






文章目录
摘要
这周阅读了一种基于扩散模型的无噪声模型高光谱图像去噪方法论文,扩散模型是一种常用的图像去噪方法,它在去除噪声的同时保持图像的细节和边缘信息。无噪声模型高光谱图像去噪是指对高光谱图像进行去噪处理,以减少由于传感器噪声、环境干扰或其他因素引起的图像噪声。无噪声模型高光谱图像去噪的基本思想是通过对高光谱图像中的每个像素点进行扩散来减少噪声。扩散模型基于偏微分方程,使用图像的梯度信息来控制噪声的扩散过程。它通过将像素点的值与其周围像素点的差异进行比较,来决定噪声的传播方向和速率。在无噪声模型高光谱图像去噪中,通常使用的扩散模型是基于非线性扩散方程(Nonlinear Diffusion Equation,NDE)。NDE可以通过改变扩散系数来控制噪声的扩散速率,从而实现去噪效果。较小的扩散系数可以减缓噪声的扩散,从而保留图像的细节信息。
ABSTRACT
This week I read a paper on a noiseless model hyperspectral image denoising method based on diffusion model.Diffusion model is a commonly used image denoising method, which removes noise while preserving image details and edge information. Noiseless model hyperspectral image denoising refers to the denoising of hyperspectral images to reduce image noise caused by sensor noise, environmental interference or other factors. The basic idea of noiseless hyperspectral image denoising is to reduce noise by diffusing each pixel in the hyperspectral image. The diffusion model is based on the partial differential equation and uses the gradient information of the image to control the diffusion process of noise. It determines the direction and rate of noise propagation by comparing the value of a pixel with the difference between its surrounding pixels. In noiseless hyperspectral image denoising, the Diffusion model commonly used is based on the Nonlinear Diffusion Equation (NDE). NDE can control the diffusion rate of noise by changing the diffusion coefficient, so as to achieve the de-noising effect. A smaller diffusion coefficient can slow the diffusion of noise, thereby preserving the details of the image.
文献阅读
文献链接:A NOISE-MODEL-FREE HYPERSPECTRAL IMAGE DENOISING METHOD BASED ON
DIFFUSION MODEL
文献摘要
高光谱图像(HSI)去噪是确保后续HSI分析和解释准确性的关键预处理步骤。神经网络方法最近在 HSI 去噪方面取得了最先进的性能。然而,这些方法通常是在特定的噪声模型上进行训练的,这可能会限制它们的性能,因为 HSI 中的噪声模型可能会因不同的频谱带而异。为了缓解这个问题,我们引入了一种基于扩散模型(DM)的 HSI 去噪方法,其训练过程独立于噪声模型,称为无噪声模型方法。在此方法中,我们首先通过增加输入和输出维度以合并光谱和空间信息来引入 HSI 的 DM。然后,我们针对常见噪声模型推导出基于 DM 的 HSI 去噪过程。此外,为了解决训练过程中的过度拟合问题,我们引入了随机采样方法,以更有效地平衡空间和光谱信息的重要性。分布内和分布外样本的实验结果证明了我们方法的有效性。
背景介绍
高光谱图像(HSIs)具有丰富的光谱和空间信息,具有广泛的应用,包括医学诊断、物质识别和土地利用分类等。然而,由于噪声、环境条件和设备限制等多种因素,获得高质量的 HSI 可能具有挑战性。在某些特定频段,存在明显的光子噪声和脉冲噪声,会破坏高频和详细信息。因此,HSI去噪是一项至关重要的预处理任务,用于从噪声测量中恢复信息并确保后续应用的有效性。扩散模型 (DM) 是一类新型生成模型,在图像生成方面取得了显着的性能。这些方法通过近似得分函数并使用 Langevin Dynamics 从该分布中采样来隐式学习数据集的先验分布。受益于这种先验分布的有效性,DM 最近在各种 RGB 图像恢复任务中表现出了高质量。这些基于 DM 的恢复方法将恢复问题视为后验采样问题,因此使用贝叶斯规则将学习到的先验分布转换为后验分布。由于这些方法仅使用网络来学习先验分布,不一定依赖于噪声模型,因此它们的训练过程独立于噪声模型,并且无需在特定噪声模型上进行训练即可实现出色的恢复性能。我们将具有此属性的方法视为一种无噪声模型方法。这种无噪声模型的特性对于 HSI 去噪非常有用,因为噪声模型可能会因不同的频谱带而异。然而,将 DM 应用于 HSI 去噪的研究还很有限。由于 HSI 含有丰富的光谱信息,这有利于去噪过程,因此结合光谱和空间信息非常重要。在本论文中,作者通过增加第一个卷积层的输入通道和最后一个卷积层的输出通道来调整 DM,以匹配 HSI 的光谱维度。第一个卷积利用光谱信息创建鲁棒的局部特征,而最后一个卷积将特征重新投影回 HSI 空间。为了导出去噪过程,考虑一个常见的噪声模型,并利用贝叶斯规则获得后验分布。此外,为了减轻训练过程中的过度拟合问题,作者引入随机采样以更好地平衡空间和光谱信息的重要性。
方法
首先介绍一般的扩散模型,然后将其应用于恒生指数。其次,为常见噪声模型的 HSI 去噪任务引入了后扩散模型。最后,为了缓解过度拟合,作者在训练阶段引入了随机采样方法。
扩散模型
扩散模型(DM)是一种新型的无条件生成模型,可以使用马尔可夫链结构学习输入数据集的概率分布。这些模型由两部分组成:正向过程和逆向过程。前向过程(由图 1 中的虚线表示)通常将输入图像转换为标准高斯噪声。相反的过程如图1中的实线所示,逐步从标准高斯噪声中恢复图像。为了涉及贝叶斯规则,作者引入了随机微分方程(SDE)风格的通用DM。

具体来说,给定样本
x
0
∼
p
(
x
0
)
x_0 ∼ p(x_0)
x0∼p(x0),前向过程可以定义为以下 SDE,
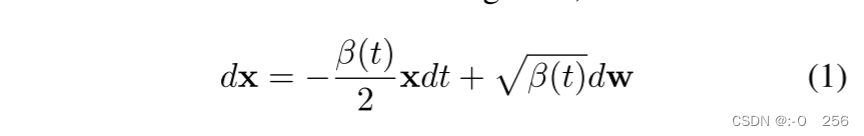
其中 β(t) 控制噪声调度,t ∈ [0, T] 是时间步长,w 是标准维纳过程。值得注意的是,x是关于t的变体,但为了简化可以将其表示为x。通过求解方程中的 SDE。 (1)可以使用以下等式直接对
x
t
x_t
xt 进行采样,

其中
ϵ
∼
N
(
0
,
I
)
,
α
t
=
1
−
β
(
t
)
,并且
α
t
ˉ
=
e
x
p
(
∫
0
t
l
o
g
α
τ
d
τ
)
ϵ ∼ N(0, I),α_t = 1−β(t),并且 \bar{α_t} = exp( \int_{0}^{t} log α_τdτ)
ϵ∼N(0,I),αt=1−β(t),并且αtˉ=exp(∫0tlogατdτ)。对于给定的
x
T
x_T
xT,我们可以使用定义为以下 SDE 的逆过程从
p
(
x
0
)
p(x_0)
p(x0)中进行采样,

其中梯度
∇
x
l
o
g
p
t
(
x
)
可以通过去噪网络
ϵ
θ
(
x
t
,
t
)
∇_x log p_t(x) 可以通过去噪网络 ϵ_θ(x_t, t)
∇xlogpt(x)可以通过去噪网络ϵθ(xt,t) 来近似,

ϵ
θ
(
x
t
,
t
)
ϵ_θ(x_t, t)
ϵθ(xt,t) 可以通过最小化简化的损失函数来获得,

大多数 DM 使用带有时间步嵌入的 U-Net 来实现
ϵ
θ
(
x
t
,
t
)
ϵ_θ(x_t, t)
ϵθ(xt,t)。虽然这些 U-Net 的设计通常是对于具有三个输入和输出通道的 RGB 图像,我们通过增加输入和输出通道以匹配光谱的维度来使其与 HSI 一起使用。对于特定的HSI
x
∈
R
N
×
M
×
B
x ∈ R^{N×M×B}
x∈RN×M×B,其中N×M和B分别表示空间维度和谱维度,第一个卷积层中的输入通道和最后一个卷积层中的输出通道增加到B。结果,光谱信息通过卷积层合并到 U-Net 中。
HSI 去噪的后扩散模型
从方程(3)获得的样本是完全随机且不受控制的,而HSI去噪任务需要在给定噪声测量值y的情况下生成具有最大后验概率
p
(
x
0
∣
y
)
p(x_0|y)
p(x0∣y)的HSI样本。因此,方程(3)定义的逆过程应修改如下:

根据贝叶斯法则,我们可以推导出,
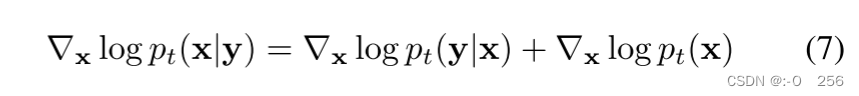
为了推导
∇
x
l
o
g
p
t
(
y
∣
x
)
∇_x log p_t(y|x)
∇xlogpt(y∣x),我们考虑 HSI 被高斯噪声和脉冲噪声破坏的常见情况,
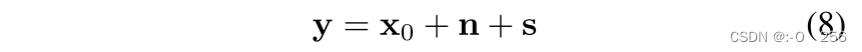
其中
n
∼
N
(
0
,
σ
y
I
)
n ∼ N(0, σ_yI)
n∼N(0,σyI),s 是脉冲噪声。值得注意的是,训练过程独立于噪声模型,但去噪过程则不然。通过涉及无信息假设
p
(
x
0
)
∝
p
(
x
t
)
p(x0) ∝ p(x_t)
p(x0)∝p(xt),我们可以得出,
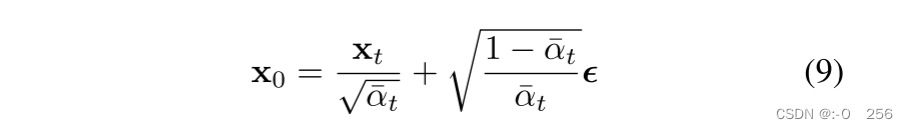
然后作者考虑一个中值滤波器,其内核大小为
k
m
e
d
k_{med}
kmed 作为脉冲噪声的伪逆函数
h
†
(
⋅
)
h^†(·)
h†(⋅),其中
h
†
(
y
)
≃
x
0
+
n
h^†(y) ≃ x_0 + n
h†(y)≃x0+n。结合式(8)和式(9),我们有,
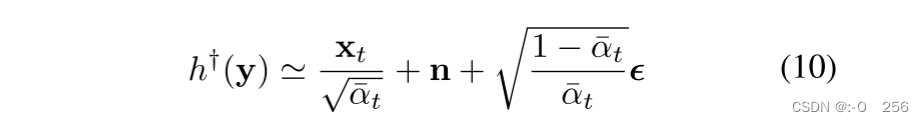
因此,x 的梯度为,

对于 HSI 去噪任务,
σ
y
σ_y
σy 可能因频段而异。由于该方法对
σ
y
σ_y
σy 敏感,因此估计每个频带的
σ
y
σ_y
σy 很重要,可以近似写为:
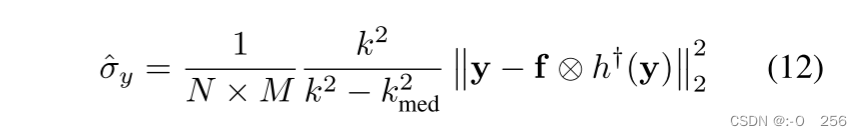
其中 f 是内核大小为
k
(
k
>
k
m
e
d
)
k(k > k_{med})
k(k>kmed) 的均值滤波器的内核,运算符 ⊗ 表示卷积。
k
m
e
d
k_{med}
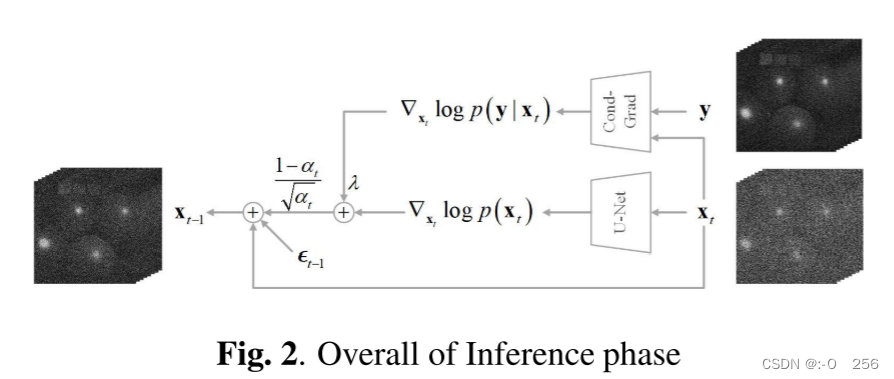
kmed = 1 表示不应用中值滤波器,可用于去除纯高斯噪声。最后,推理阶段的流程图如图2所示。如图所示,
ϵ
t
−
1
ϵ_{t−1}
ϵt−1是时间步t−1中的高斯噪声,
(
1
−
α
t
)
/
α
t
(1−α_t)/\sqrt{α_t}
(1−αt)/αt是步长。
∇
x
t
l
o
g
p
(
x
t
)
∇x_t log p(x_t)
∇xtlogp(xt) 使用等式计算。 (4) 和
∇
x
t
l
o
g
p
(
y
∣
x
t
)
∇x_t log p(y|x_t)
∇xtlogp(y∣xt) 使用式(11) 计算。实验结果表明,将
∇
x
t
l
o
g
p
(
x
t
)
∇x_t log p(x_t)
∇xtlogp(xt) 放大 λ 倍(其中 λ ≥ 1)可以获得更好的去噪效果。采样的确切分布是
p
(
x
0
∣
y
)
p
(
y
∣
x
0
)
λ
−
1
p(x_0|y)p(y|x_0)^{λ−1}
p(x0∣y)p(y∣x0)λ−1。第一部分确保样本是清晰的,而第二部分确保样本来自与测量 y 相同的分布。
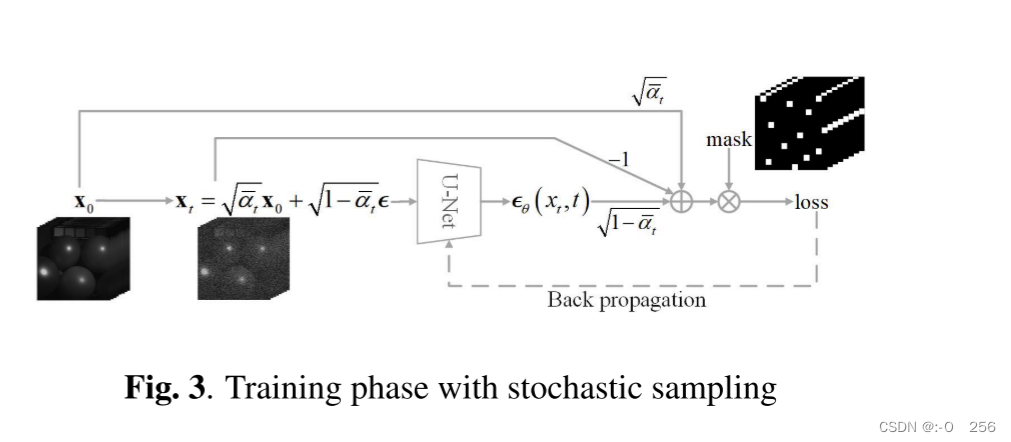
随机抽样
所提出的网络结构和损失函数已经在 HSI 去噪任务中表现良好。受[6]的启发,我们在训练阶段引入随机采样,可以缓解过拟合问题并提高去噪性能。随机采样背后的关键思想是平衡空间和光谱信息的重要性。对于HSI数据集,空间信息复杂且不同场景的空间信息不同,这使得训练阶段的分布与测试阶段的分布不同。然而,光谱信息在不同场景中通常更加一致。为了平衡空间和光谱信息的重要性,我们提出随机采样,随机屏蔽一些像素的整个光谱。随机采样的损失函数可以定义为,

其中 ⊙ 是逐元素乘积,m 是像素掩码,其中
p
(
m
i
,
j
,
:
=
0
)
=
p
m
a
s
k
且
p
(
m
i
,
j
,
:
=
1
)
=
1
−
p
m
a
s
k
p(m_{i,j},: = 0) = p_{mask} 且 p(m_{i,j},: = 1) = 1 − p_{mask}
p(mi,j,:=0)=pmask且p(mi,j,:=1)=1−pmask。没有像素掩蔽的损失函数(如式(5)所示)最大化
E
x
0
p
(
x
0
)
Ex_0p(x_0)
Ex0p(x0),这意味着空间和谱似然几乎被同等地考虑。另一方面,具有像素掩蔽的损失函数(如式(13)所示)最大化
E
x
0
,
m
p
(
m
⊙
x
0
)
Ex_0,mp(m ⊙ x_0)
Ex0,mp(m⊙x0),这意味着一些空间信息被丢弃。这如图 3 所示,其中一些空间信息在反向传播之前被像素掩模阻挡。
结论
在本文中,提出了用于 HSI 去噪的 DM,它可以结合空间和光谱信息。基于DM的去噪方法在训练时不需要指定噪声模型,并且可以通过修改推理过程来适应各种噪声模型。引入了一种基于DM的方法来清除高斯噪声和脉冲噪声的混合噪声,该方法使用中值滤波器来解决脉冲噪声引起的均值漂移问题。为了更好地平衡空间和光谱信息的重要性并减轻过度拟合,引入了随机采样方法,该方法在训练过程中随机丢弃一些空间信息。实验结果表明,提出的方法在分布内和分布外样本上都优于几种著名的方法,并且证明了训练样本和测试样本之间一致性的鲁棒性。

复习GAN
GAN的定义?
生成对抗网络(GAN, Generative adversarial network)自从2014年被Ian Goodfellow提出以来,掀起来了一股研究热潮。GAN由生成器和判别器组成,生成器负责生成样本,判别器负责判断生成器生成的样本是否为真。生成器要尽可能迷惑判别器,而判别器要尽可能区分生成器生成的样本和真实样本。
在GAN的原作中,作者将生成器比喻为印假钞票的犯罪分子,判别器则类比为警察。犯罪分子努力让钞票看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。那么类比于图像生成任务,生成器不断生成尽可能逼真的假图像。判别器则判断图像是否是真实的图像,还是生成的图像,二者不断博弈优化。最终生成器生成的图像使得判别器完全无法判别真假。
GAN的形式化表达
上述例子只是简要介绍了一下GAN的思想,下面对于GAN做一个形式化的,更加具体的定义。通常情况下,无论是生成器还是判别器,我们都可以用神经网络来实现。那么,我们可以把通俗化的定义用下面这个模型来表示:
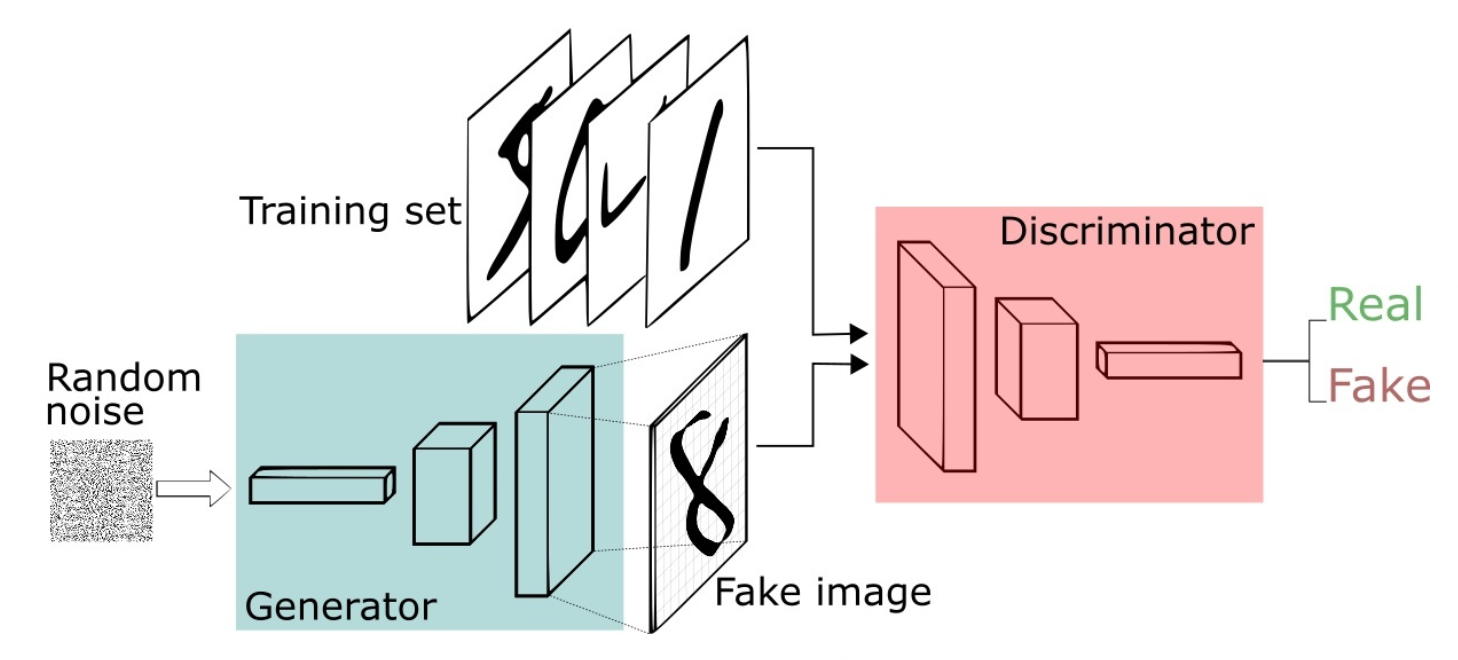
上述模型左边是生成器G,其输入是
z
z
z,对于原始的GAN,
z
z
z是由高斯分布随机采样得到的噪声。噪声
z
z
z通过生成器得到了生成的假样本。
生成的假样本与真实样本放到一起,被随机抽取送入到判别器D,由判别器去区分输入的样本是生成的假样本还是真实的样本。整个过程简单明了,生成对抗网络中的“生成对抗”主要体现在生成器和判别器之间的对抗。
GAN的目标函数是什么?
对于上述神经网络模型,如果想要学习其参数,首先需要一个目标函数。GAN的目标函数定义如下:
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \mathop {\min }\limits_G \mathop {\max }\limits_D V(D,G) = {\rm E}{x\sim{p{data}(x)}}[\log D(x)] + {\rm E}_{z\sim{p_z}(z)}[\log (1 - D(G(z)))] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))] 这个目标函数可以分为两个部分来理解:
第一部分:判别器的优化通过 max D V ( D , G ) \mathop {\max}\limits_D V(D,G) DmaxV(D,G)实现, V ( D , G ) V(D,G) V(D,G)为判别器的目标函数,其第一项 E x ∼ p d a t a ( x ) [ log D ( x ) ] {\rm E}{x\sim{p{data}(x)}}[\log D(x)] Ex∼pdata(x)[logD(x)]表示对于从真实数据分布 中采用的样本 ,其被判别器判定为真实样本概率的数学期望。对于真实数据分布 中采样的样本,其预测为正样本的概率当然是越接近1越好。因此希望最大化这一项。第二项 E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] {\rm E}_{z\sim{p_z}(z)}[\log (1 - D(G(z)))] Ez∼pz(z)[log(1−D(G(z)))]表示:对于从噪声 P z ( z ) P_z(z) Pz(z)分布当中采样得到的样本,经过生成器生成之后得到的生成图片,然后送入判别器,其预测概率的负对数的期望,这个值自然是越大越好,这个值越大, 越接近0,也就代表判别器越好。
第二部分:生成器的优化通过 min G ( max D V ( D , G ) ) \mathop {\min }\limits_G({\mathop {\max }\limits_D V(D,G)}) Gmin(DmaxV(D,G))来实现。注意,生成器的目标不是 min G V ( D , G ) \mathop {\min }\limits_GV(D,G) GminV(D,G),即生成器不是最小化判别器的目标函数,二是最小化判别器目标函数的最大值,判别器目标函数的最大值代表的是真实数据分布与生成数据分布的JS散度(详情可以参阅附录的推导),JS散度可以度量分布的相似性,两个分布越接近,JS散度越小。
GAN的目标函数和交叉熵有什么区别?
判别器目标函数写成离散形式即为:

可以看出,这个目标函数和交叉熵是一致的,即判别器的目标是最小化交叉熵损失,生成器的目标是最小化生成数据分布和真实数据分布的JS散度。
GAN的Loss为什么降不下去?
对于很多GAN的初学者在实践过程中可能会纳闷,为什么GAN的Loss一直降不下去。GAN到底什么时候才算收敛?其实,作为一个训练良好的GAN,其Loss就是降不下去的。衡量GAN是否训练好了,只能由人肉眼去看生成的图片质量是否好。不过,对于没有一个很好的评价是否收敛指标的问题,也有许多学者做了一些研究,后文提及的WGAN就提出了一种新的Loss设计方式,较好的解决了难以判断收敛性的问题。下面我们分析一下GAN的Loss为什么降不下去? 对于判别器而言,GAN的Loss如下: min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \mathop {\min }\limits_G \mathop {\max }\limits_D V(D,G) = {\rm E}{x\sim{p{data}(x)}}[\log D(x)] + {\rm E}_{z\sim{p_z}(z)}[\log (1 - D(G(z)))] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))] 从 min G max D V ( D , G ) \mathop {\min }\limits_G \mathop {\max }\limits_D V(D,G) GminDmaxV(D,G)可以看出,生成器和判别器的目的相反,也就是说两个生成器网络和判别器网络互为对抗,此消彼长。不可能Loss一直降到一个收敛的状态。
- 对于生成器,其Loss下降快,很有可能是判别器太弱,导致生成器很轻易的就"愚弄"了判别器。
- 对于判别器,其Loss下降快,意味着判别器很强,判别器很强则说明生成器生成的图像不够逼真,才使得判别器轻易判别,导致Loss下降很快。
生成式模型、判别式模型的区别?
对于机器学习模型,我们可以根据模型对数据的建模方式将模型分为两大类,生成式模型和判别式模型。如果我们要训练一个关于猫狗分类的模型,对于判别式模型,只需要学习二者差异即可。比如说猫的体型会比狗小一点。而生成式模型则不一样,需要学习猫长什么样,狗长什么样。有了二者的长相以后,再根据长相去区分。具体而言.
-
生成式模型:由数据学习联合概率分布P(X,Y), 然后由P(Y|X)=P(X,Y)/P(X)求出概率分布P(Y|X)作为预测的模型。该方法表示了给定输入X与产生输出Y的生成关系
-
判别式模型:由数据直接学习决策函数Y=f(X)或条件概率分布P(Y|X)作为预测模型,即判别模型。判别方法关心的是对于给定的输入X,应该预测什么样的输出Y。
对于上述两种模型,从文字上理解起来似乎不太直观。我们举个例子来阐述一下,对于性别分类问题,分别用不同的模型来做:
1)如果用生成式模型:可以训练一个模型,学习输入人的特征X和性别Y的关系。比如现在有下面一批数据:

这个数据可以统计得到,即统计人的特征X=0,1….的时候,其类别为Y=0,1的概率。统计得到上述联合概率分布P(X, Y)后,可以学习一个模型,比如让二维高斯分布去拟合上述数据,这样就学习到了X,Y的联合分布。在预测时,如果我们希望给一个输入特征X,预测其类别,则需要通过贝叶斯公式得到条件概率分布才能进行推断:
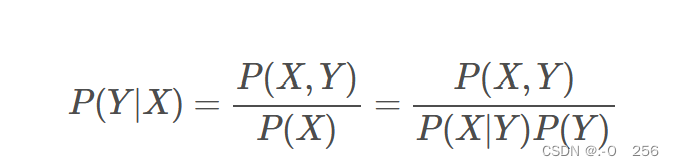
2)如果用判别式模型:可以训练一个模型,输入人的特征X,这些特征包括人的五官,穿衣风格,发型等。输出则是对于性别的判断概率,这个概率服从一个分布,分布的取值只有两个,要么男,要么女,记这个分布为Y。这个过程学习了一个条件概率分布P(Y|X),即输入特征X的分布已知条件下,Y的概率分布。
显然,从上面的分析可以看出。判别式模型似乎要方便很多,因为生成式模型要学习一个X,Y的联合分布往往需要很多数据,而判别式模型需要的数据则相对少,因为判别式模型更关注输入特征的差异性。不过生成式既然使用了更多数据来生成联合分布,自然也能够提供更多的信息,现在有一个样本(X,Y),其联合概率P(X,Y)经过计算特别小,那么可以认为这个样本是异常样本。这种模型可以用来做outlier detection。
什么是mode collapsing?
某个模式(mode)出现大量重复样本,例如: 上图左侧的蓝色五角星表示真实样本空间,黄色的是生成的。生成样本缺乏多样性,存在大量重复。比如上图右侧中,红框里面人物反复出现。
如何解决mode collapsing?
方法一:针对目标函数的改进方法
为了避免前面提到的由于优化maxmin导致mode跳来跳去的问题,UnrolledGAN采用修改生成器loss来解决。具体而言,UnrolledGAN在更新生成器时更新k次生成器,参考的Loss不是某一次的loss,是判别器后面k次迭代的loss。注意,判别器后面k次迭代不更新自己的参数,只计算loss用于更新生成器。这种方式使得生成器考虑到了后面k次判别器的变化情况,避免在不同mode之间切换导致的模式崩溃问题。此处务必和迭代k次生成器,然后迭代1次判别器区分开。DRAGAN则引入博弈论中的无后悔算法,改造其loss以解决mode collapse问题。前文所述的EBGAN则是加入VAE的重构误差以解决mode collapse。
方法二:针对网络结构的改进方法
Multi agent diverse GAN(MAD-GAN)采用多个生成器,一个判别器以保障样本生成的多样性。具体结构如下:
相比于普通GAN,多了几个生成器,且在loss设计的时候,加入一个正则项。正则项使用余弦距离惩罚三个生成器生成样本的一致性。
MRGAN则添加了一个判别器来惩罚生成样本的mode collapse问题。具体结构如下:
输入样本 x x x通过一个Encoder编码为隐变量 E ( x ) E(x) E(x),然后隐变量被Generator重构,训练时,Loss有三个。 D M D_M DM和 R R R(重构误差)用于指导生成real-like的样本。而 D D D_D DD则对 E ( x ) E(x) E(x)和 z z z生成的样本进行判别,显然二者生成样本都是fake samples,所以这个判别器主要用于判断生成的样本是否具有多样性,即是否出现mode collapse。
方法三:Mini-batch Discrimination
Mini-batch discrimination在判别器的中间层建立一个mini-batch layer用于计算基于L1距离的样本统计量,通过建立该统计量,实现了一个batch内某个样本与其他样本有多接近。这个信息可以被判别器利用到,从而甄别出哪些缺乏多样性的样本。对生成器而言,则要试图生成具有多样性的样本。















 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









