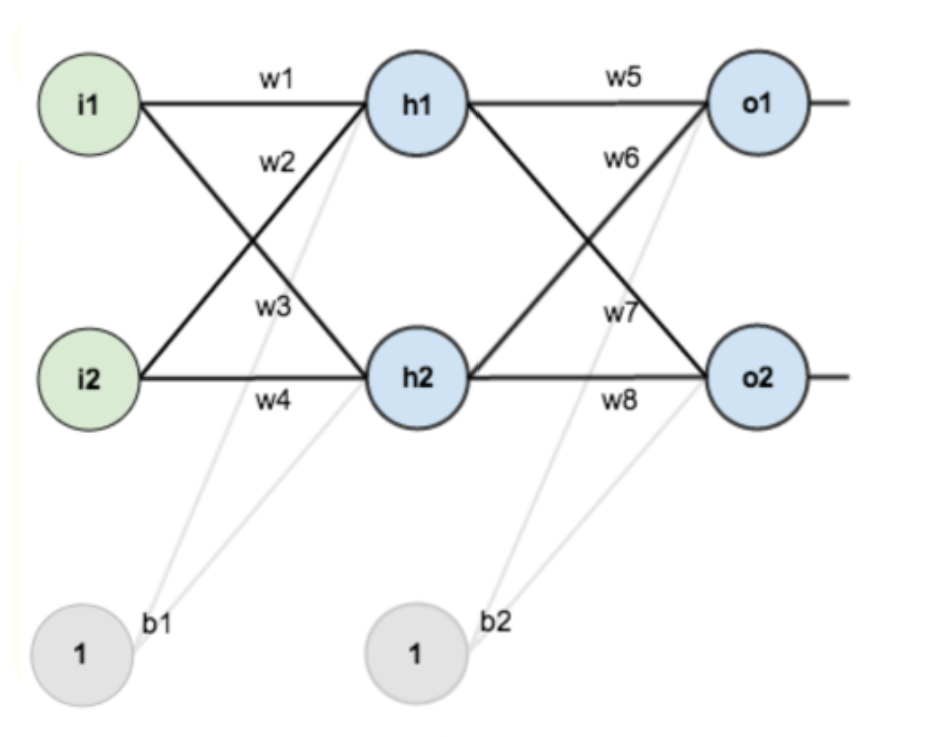
其中第一层是输入层,包括两个神经元i1和i2以及截距项b1;第二层是隐含层h1,h2以及截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。
如果我们对上述图像中的每一个未知参数赋值:
输入数据 i1=0.05,i2=0.10;
输出数据 o1=0.01,o2=0.99;
初始权重 w1=0.15,w2=0.20,w3=0.25,w4=0.30;
w5=0.40,w6=0.45,w7=0.50,w8=0.55
目标:给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
step1:前向传播

经过前向传播后,我们得出o1和o2的值分别为1.10590、0.77292,但是这与实际值0.01以及0.99还相差很远。所以我们要对误差进行反向传播,更新权重,重新计算输出。
Step2 反向传播

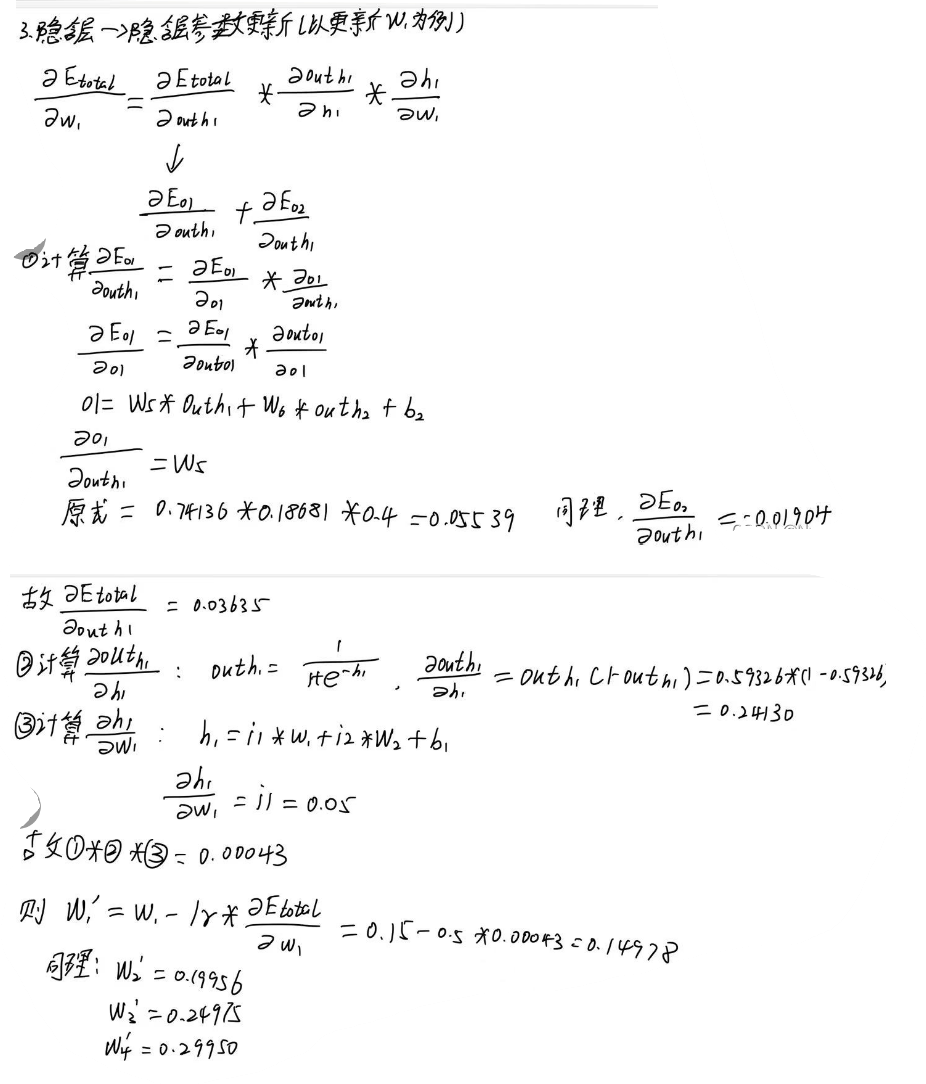
以上就是方向传播的具体步骤,经过反向传播,可以有效地使误差变小,并且可以使得预测值与实际值越来越接近。
总结
为什么要使用卷积神经网络?
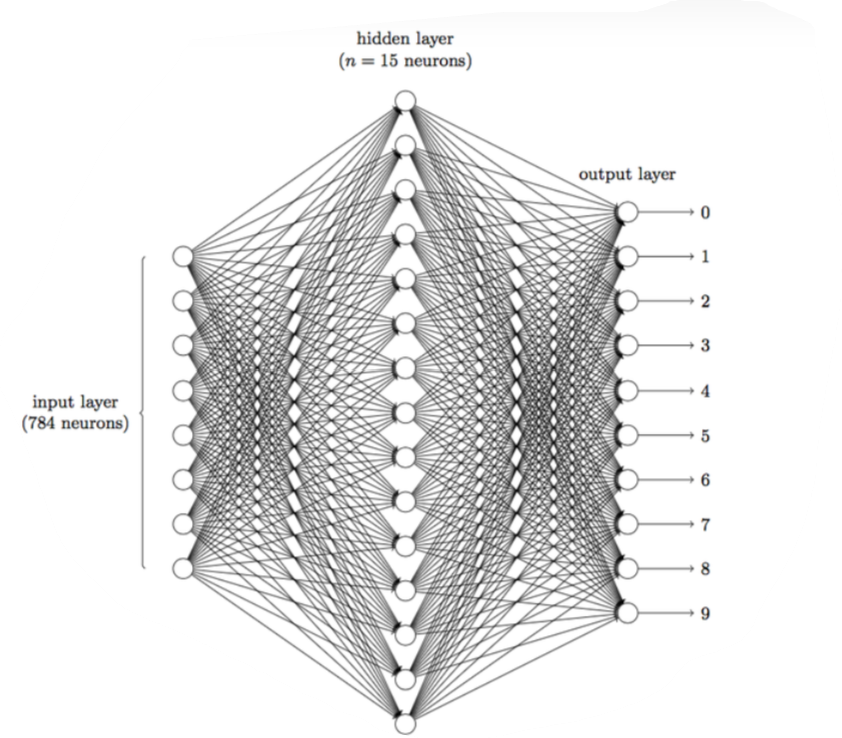
首先在图像领域,使用传统的神经网络并不合适,图像是由一个个像素点构成,每个像素点有三个通道,分别代表RGB颜色,比如说一个图像的尺寸是(1,28,28),它的含义是通道数channel为1,长宽分别为28的图像,也就是黑白图像。如果使用全连接神经网络的话,网络中的神经元与相邻层上的每个神经元均连接,那就意味着我们的网络有2828=784个神经元,隐含层如果用15个神经元的话,我么我们需要的未知参数w和b的数量就要有:78415+15*10+2=117,752个参数,这个参数太多了,随便进行一次反向传播计算量都是巨大的,从计算资源和调参的角度都不建议用传统的神经网络。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









