







LinkedHashMap的底层原理
LinkedHashMap是一个继承HashMap实现Map的一个类,那么LinkedHashMap与HashMap相比他们之间又有什么不同?
基本属性
/**
* The head (eldest) of the doubly linked list.
*/
//Entry 头节点
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
//Entry 尾结点
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
//accessOrder 控制链表排序
final boolean accessOrder;
双链表结构
双链表的结构实现就是添加一个before和after属性
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
双链表结构的的一个好处是节点能够在删除时,不需要跟其它的节点关联,例如删除节点e,假设e的前后序节点都不为空,可直接这样进行删除:
// 将e节点的前序节点的next指针指向e节点的后续节点
e.before.next = e.next;
// 将e节点的后序节点的before指针指向e的前序节点
e.next.before = e.before;
e.before = null;
e.next = null;
那这个tail和head结点的值从何而来?
// link at the end of list
// 在每次添加值putVal没有相同key存在时候会执行创建新的结点,之后会执行newNode方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
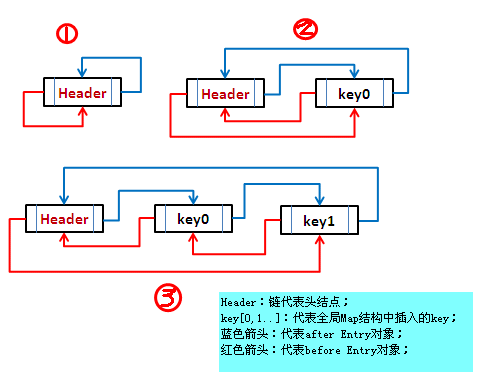
图片来自:LinkedHashMap - 每天进步一点点! - ITeye博客
查询
查询调用get方法,但是上面提到的accessOrder在这里也有,那么这个参数的的用处是什么
//true for access-order, false for insertion-order
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
//当accessOrder为true时执行下面的方法
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
//执行过后链表的顺序会发生变化
//例子: LinkedHashMap.get(3)
//原本容器中就已存在 1 —> 2 -> 3 -> 4 -> 5 一共5个key
//执行过后顺序为 1 —> 2 -> 5 -> 4 -> 3 被查询的key调换到最 后的结点
//如果不为true则照原来的输出 1 —> 2 -> 3 -> 4 -> 5
//此方法用了LRU算法,程序认为你查询的key在下一次很大概率会查到,所以做了位置交换把结点提到了最后,那么在下一次查询的很有可能查询第一次就能查到
//get方法会执行到父方法getNode
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
//如果下一次查询的还是LinkedHashMap.get(3) 那么只需要遍历一次就可以查到对应的Entry就跳出方法,优化查询效率
LRU简介:https://www.jianshu.com/p/d533d8a66795
//afterNodeInsertion在putVal里面存在当有新的元素插入时执行,若满足removeEldestEntry时,则会删除LinkedHashMap中双链表对应的首个元素(从buckets和double-linked list结构中分别清除)
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
evict 参数的理解: 是否清除元素,只有在初始化构造map时(例如: 反序列,使用Map参数类型的构造方法创建对象)为false,其它时候为trues
部分内容来自:LinkedHashMap源码实现分析 | stupid_wolf (stupidwolf.github.io)















 898
898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









