







Open Images Dataset V6是谷歌开源的一个强大的图像公开数据集,里面包含约 900 万张图像,600个类别。可用于图像分类、对象检测、视觉关系检测、实例分割和多模态图像描述。
下图为该数据集的600个类别:
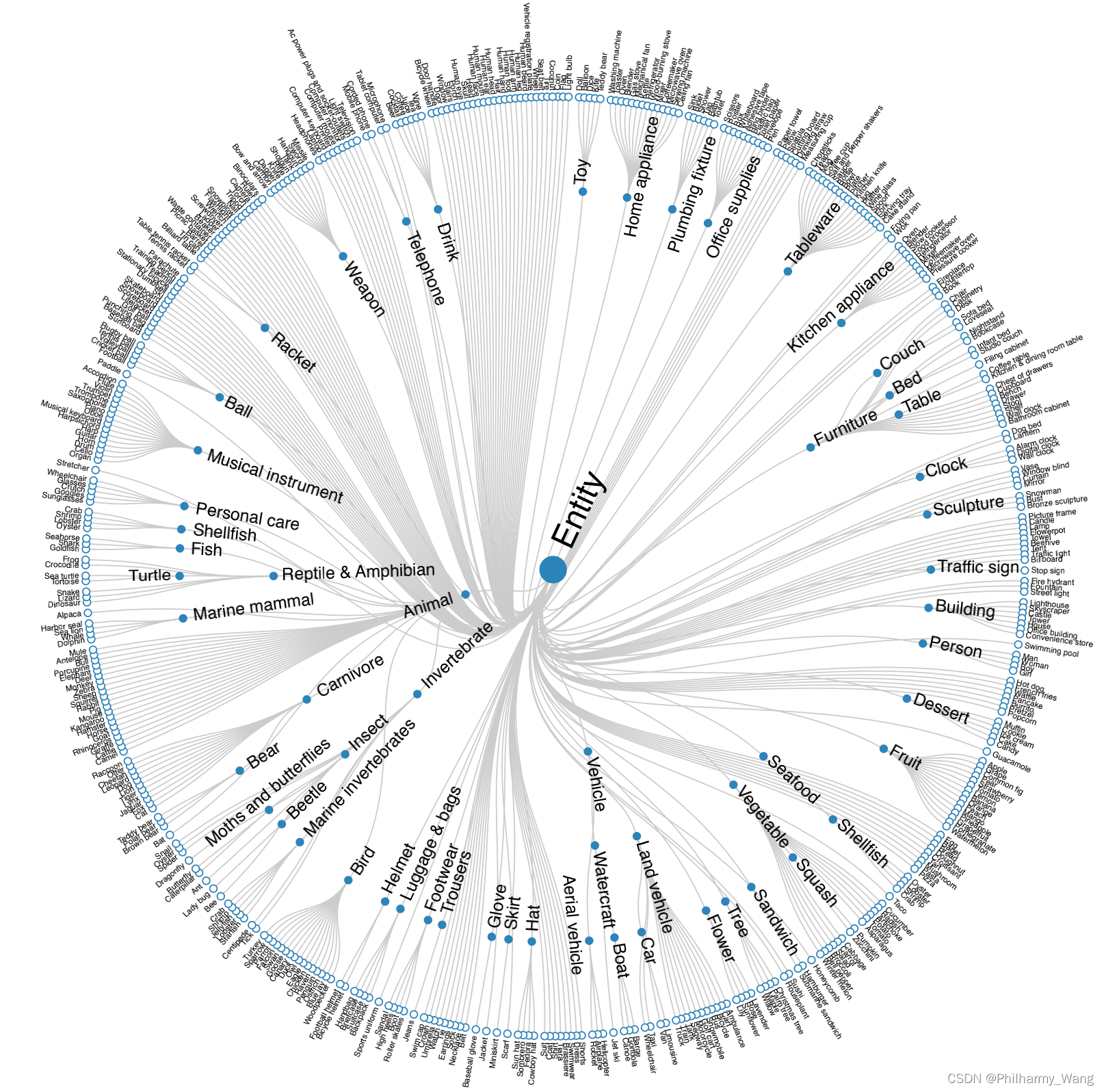
可在链接中预览某个类别/某个图像任务的标注框。
数据集的详细信息可参考论文:The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale
接下来正文开始,介绍一下如何制作可在darknet中训练的自定义数据集。
1. 克隆github项目(首次运行)
项目地址:https://github.com/theAIGuysCode/OIDv4_ToolKit ,将项目克隆到本地。
打开: ~/OIDv4_ToolKit-master,执行指令:pip install -r requirements.txt
2.开始下载图象
2.1 先去数据集网站 https://storage.googleapis.com/openimages/web/index.html
搜索对应的类别,下面以Balloon,Airplane和Bell pepper为例。
若下载两个类别的数据,如Balloon,Airplane(各400张),执行指令
python main.py downloader --classes Balloon Airplane --type_csv train --limit 400
注1:若某类别有两个单词,中间的空格用下划线_来代替。
如Bell pepper:python main.py downloader --classes Bell_pepper --type_csv train --limit 400
注2:运行上述指令之后,需要耐心等待一段时间才会开始下载。
注3:执行命令python3 main.py -h可查看帮助指令。
注4:执行指令python main.py downloader --classes Aircraft Weapon --type_csv test --limit 100 --multiclasses 1可将多个类别一个文件夹
下载界面:
python main.py downloader --classes Balloon Airplane --type_csv train --limit 400
___ _____ ______ _ _
.' `.|_ _||_ _ `. | | | |
/ .-. \ | | | | `. \ _ __ | |__| |_
| | | | | | | | | |[ \ [ ]|____ _|
\ `-' /_| |_ _| |_.' / \ \/ / _| |_
`.___.'|_____||______.' \__/ |_____|
_____ _ _
(____ \ | | | |
_ \ \ ___ _ _ _ ____ | | ___ ____ _ | | ____ ____
| | | / _ \| | | | _ \| |/ _ \ / _ |/ || |/ _ )/ ___)
| |__/ / |_| | | | | | | | | |_| ( ( | ( (_| ( (/ /| |
|_____/ \___/ \____|_| |_|_|\___/ \_||_|\____|\____)_|
[INFO] | Downloading Balloon.
[ERROR] | Missing the train-annotations-bbox.csv file.
[DOWNLOAD] | Do you want to download the missing file? [Y/n] y
...100%, 1138 MB, 5640 KB/s, 206 seconds passed
[DOWNLOAD] | File train-annotations-bbox.csv downloaded into OID/csv_folder/train-annotations-bbox.csv.
-----------------------------------------------------------------------Balloon-----------------------------------------------------------------------
[INFO] | Downloading train images.
[INFO] | [INFO] Found 3262 online images for train.
[INFO] | Limiting to 400 images.
[INFO] | Download of 400 images in train.
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [06:15<00:00, 1.07it/s]
[INFO] | Done!
[INFO] | Creating labels for Balloon of train.
[INFO] | Labels creation completed.
[INFO] | Downloading Airplane.
-----------------------------------------------------------------------Airplane-----------------------------------------------------------------------
[INFO] | Downloading train images.
[INFO] | [INFO] Found 12003 online images for train.
[INFO] | Limiting to 400 images.
[INFO] | Download of 400 images in train.
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 400/400 [04:34<00:00, 1.46it/s]
[INFO] | Done!
[INFO] | Creating labels for Airplane of train.
[INFO] | Labels creation completed.
2.2 数据预处理
下载后的数据存储在文件夹OID/Dataset/train/,每个类别的文件包括对应的image和label。
对应的label为txt文件,打开后为:
Airplane 48.0 268.23846499999996 972.8 561.4438100000001
对应的四个数值分别为:XMin, XMax, YMin, YMax。
目前的label格式并不能直接拿来在Darknet中进行训练,需对其进行转换为YOLO接受的格式。
- 打开
classes.txt,将里面的内容改为需要转换的类别。
在本例中,将其改为:
Airplane
Balloon
- 运行指令
python convert_annotations.py,转换label格式。
代码如下:
import os
import cv2
import numpy as np
from tqdm import tqdm
import argparse
import fileinput
# function that turns XMin, YMin, XMax, YMax coordinates to normalized yolo format
def convert(filename_str, coords):
os.chdir("..")
image = cv2.imread(filename_str + ".jpg")
coords[2] -= coords[0]
coords[3] -= coords[1]
x_diff = int(coords[2]/2)
y_diff = int(coords[3]/2)
coords[0] = coords[0]+x_diff
coords[1] = coords[1]+y_diff
coords[0] /= int(image.shape[1])
coords[1] /= int(image.shape[0])
coords[2] /= int(image.shape[1])
coords[3] /= int(image.shape[0])
os.chdir("Label")
return coords
ROOT_DIR = os.getcwd()
# create dict to map class names to numbers for yolo
classes = {}
with open("classes.txt", "r") as myFile:
for num, line in enumerate(myFile, 0):
line = line.rstrip("\n")
classes[line] = num
myFile.close()
# step into dataset directory
os.chdir(os.path.join("OID", "Dataset"))
DIRS = os.listdir(os.getcwd())
# for all train, validation and test folders
for DIR in DIRS:
if os.path.isdir(DIR):
os.chdir(DIR)
print("Currently in subdirectory:", DIR)
CLASS_DIRS = os.listdir(os.getcwd())
# for all class folders step into directory to change annotations
for CLASS_DIR in CLASS_DIRS:
if os.path.isdir(CLASS_DIR):
os.chdir(CLASS_DIR)
print("Converting annotations for class: ", CLASS_DIR)
# Step into Label folder where annotations are generated
os.chdir("Label")
for filename in tqdm(os.listdir(os.getcwd())):
filename_str = str.split(filename, ".")[0]
if filename.endswith(".txt"):
annotations = []
with open(filename) as f:
for line in f:
for class_type in classes:
line = line.replace(class_type, str(classes.get(class_type)))
labels = line.split()
coords = np.asarray([float(labels[1]), float(labels[2]), float(labels[3]), float(labels[4])])
coords = convert(filename_str, coords)
labels[1], labels[2], labels[3], labels[4] = coords[0], coords[1], coords[2], coords[3]
newline = str(labels[0]) + " " + str(labels[1]) + " " + str(labels[2]) + " " + str(labels[3]) + " " + str(labels[4])
line = line.replace(line, newline)
annotations.append(line)
f.close()
os.chdir("..")
with open(filename, "w") as outfile:
for line in annotations:
outfile.write(line)
outfile.write("\n")
outfile.close()
os.chdir("Label")
os.chdir("..")
os.chdir("..")
os.chdir("..")
转换后生成的文件在image目录,打开后为:
0 0.56421875 0.5209378333333333 0.86875 0.339166
其中,0对应之前classes.txt中的类别,对应的数字为转换后的标准化数据格式
3.将数据导入至Darknet
- 打开Darknet的
data文件夹,创建文件夹obj; - 将下载的数据按照步骤2进行转换,并将其拷贝至
obj文件夹,并把对应类别classes.txt拷贝到data文件夹下; - 创建
.data文件,根据数据集修改classes,train文件路径,valid文件路径,names文件路径,backup文件路径; - 新建python文件
generate_train.py,代码如下:
import os
image_files = []
os.chdir(os.path.join("data", "obj"))
for filename in os.listdir(os.getcwd()):
if filename.endswith(".jpg"):
image_files.append("data/obj/" + filename)
os.chdir("..")
with open("train.txt", "w") as outfile:
for image in image_files:
outfile.write(image)
outfile.write("\n")
outfile.close()
os.chdir("..")
- 执行指令
python generate_train.py,在./data文件夹下会生成train.txt文件。

















 451
451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









