






参考链接:https://voxel51.com/docs/fiftyone/tutorials/open_images.html
一、Openimage
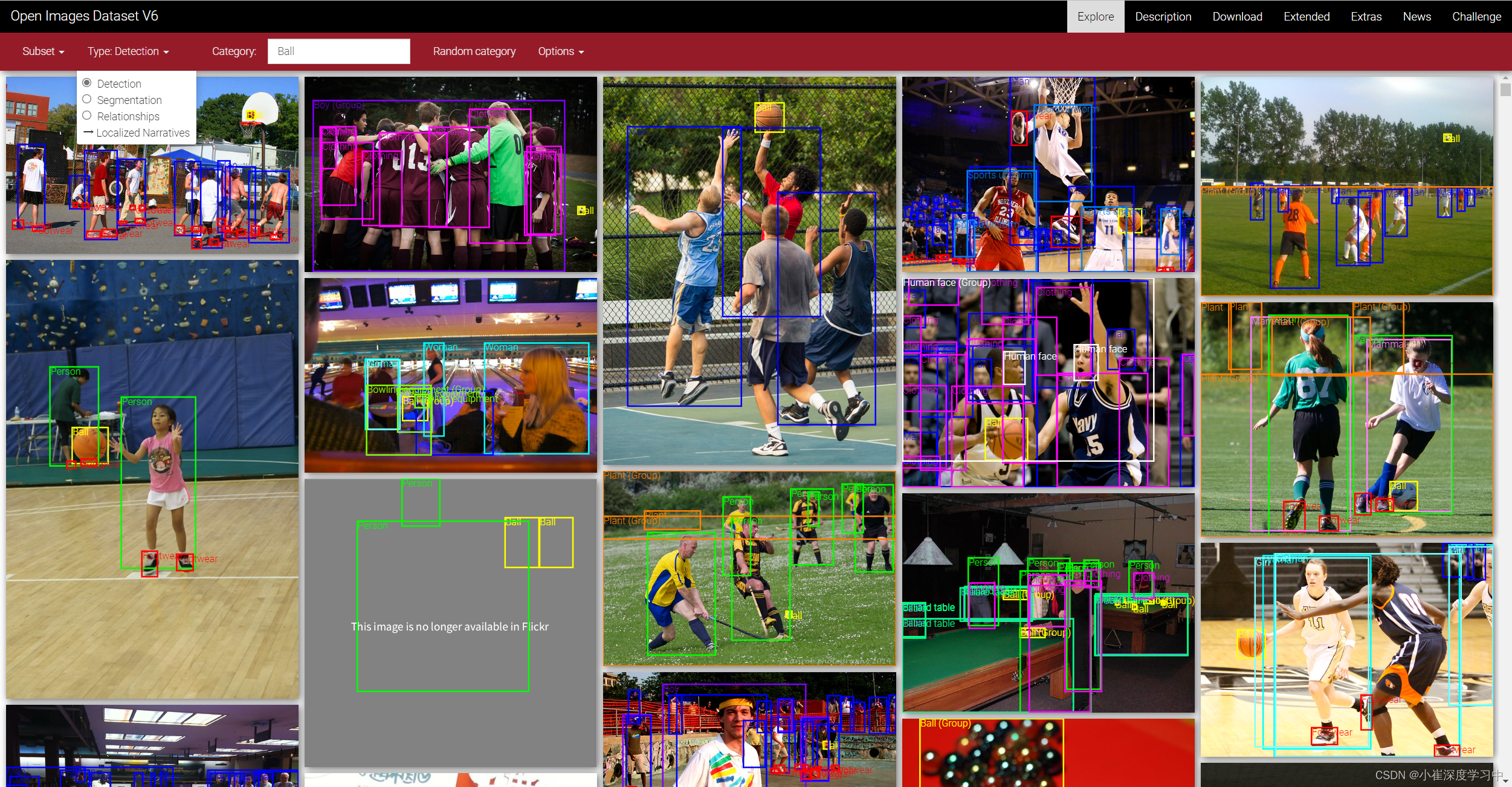
Openimage大约有九万张图片,包含六千多种类别,包括图像检测、图像分割等,在下载之前可以在explore栏先搜索自己想要的类别
先选Type再搜!第一次在搜索glove的时候没有修改type,选择的是segmentation,没有找到
二、安装fiftyone下载器
pip install fiftyone
!pip install tensorflow torch torchvision umap-learn
!pip install ipywidgets>=7.5
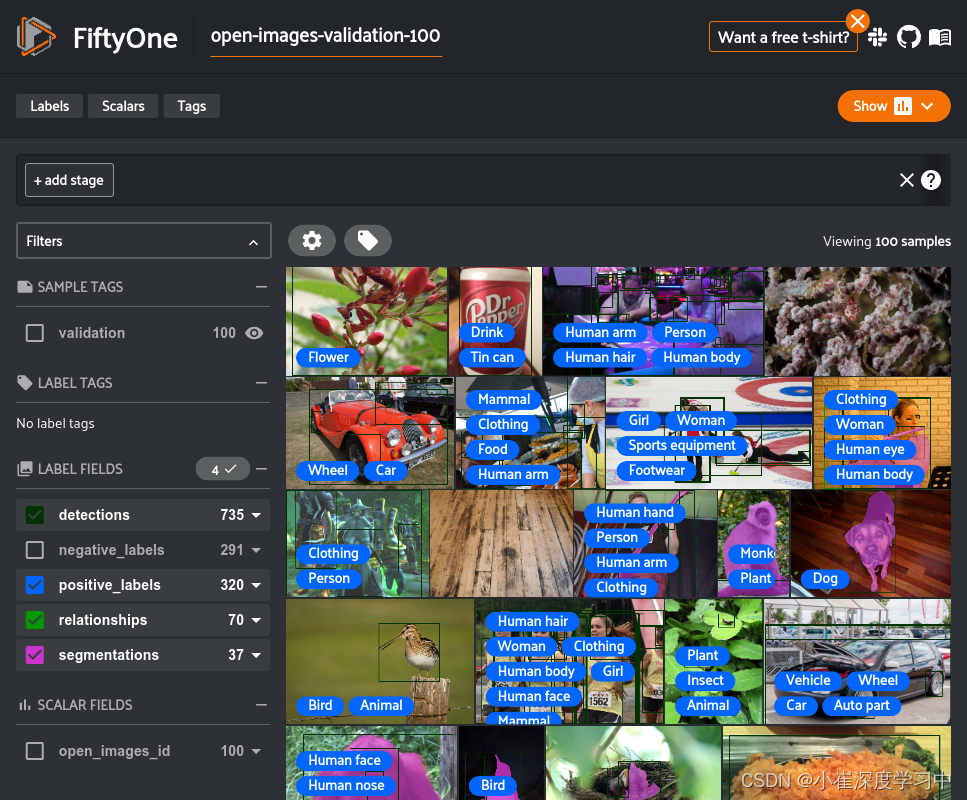
下载demo测试
import fiftyone as fo
import fiftyone.zoo as foz
dataset = foz.load_zoo_dataset(
"open-images-v6",
split="validation",
max_samples=100,
seed=51,
shuffle=True,
)
默认的下载路径在C盘用户文件夹下的"fiftyone"文件里,注意不是".fiftyone"哦
下好了!
下载特定的数据集,数据集的数量以及下载路径
参数说明:
label_types- a list of label types to load. The supported values are (“detections”, “classifications”, “segmentations”, “relationships”). By default, all available labels types will be loaded. Specifying [] will load only the images
classes- a list of classes of interest. If specified, only samples with at least one object, segmentation, or image-level label in the specified classes will be downloaded
attrs- a list of attributes of interest. If specified, only download samples if they contain at least one attribute in attrs or one class in classes (only applicable when label_types contains “relationships”)
load_hierarchy- whether to load the class hierarchy into dataset.info[“hierarchy”]
image_ids- an array of specific image IDs to download
image_ids_file - a path to a .txt, .csv, or .json file containing image IDs to download
In addition, like all other zoo datasets, you can specify:
max_samples- the maximum number of samples to load
shuffle- whether to randomly chose which samples to load if max_samples is given
seed- a random seed to use when shuffling
代码
if __name__ == '__main__':
dataset_test = foz.load_zoo_dataset(
"open-images-v6",
split="train",# 指定下载数据集
classes=["Helmet","Glove"],
shuffle=True,
max_samples=100, # 指定下载图片数
only_matching=True,
label_types=["detections"], # 指定下载目标检测的类型,detections,segmentation,relationships,classifications
dataset_dir="D:\\RAS\OpenImg\Helmet_Glove1",# 保存的路径
num_workers=2, # 指定工作进程数
)
数据格式转换
转换csv格式变成yolov5标准格式
···
import fiftyone as fo
import fiftyone.zoo as foz
import fiftyone.zoo as foz
from fiftyone import ViewField as F
dataset = foz.load_zoo_dataset(“open-images-v6”,
split=“train”,
max_samples=10,
dataset_dir=“E:\Helmet_Glove\Fiftyone”,
label_types=[‘detections’],
classes=[‘Helmet’],
seed=51,
shuffle=True,)
dataset = dataset.filter_labels(“detections”, F(“label”).is_in([“Helmet”]))
dataset.export(
export_dir=‘E:\Helmet_Glove\Fiftyone\datasets’, # 输出路径
dataset_type=fo.types.YOLOv5Dataset,
label_field=‘detections’,
)
···















 2309
2309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









