






文章目录
摘要
本周学习了关于自监督式学习的内容,自监督式学习不需要外界提供有标签的资料,他的带标签的资料源于自身。BERT的预训练过程包括两个阶段:MLM和NSP,在MLM中,模型需要预测被遮盖的词语,从而学习到词语之间的关系。在NSP中,模型需要判断两个句子是否是连续的,从而学习到句子级别的语义关系。BERT的创新之处在于采用了双向上下文建模的方法,能够更好地理解上下文中的词语含义。
ABSTRACT
This week, I studied the content about self-supervised learning. Self-supervised learning does not require external provision of labeled data; its labeled data comes from itself. The pre-training process of BERT consists of two stages: MLM and NSP. In MLM, the model needs to predict the masked words, thereby learning the relationships between words. In NSP, the model needs to determine whether two sentences are consecutive, thus learning sentence-level semantic relationships. The innovation of BERT lies in its adoption of bidirectional contextual modeling, enabling a better understanding of word meanings in context.
一、什么是自监督式学习
自监督式学习是一种机器学习方法,其中模型从未标记的数据中自动学习表示。在传统的监督学习中,需要标记好的数据作为训练集,而自监督式学习则不需要这些标记。相反,它利用数据中的自动生成的标签或任务来训练模型。
二、BERT基本简介
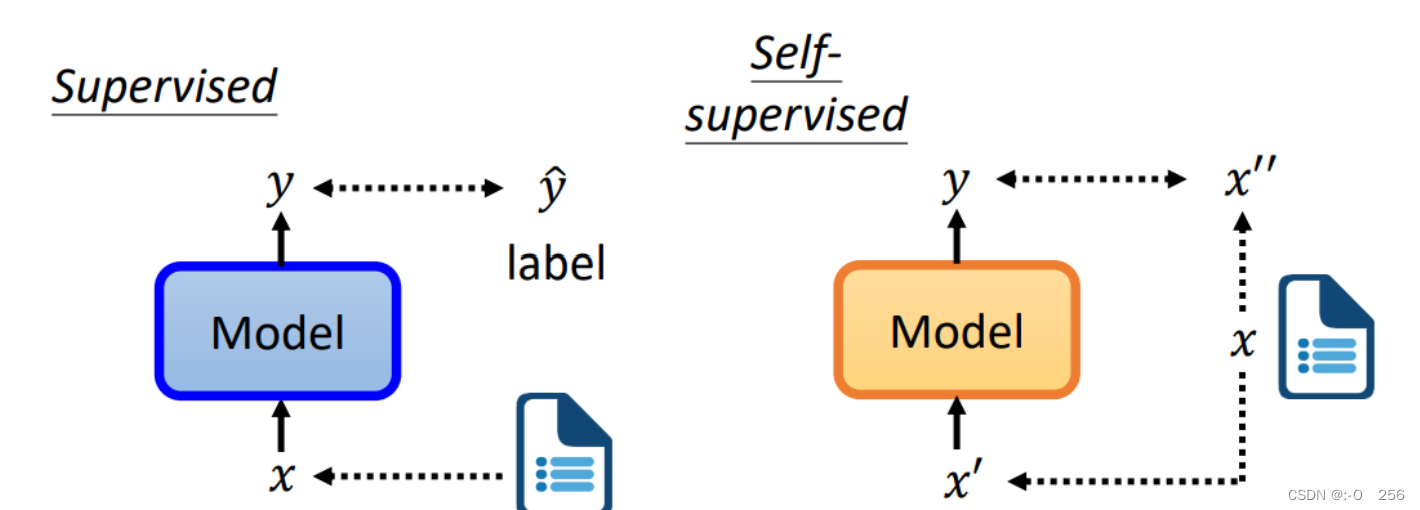
一、supervised与self-supervised的区别
supervised learning是需要有标签的资料的,而self-supervised learning不需要外界提供有标签的资料,他的带标签的资料源于自身。x分两部分,一部分用作模型的输入,另一部分作为y要学习的label资料。
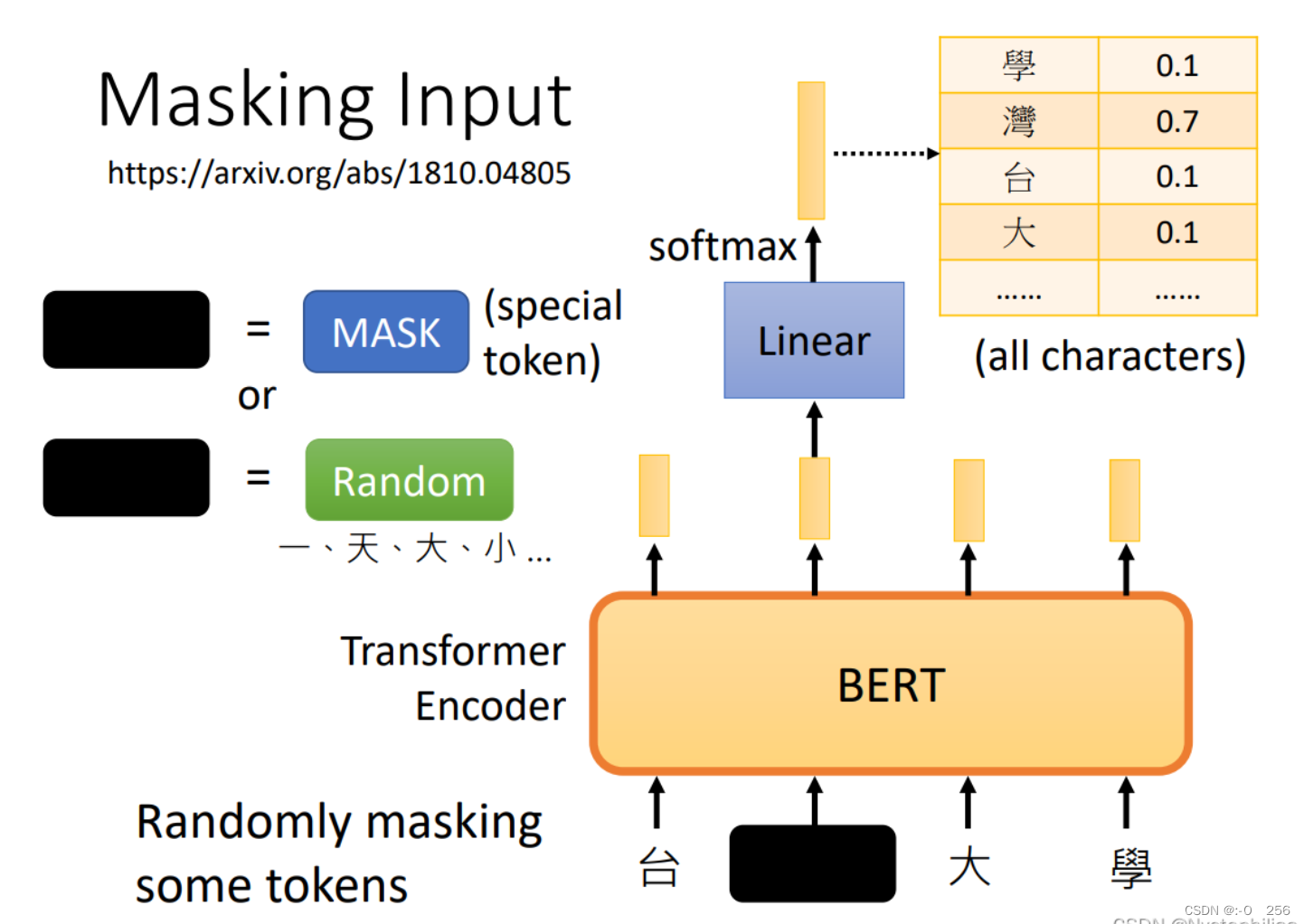
二、Masking input
BERT的架构可以简单地看成跟Transformer中的Encoder的架构是相同的,其实现的功能都是接受一排向量,并输出一排向量。而BERT特别的地方在于它对于接受的一排输入的向量(通常是文字或者语音等)会随机选择某些向量进行“遮挡”(mask)
1、随机遮盖的方法有两种:1.使用特殊单位来代替原单位;2.随机使用其他的单位来代替原单位。台大学就是x`(作为模型的输入),台湾大学等字体就是x``(作为输出要学习的label资料)。
2、被遮盖的单位输出的向量经过linear(乘上一个矩阵),再经过softmax输出一个向量,去和所有的字体做对比,找出被遮盖的字最可能是什么字。对比的过程就是计算最小的cross entropy,就像做分类问题一样,经过softmax的输出向量和所有字体代表的单向量做计算。
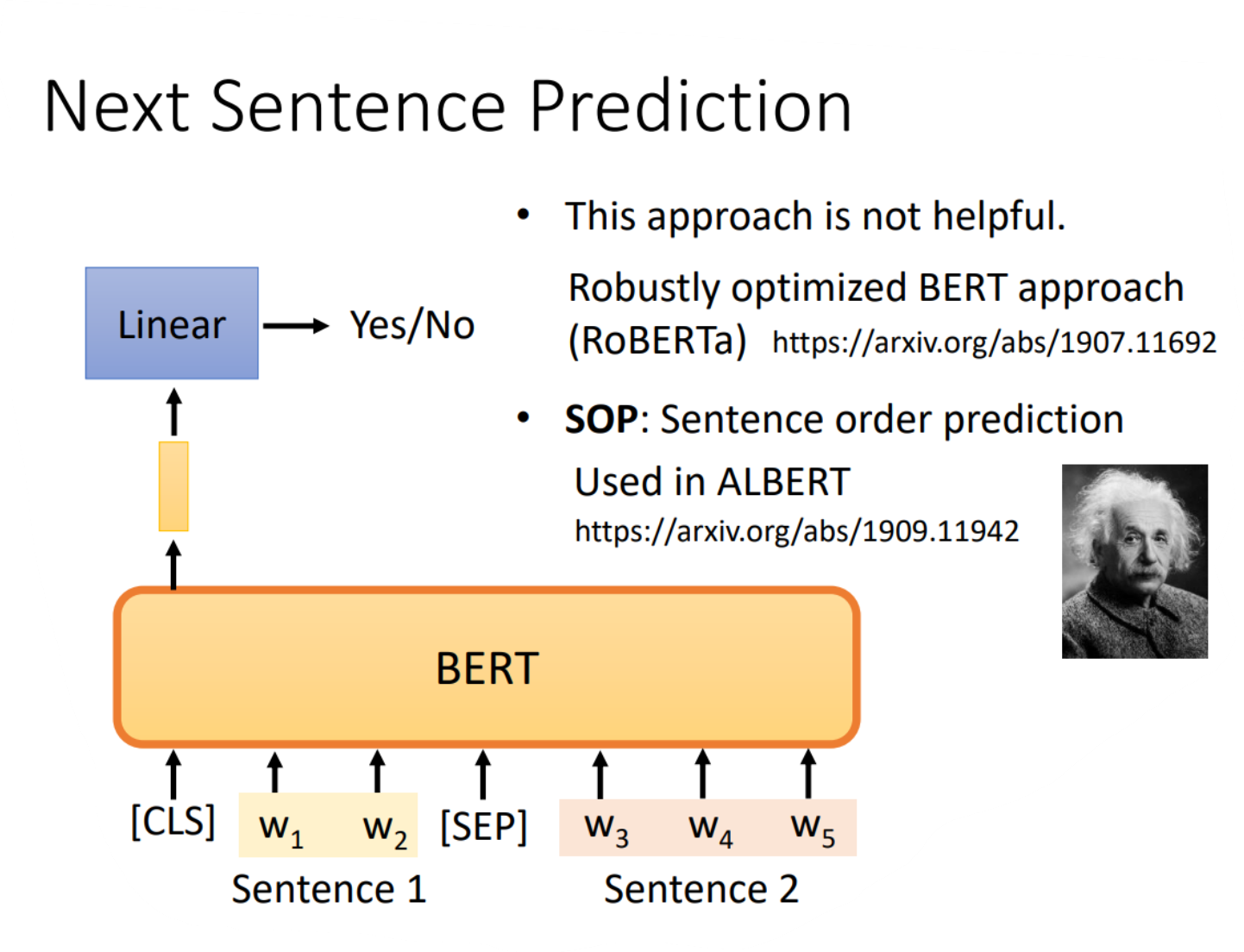
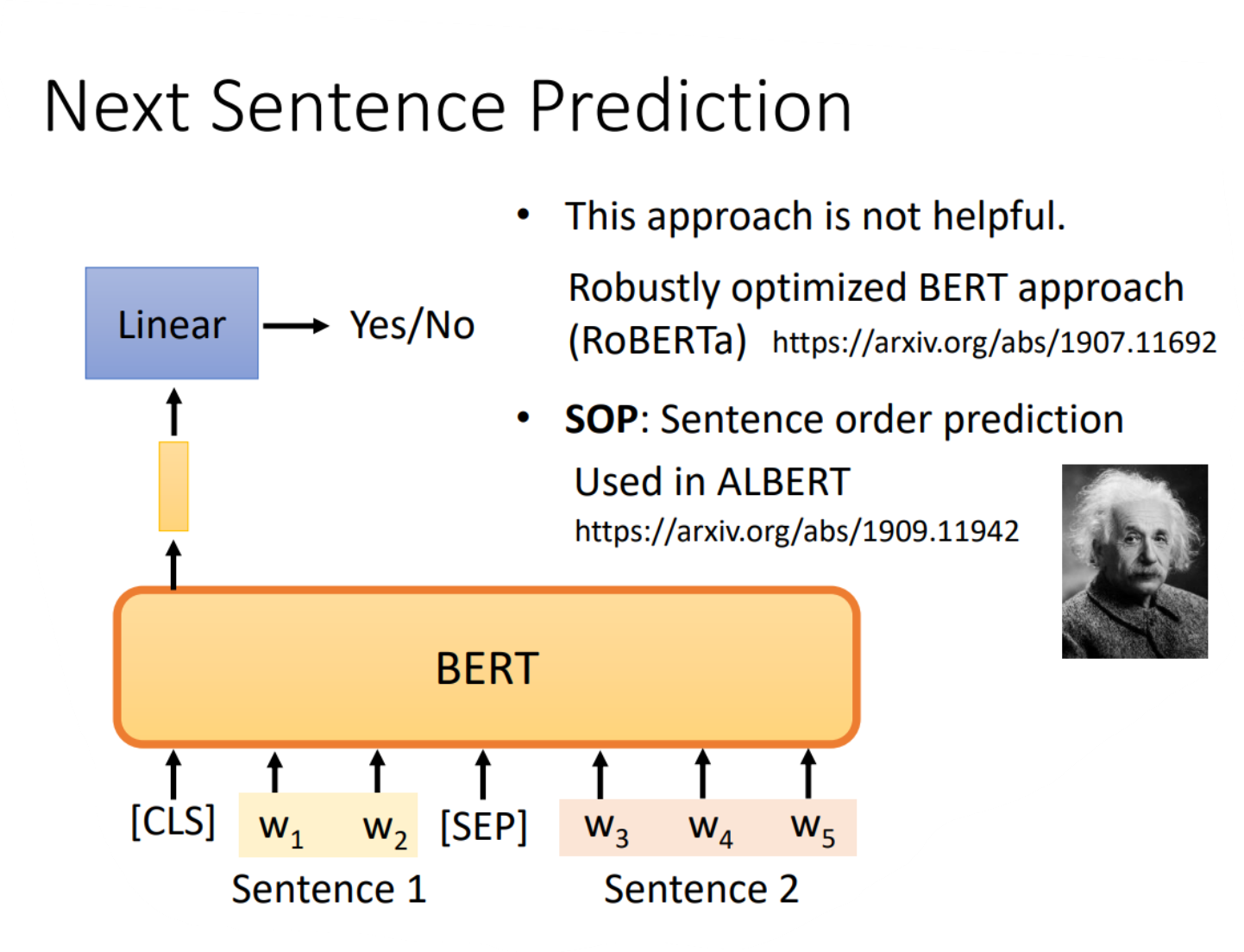
三、Next sentence prediction
这个任务是判别两个句子它们是不是应该连接在一起,那么在BERT中具体的做法为:
1、先对两个句子进行处理,在第一个句子的前面加上一个特殊的成为CLS的向量,再在两个句子的中间加上一个特殊的SEP的向量作为分隔,因此就拼成了一个较长的向量集
2、将该长向量集输入到BERT之中,那么就会输出相同数目的向量
3、但我们只关注CLS对应的输出向量,因此我们将该向量同样经过一个线性变换模块,并让这个线性变换模块的输出可以用来做一个二分类问题,就是yes或者no,代表这两个句子是不是应该拼在一起
四、BERT的框架概念
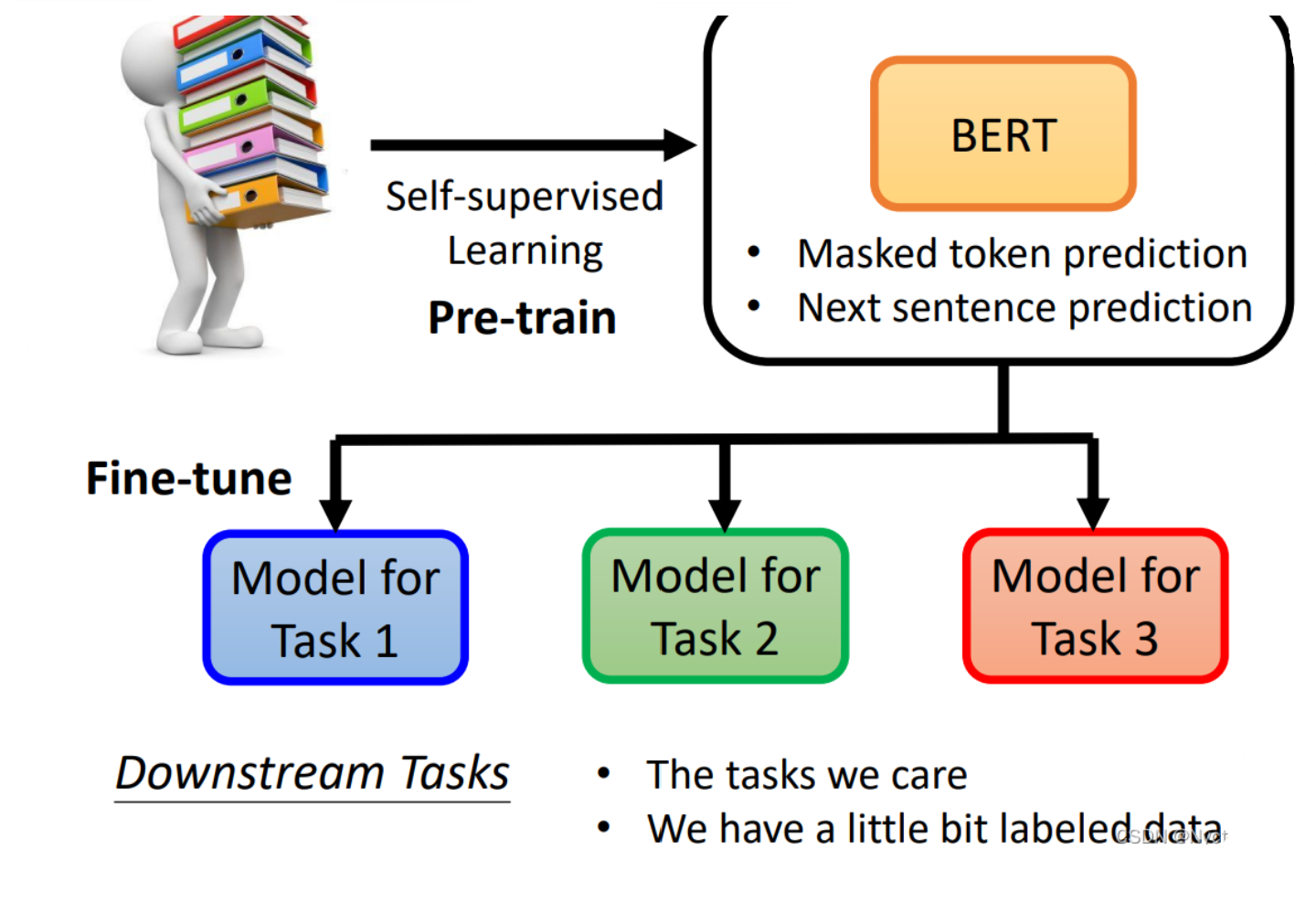
1、产生BERT的过程叫做Pre-train,该过程一般需要进行masking input 和next sentence prediction这两个操作。产生出来的BERT只会做填空题,BERT做过fine-tune(微调)之后才能做下游的各式各样的任务。
2、pre-train过程是unsupervised learning(资料来源于自身),fine-tune过程是supervised learning(有标注的资料),所以整个过程是semi-supervised。
3、目前要pre-train一个能做填空题的BERT难度很大,一方面是数据量庞大,处理起来很艰难;另一方面是徐连的过程需要很长的时间。
五、GLUE
GLUE是一个用于评估自然语言处理(NLP)模型的基准测试套件。GLUE的目标是提供一个统一的评估框架,使得不同的NLP模型可以进行公平的比较。GLUE中的每个任务都有一个对应的数据集和评估指标,模型需要在这些任务上进行训练和测试,并根据指标进行评估。GLUE是自然语言处理任务,总共有九个任务。BERT分别微调之后做这9个任务,将9个测试分数做平均后代表BERT的能力高低。

六、How to ues BERT
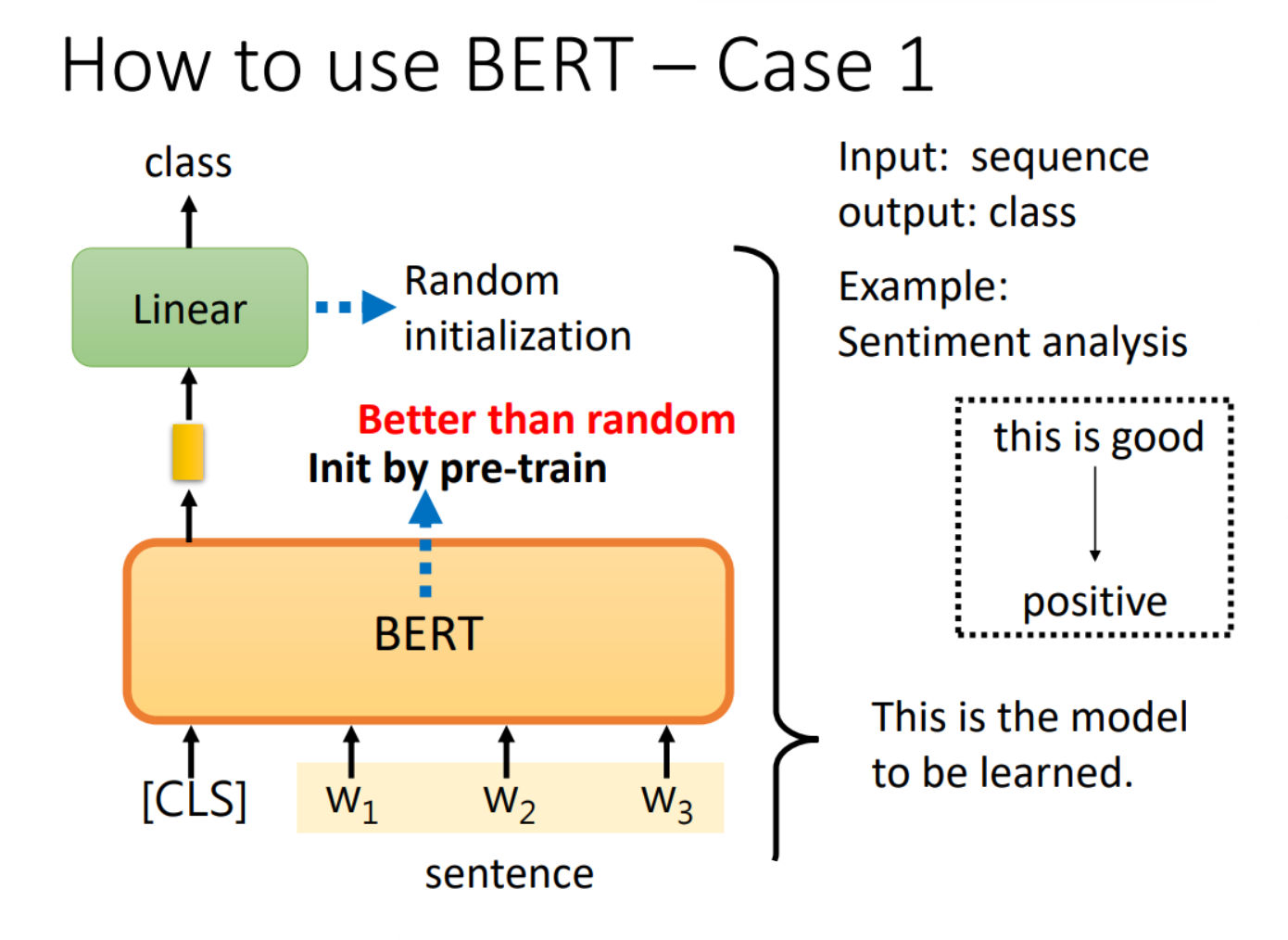
一、Case 1
Case 1 是接受一个向量,输出一个分类,例如做句子的情感分析,对一个句子判断它是积极的还是消极的。那么如何用BERT来解决这个问题呢,具体的流程如下:
1、在句子对应的一排向量之前再加上CLS这个特殊字符所对应的向量,然后将这一整排向量放入BERT之中
2、我们只关注CLS对应的输出向量,将该向量经过一个线性变换(乘上一个矩阵)后再经过一个softmax,输出一个向量来表示分类的结果,表示是积极的还是消极的
而重要的地方在于线性变换模块的参数是随机初始化的,而BERT中的参数是之前就pre-train的参数,这样会比随机初始化的BERT更加高效。而这也代表我们需要很多句子情感分析的样本和标签来让我们可以通过梯度下降来训练线性变换模块和BERT的参数。如下图:
二、Case 2
这个任务是输入一排向量,输出是和输入相同数目的向量,例如词性标注问题。那么具体的方法也是很类似的,BERT的参数也是经过pre-train得到的,而线性变化的参数是随机初始化的,然后就通过一些有标注的样本进行学习,如下图: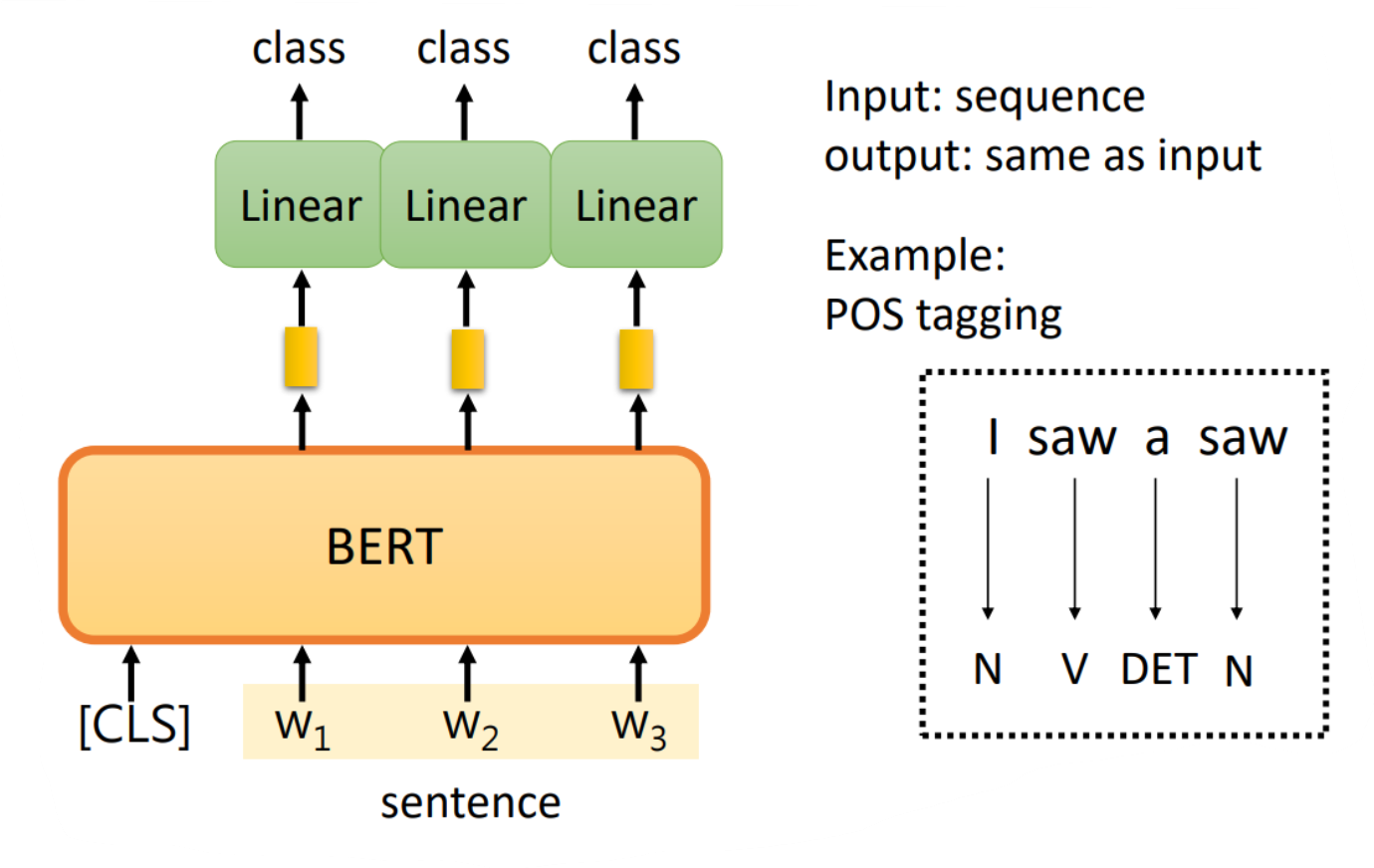
三、Case 3
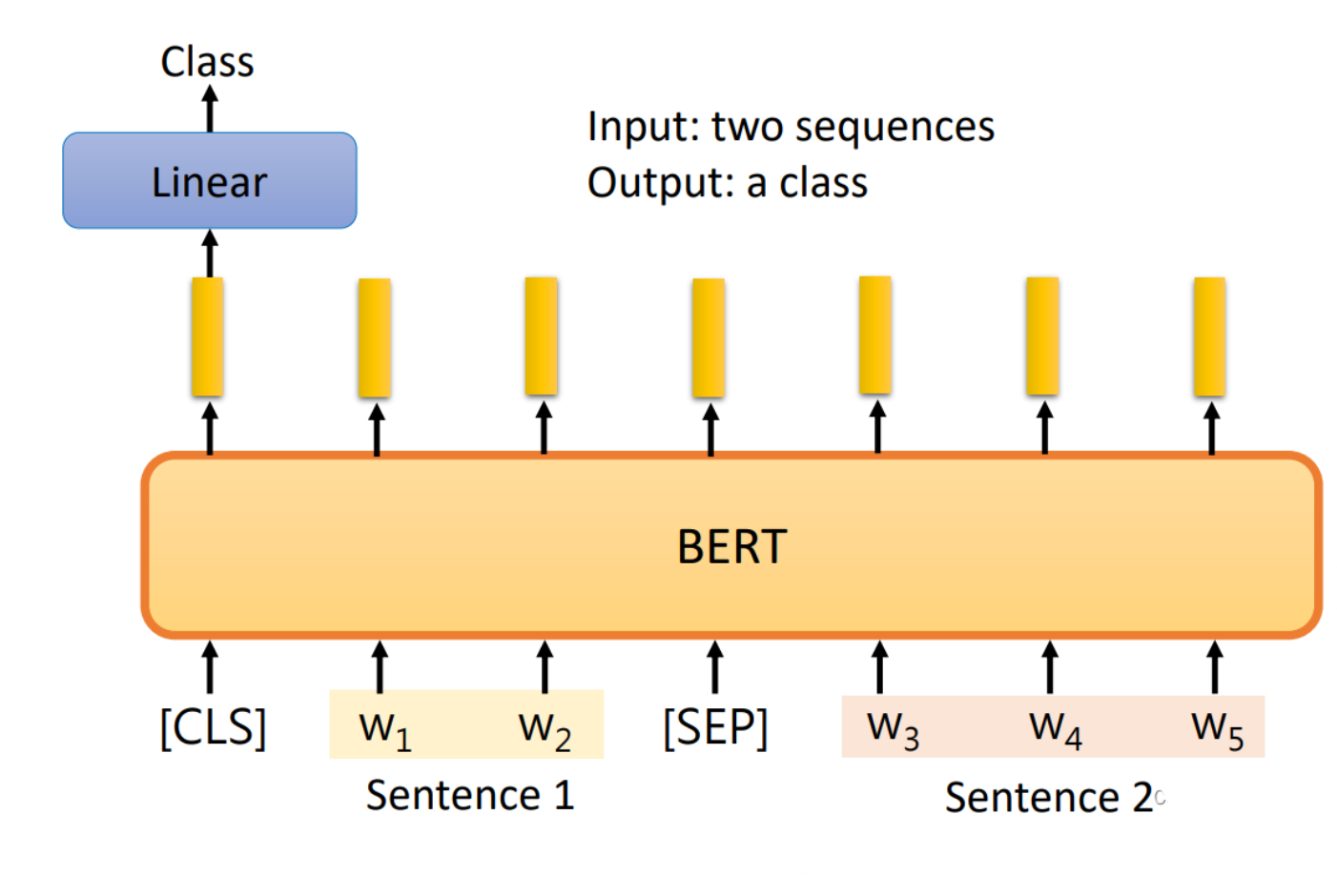
在该任务中,输入是两个句子,输出是一个分类,例如自然语言推断问题,输入是一个假设和一个推论,而输出就是这个假设和推论之间是否是冲突的,或者是相关的,或者是没有关系的:
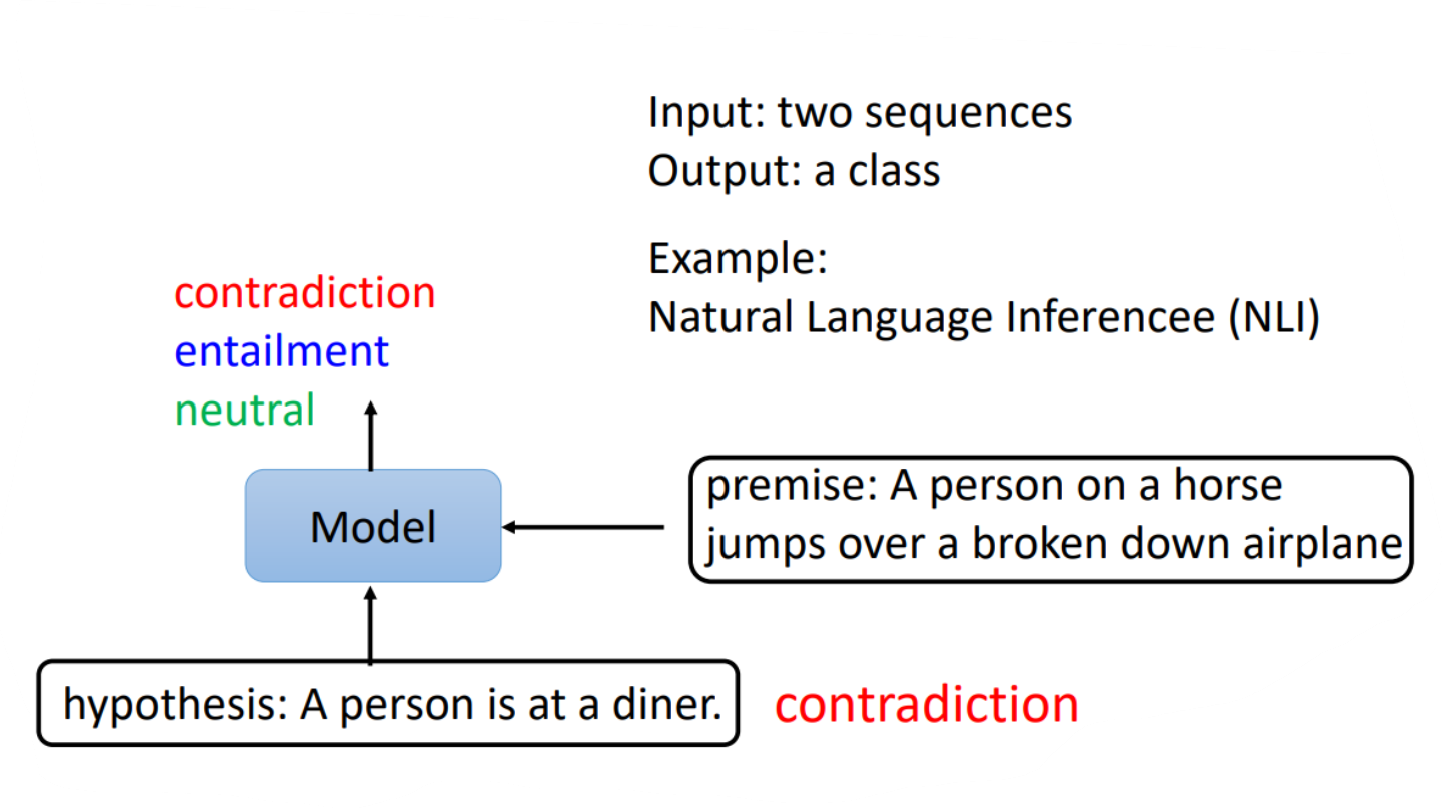
那么BERT对这类任务的做法也是类似的,因为要输出两个句子,因此在两个句子之间应该有一个SEP的特殊字符对应的向量,然后在开头也有CLS特殊字符对应的向量,并且由于输出是单纯一个分类,那关注的也是CLS对应的输出向量,将其放入线性变换模块再经过softmax就得到分类结果了。参数的设置跟之前都是一样的。如下图:
四、Case 4
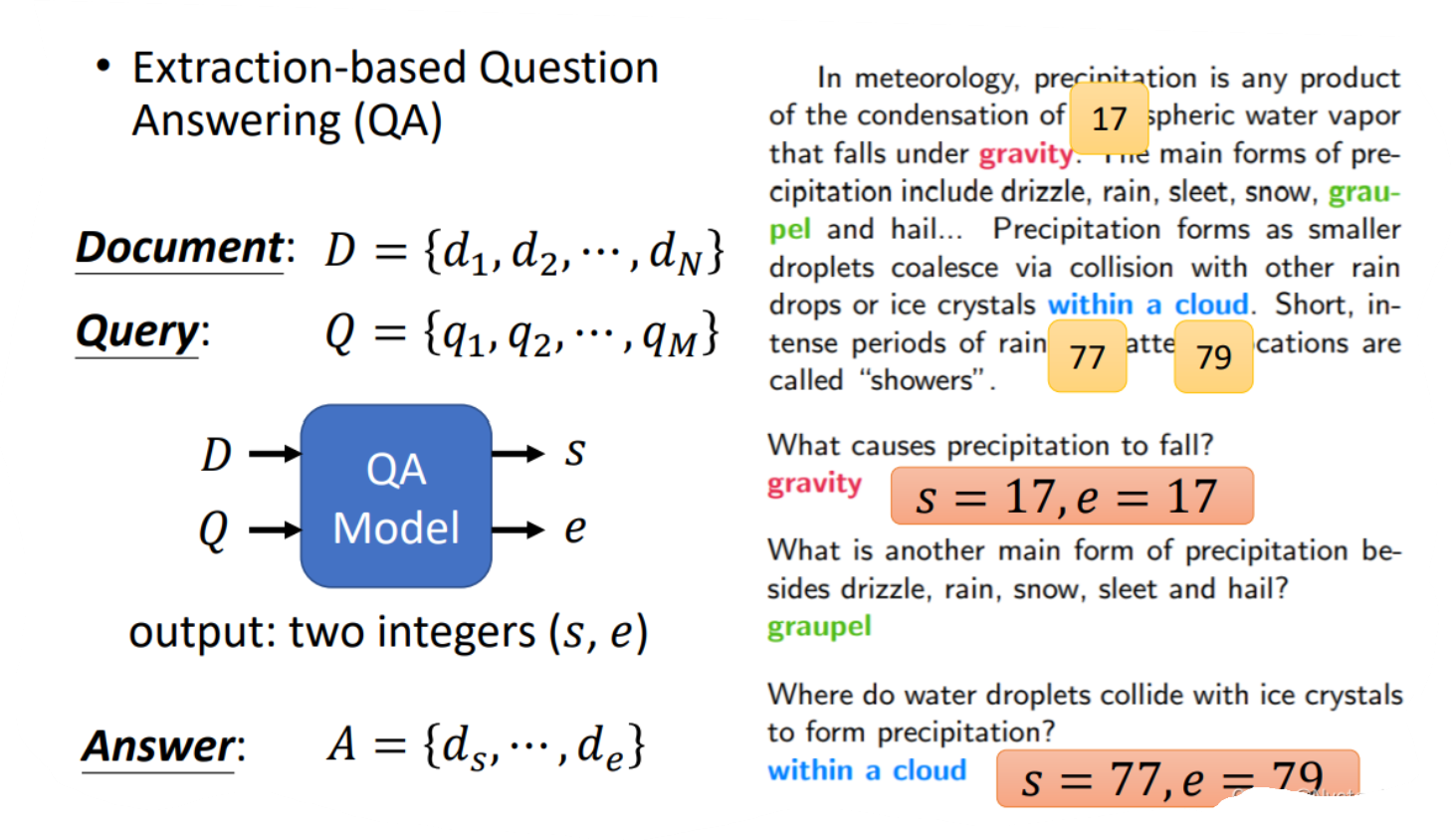
BERT还可以用来做问答模型!但是对这个问答模型具有一定的限制,即需要提供给它一篇文章和一系列问题,并且要保证这些问题的答案都在文章之间出现过,那么经过BERT处理之后将会对一个问题输出两个正整数,这两个正整数就代表问题的答案在文章中的第几个单词到第几个单词这样截出来的句子,即下图的s和e就能够截取出正确答案。
七、pre-train a seq2seq model
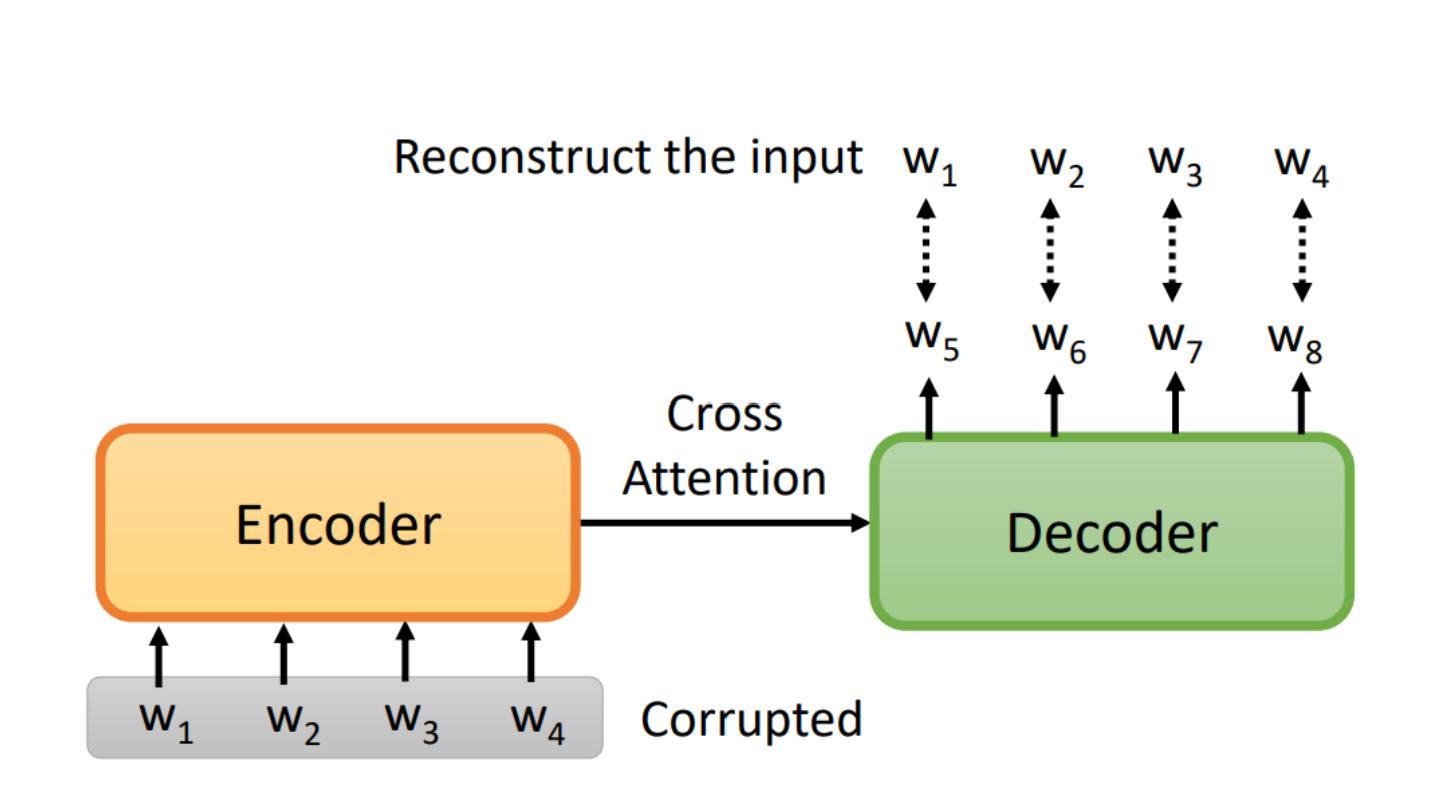
在一个transformer的模型中,将输入的序列损坏,然后该模型的输出是还原损坏的输入。如何损坏输入数据呢?可以采用mass或BART手段,mass是盖住某些数据(类似于masking),BART是综合了右边所有的方法(盖住数据、删除数据、打乱数据顺序、旋转数据等等),BART的效果要比mass好!!
三、BERT的奇闻轶事
一、为什么做填空题的BERT有用
pre-train的BERT会做填空题,那为什么微调一下就能用作其他的应用呢?
在BERT中,如果我们给它一个句子,也就是一排向量,那么它对应输出的向量可以认为里面包含了对应输入向量文字的含义,怎么理解呢?看下面的例子,例如我们给输入”台湾大学“,那么BERT的对应”大“的输出其实可以认为它是知道其含义的。这么说明可能有点抽象,我们需要通过下一个例子来解释。
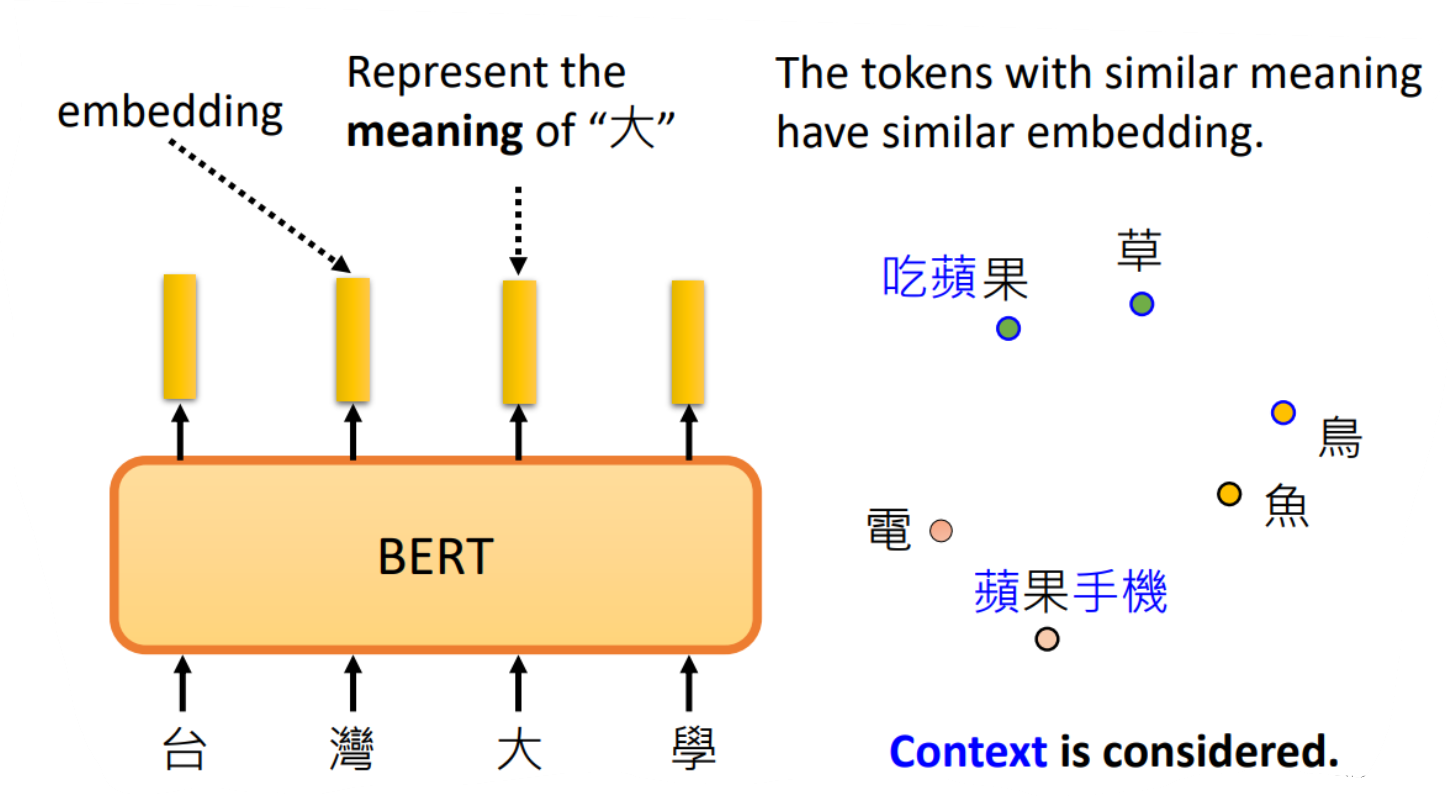
由于中文中常常存在一词多意,那么现在假设苹果的苹的两个含义,收集关于苹果的各种句子和关于苹果手机的各种句子让BERT先进行训练, 然后再输入关于苹果的五条句子和关于苹果手机的五条句子,如下图:
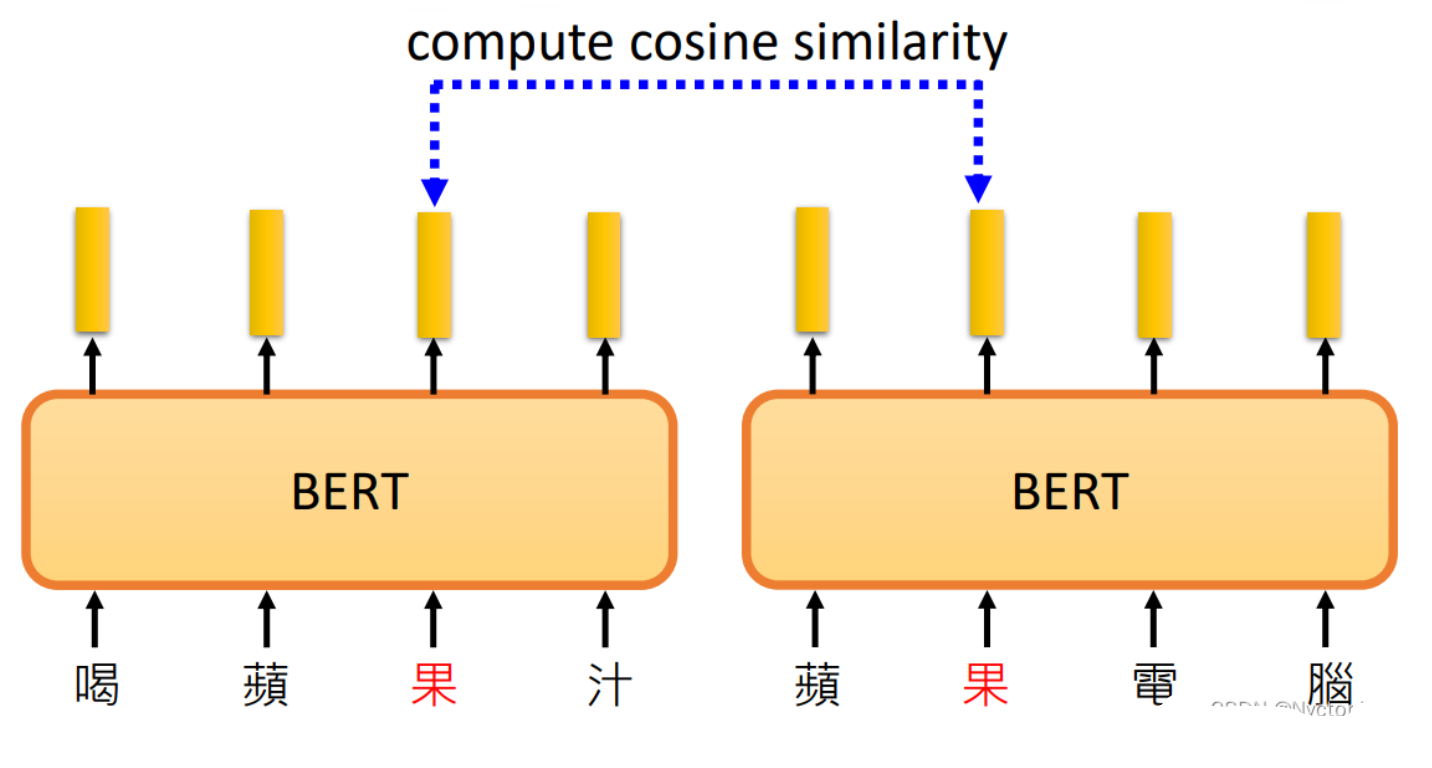
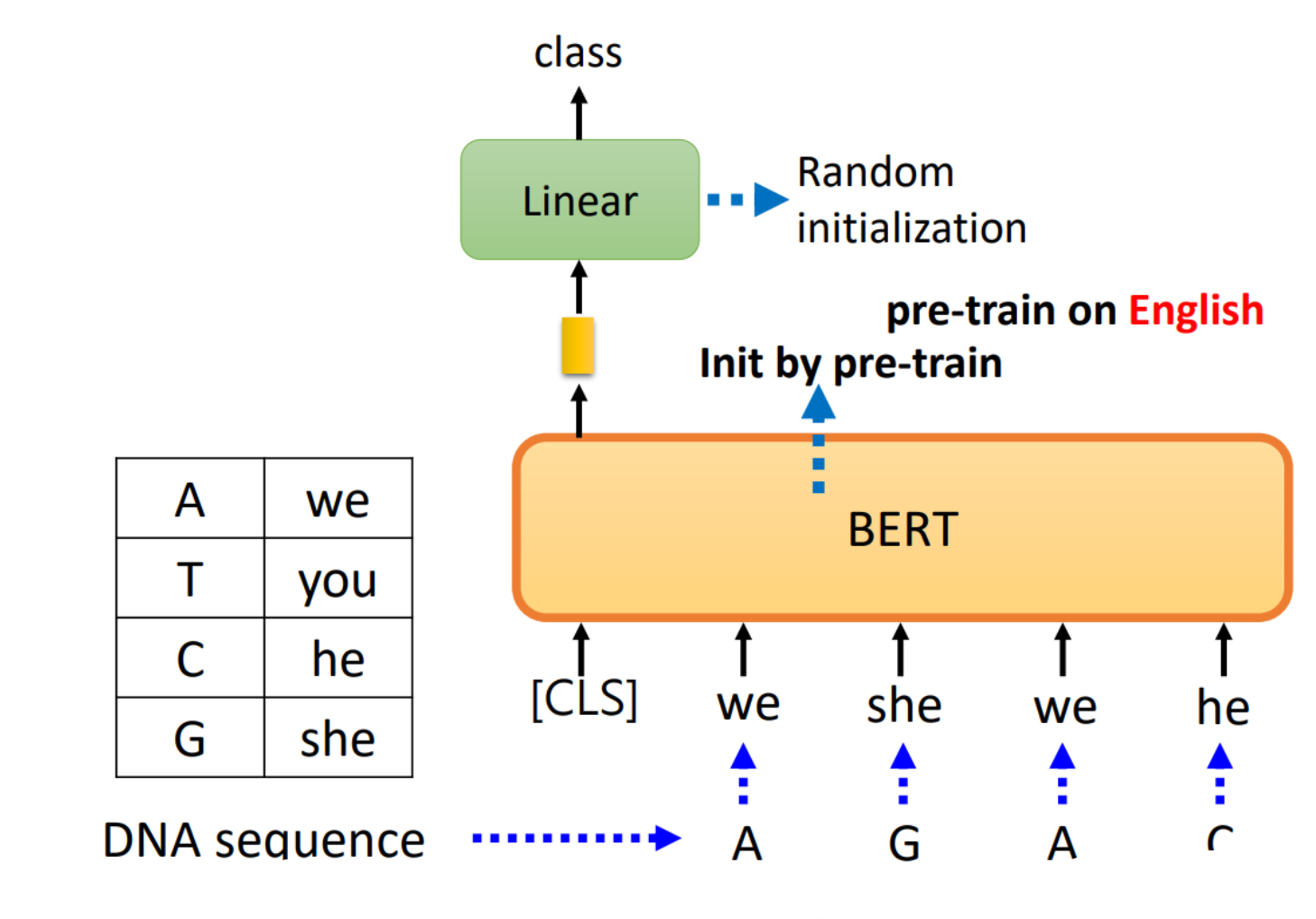
但是,应用BERT来研究蛋白质、DNA、音乐分类等问题中在,使用we,you等字代替氨基酸,最后训练出来的结果竟然会比较好,所以可能BERT的初始化参数就比较好,而与语义没有关系(一种推测,BERT内部结构还有很多问题尚待研究)。
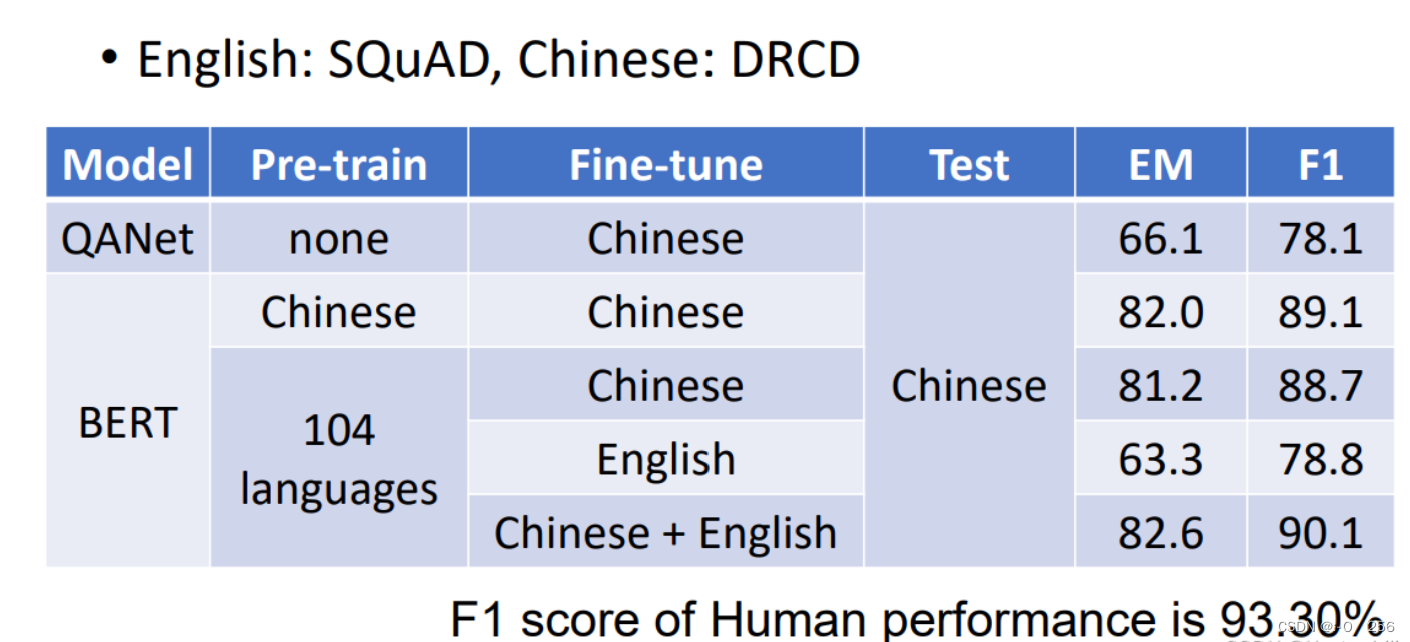
二、Multi-lingual BERT
这个模型也就是用很多种语言来训练一个模型,那么有一个实验室表现了BERT的神奇之处,也就是用了104种语言Pre-trainBERT,也就是教BERT做填空题,然后再用英文的问答资料来教BERT做英文的问答题,再在测试集中用中文的问答题来测试BERT,它的结果如下,可以达到这个正确率真的很令人吃惊!因为在BERT之前最好的是QANet,它的正确率比这样的BERT还低!
四、GPT的野望
GPT做的事情和BERT所做的填空题是不一样的,GPT具体做的是根据当前的输入预测下一个时刻可能的token,例如下图:
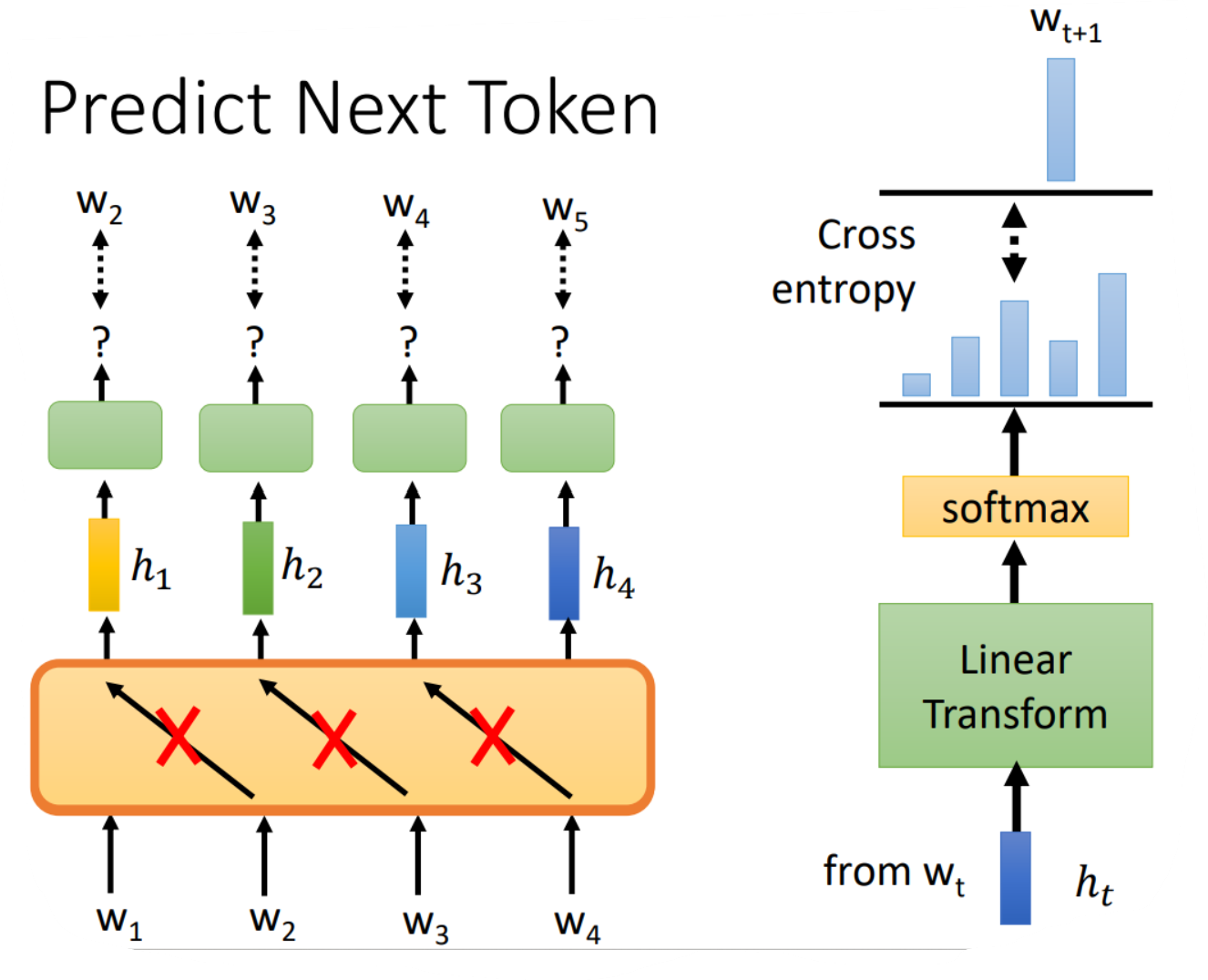
即给出Begin of Sequence,就预测出台,然后给出BOS和台就预测出湾,以此类推。对输出向量的处理就是右边那部分,先经过一个线性变化后再经过softmax得到结果向量,再跟理想结果来计算交叉熵,然后是最小化交叉熵来训练的。
总结
自监督式学习是一种无需外部标签的学习方法,这种方法在解决数据标记困难和昂贵的问题上具有巨大潜力,并提高了模型在未标记数据上的泛化能力。BERT是一种基于Transformer架构的预训练语言模型,它通过在大规模未标记的文本数据上进行预训练,学习到丰富的语言表示。















 1125
1125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









