






这里写目录标题
摘要
本周阅读了一篇关于多块和特征融合的图像去雾网络的论文。基于深度学习的去雾方法在图像去雾领域取得了显着进展,但大多数方法仍然存在去雾不完全和颜色失真的问题。为了解决这个问题,提出了一种基于多块和特征融合的图像去雾网络。该网络由预处理、特征提取、特征融合和后处理模块组成。预处理模块可以自适应地从补丁中提取图像特征信息。特征提取模块使用级联密集残差块来提取深层特征信息。特征融合模块对特征图进行通道加权和像素加权,实现主要特征的融合。后处理模块对融合后的特征图进行非线性映射,得到去雾图像。
Abstract:
This week I read a paper on image dehazing network with multi-block and feature fusion. Dehazing methods based on deep learning have made significant progress in the field of image dehazing, but most methods still have the problems of incomplete dehazing and color distortion. In order to solve this problem, an image dehazing network based on multi-block and feature fusion is proposed. The network consists of preprocessing, feature extraction, feature fusion and post-processing modules. The preprocessing module can adaptively extract image feature information from the patch. The feature extraction module uses cascaded dense residual blocks to extract deep feature information. The feature fusion module performs channel weighting and pixel weighting on the feature map to achieve the fusion of the main features. The post-processing module performs nonlinear mapping on the fused feature map to obtain the defogged image.
一、论文
论文思想
这篇论文提出了本一种基于多块和特征融合机制的端到端去雾网络,考虑了多尺度特征的融合。首先,将输入的模糊图像分为几个不同大小的patch,并使用级联的密集残差块作为特征提取网络,使得小patch专注于提取局部特征,大patch专注于提取全局特征。特征融合模块对特征进行通道加权和像素加权,实现主要特征的融合。最后,对融合后的特征进行非线性映射以获得无雾图像。
网络架构
去雾网络的总体框架如下图所示。所提出的网络是多层架构,每个级别适合不同的数量补丁。如图所示,从上到下使用的patch数量为1、2、4。顶层仅使用1个patch,即整个有雾图像。在下一层中,图像在垂直方向上被分成2个patch,在底层,上一层的patch在水平方向上进一步被划分成4个patch。
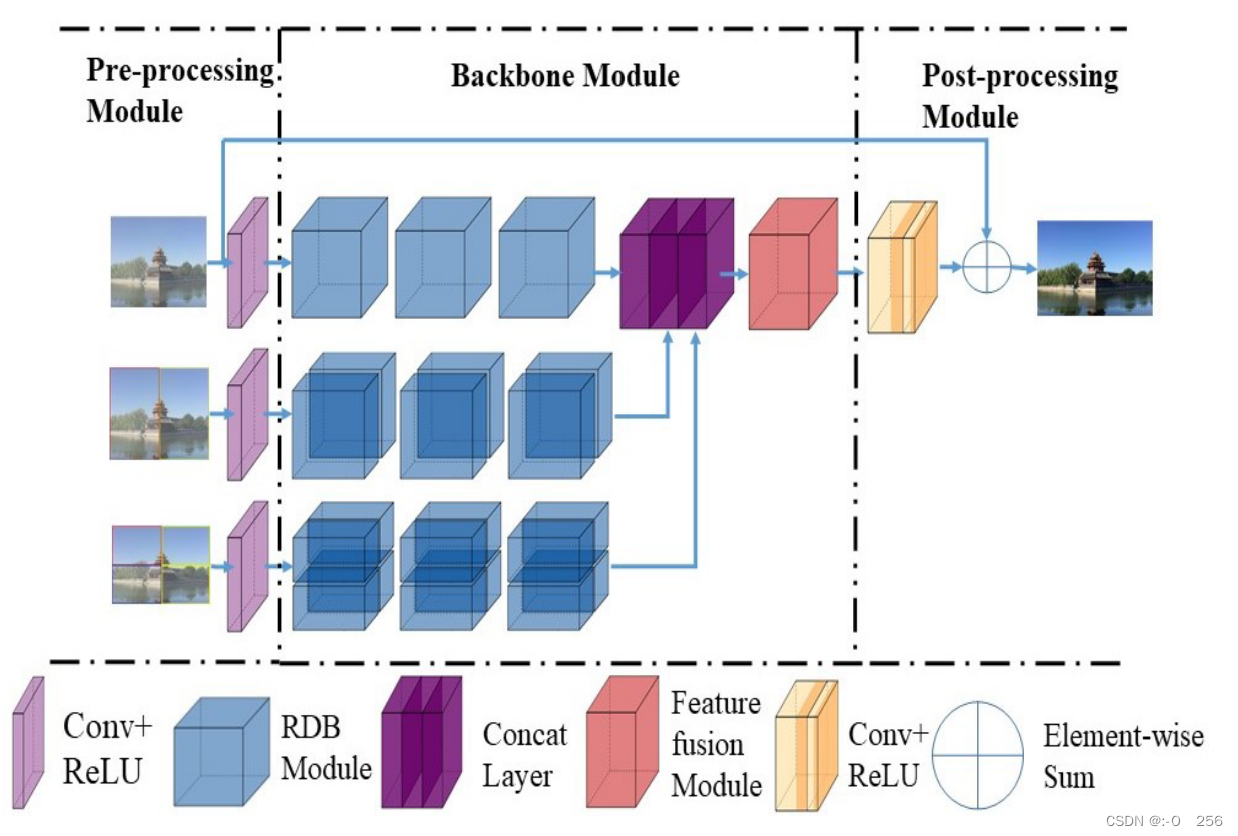
假设输入有雾图像为
I
H
I^H
IH,第 i 层的第 j 个 patch 表示为
I
i
H
I_i^H
IiH 。在第二层中,
I
H
I^H
IH垂直分为
I
2
,
1
H
I_{2,1}^H
I2,1H和
I
2
,
2
H
I_{2,2}^H
I2,2H。第三级中,
I
2
,
1
H
I_{2,1}^H
I2,1H和
I
2
,
2
H
I_{2,2}^H
I2,2H 又分为
I
3
,
1
H
I_{3,1}^H
I3,1H 、
I
3
,
2
H
I_{3,2}^H
I3,2H 、
I
3
,
3
H
I_{3,3}^H
I3,3H和
I
3
,
4
H
I_{3,4}^H
I3,4H。预处理模块和多个密集残差块表示为
P
r
e
i
Pre_i
Prei和
G
i
G_i
Gi 。
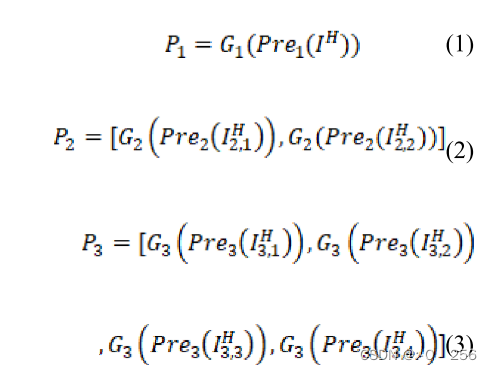
将不同层次生成的特征图进行堆叠,送入特征融合模块,然后通过后处理模块重建清晰的图像
I
^
\hat{I}
I^。
基本块结构
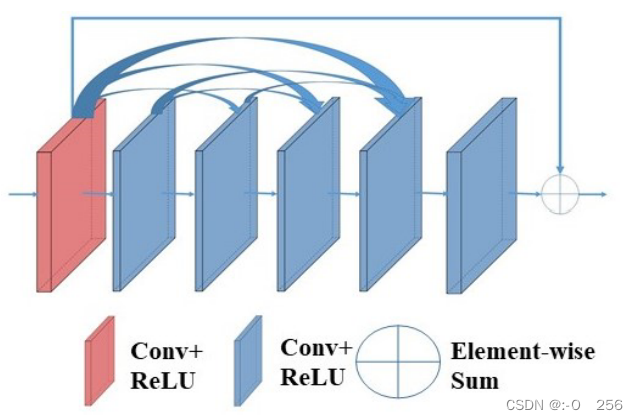
网络输入通过预处理模块只能得到浅层特征信息。这篇论文采用级联密集残差块来设计特征提取网络。残差连接不仅充分利用了不同尺度提取的特征,而且可以防止训练过程中出现梯度消失、梯度爆炸等问题。密集残差块如图所示。密集残差块由 5 个卷积层组成。
特征融合模块
大多数图像去雾网络对通道方向和像素方向的特征一视同仁,无法正确处理非均匀图像。特征融合模块如图所示,包括通道注意力和像素注意力两部分,可以为每个通道方向和像素方向特征生成不同的权重。

Loss Function
损失函数
L
1
L_1
L1可以定义为:
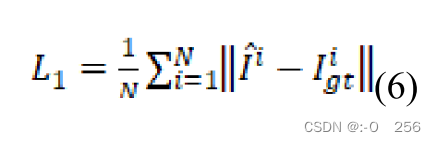
其中
N
N
N表示输入到网络的有雾图像的数量,
I
^
\hat{I}
I^ 是网络输出的无雾图像,
I
g
t
I_{gt}
Igt 表示输入有雾图像对应的清晰图像。
感知损失函数可以定义为:
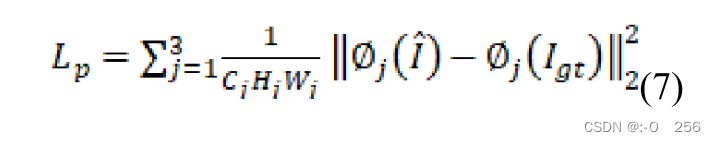
式中,
Φ
(
I
^
)
,
Φ
(
I
g
t
)
\Phi(\hat{I}),\Phi(I_{gt})
Φ(I^),Φ(Igt)表示重建图像和真实世界图像通过VGG16网络生成的三个特征图。所提出网络的总损失函数定义为:
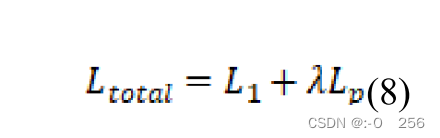
其中λ是调整两个损失函数权重的参数。本篇论文取λ=0.04
结论
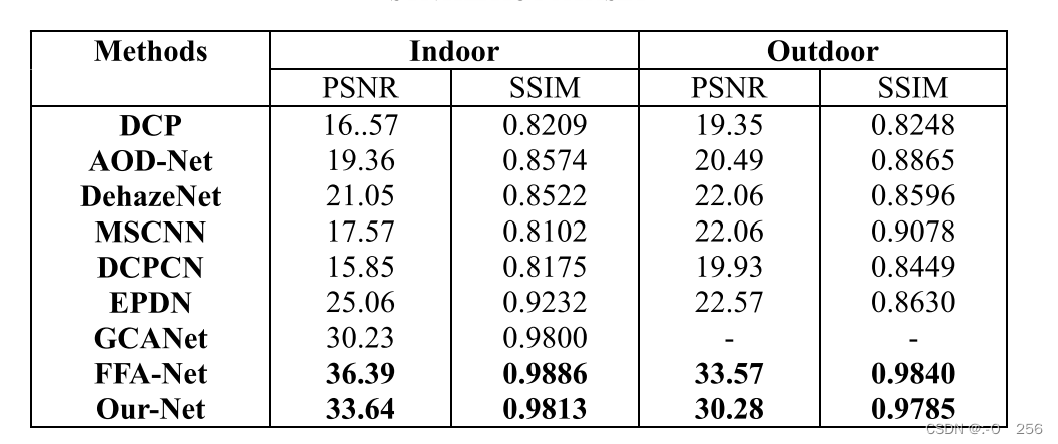
由500张室外和500张室内有雾图像组成的合成目标测试集(SOTS)实验。测试集(SOTS)上每种算法的PSNR和SSIM如表所示。从表可以看出,所提出的网络获得的PSNR和SSIM优于大多数算法。各算法的参数量以及SOTS数据集上的PSNR如图所示。所提出的网络参数量仅为FFA-Net的三分之一,但SOTS测试集上的PSNR几乎等于FFA-Net。
二 、GAN
2.1 如何客观评价GAN的生成能力?
最常见评价GAN的方法就是主观评价。主观评价需要花费大量人力物力,且存在以下问题:
评价带有主管色彩,有些bad case没看到很容易造成误判
如果一个GAN过拟合了,那么生成的样本会非常真实,人类主观评价得分会非常高,可是这并不是一个好的GAN。
因此,就有许多学者提出了GAN的客观评价方法。
2.2 Inception Score
对于一个在ImageNet训练良好的GAN,其生成的样本丢给Inception网络进行测试的时候,得到的判别概率应该具有如下特性:
- 对于同一个类别的图片,其输出的概率分布应该趋向于一个脉冲分布。可以保证生成样本的准确性。
- 对于所有类别,其输出的概率分布应该趋向于一个均匀分布,这样才不会出现mode dropping等,可以保证生成样本的多样性。
因此,可以设计如下指标:

根据前面分析,如果是一个训练良好的GAN,
p
M
(
y
∣
x
)
p_M(y|x)
pM(y∣x)趋近于脉冲分布,
p
M
(
y
)
p_M(y)
pM(y)趋近于均匀分布。二者KL散度会很大。Inception Score自然就高。实际实验表明,Inception Score和人的主观判别趋向一致。IS的计算没有用到真实数据,具体值取决于模型M的选择。、
特点:可以一定程度上衡量生成样本的多样性和准确性,但是无法检测过拟合。Mode Score也是如此。不推荐在和ImageNet数据集差别比较大的数据上使用。
2.3 Mode Score
Mode Score作为Inception Score的改进版本,添加了关于生成样本和真实样本预测的概率分布相似性度量一项。具体公式如下:
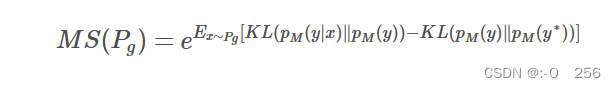
2.4 Kernel MMD (Maximum Mean Discrepancy)
计算公式如下:
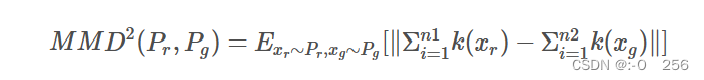
对于Kernel MMD值的计算,首先需要选择一个核函数
k
k
k,这个核函数把样本映射到再生希尔伯特空间(Reproducing Kernel Hilbert Space, RKHS) ,RKHS相比于欧几里得空间有许多优点,对于函数内积的计算是完备的。将上述公式展开即可得到下面的计算公式:

MMD值越小,两个分布越接近。
特点:可以一定程度上衡量模型生成图像的优劣性,计算代价小。推荐使用。
2.5 Wasserstein distance
FID距离计算真实样本,生成样本在特征空间之间的距离。首先利用Inception网络来提取特征,然后使用高斯模型对特征空间进行建模。根据高斯模型的均值和协方差来进行距离计算。具体公式如下:
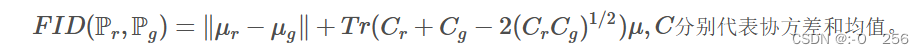
特点:尽管只计算了特征空间的前两阶矩,但是鲁棒,且计算高效。
2.6 1-Nearest Neighbor classifier
使用留一法,结合1-NN分类器(别的也行)计算真实图片,生成图像的精度。如果二者接近,则精度接近50%,否则接近0%。对于GAN的评价问题,作者分别用正样本的分类精度,生成样本的分类精度去衡量生成样本的真实性,多样性。
- 对于真实样本 x r x_r xr,进行1-NN分类的时候,如果生成的样本越真实。则真实样本空间 R \mathbb R R将被生成的样本 x g x_g xg包围。那么 x r x_r xr的精度会很低。
- 对于生成的样本
x
g
x_g
xg,进行1-NN分类的时候,如果生成的样本多样性不足。由于生成的样本聚在几个mode,则
x
g
x_g
xg很容易就和
x
r
x_r
xr区分,导致精度会很高。
特点:理想的度量指标,且可以检测过拟合。















 1397
1397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









