









微信公众号:数学建模与人工智能
https://github.com/QInzhengk/Math-Model-and-Machine-Learning
1、决策树
分类决策树模型DecisionTreeClassifier()模型常用的一些超参数及它们的解释
- criterion:特征选择标准,取值为"entropy"信息熵和"gini"基尼系数,默认选择"gini"。
- splitter:取值为"best"和"random","best"在特征的所有划分点中找出最优的划分点,适合样本量不大的情况,"random"随机地在部分划分点中找局部最优的划分点,适合样本量非常大的情况,默认选择"best"。
- max_depth:决策树最大深度,取值为int或None,一般数据或特征比较少的时候可以不设置,如果数据或特征比较多时,可以设置最大深度进行限制。默认取‘None’。
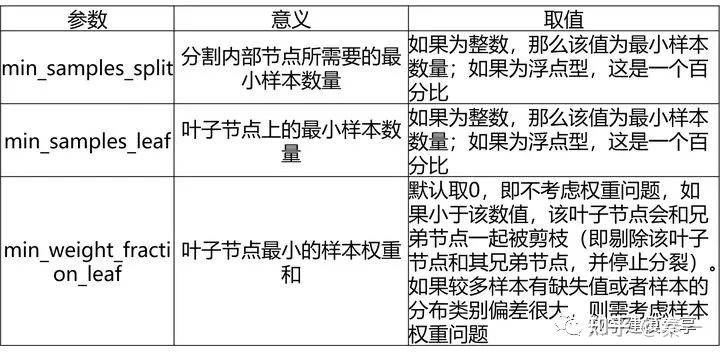
- min_samples_split:子节点往下划分所需的最小样本数,默认取2,如果子节点中的样本数小于该值则停止分裂。
- min_samples_leaf:叶子节点的最少样本数,默认取1,如果小于该数值,该叶子节点会和兄弟节点一起被剪枝(即剔除该叶子节点和其兄弟节点,并停止分裂)。
- min_weight_fraction_leaf:叶子节点最小的样本权重和,默认取0,即不考虑权重问题,如果小于该数值,该叶子节点会和兄弟节点一起被剪枝(即剔除该叶子节点和其兄弟节点,并停止分裂)。如果较多样本有缺失值或者样本的分布类别偏差很大,则需考虑样本权重问题。
- max_features:在划分节点时所考虑的特征值数量的最大值,默认取None,可以传入int型或float型数据。如果是float型数据,表示百分数。
- max_leaf_nodes:最大叶子节点数,默认取None,可以传入int型数据。
- class_weight:指定类别权重,默认取None,可以取"balanced",代表样本量少的类别所对应的样本权重更高,也可以传入字典指定权重。该参数主要是为防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。除了此处指定class_weight,还可以使用过采样和欠采样的方法处理样本类别不平衡的问题。
- random_state:当数据量较大,或特征变量较多时,可能在某个节点划分时,会碰上两个特征变量的信息熵增益或者基尼系数减少量是一样的情况,那么此时决策树模型默认是随机从中选一个特征变量进行划分,这样可能会导致每次运行程序后生成的决策树不太一致。如果设定random_state参数(如设置为123)可以保证每次运行代码时,各个节点的分裂结果都是一致的,这在特征变量较多,树的深度较深的时候较为重要。
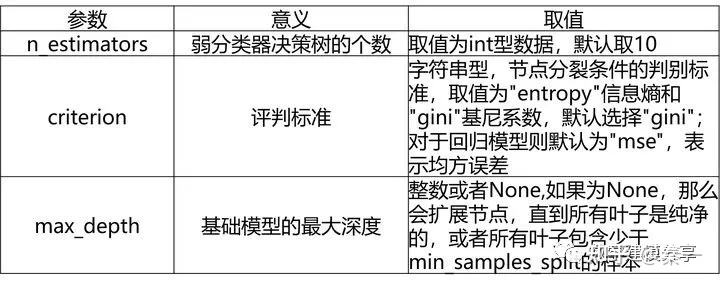
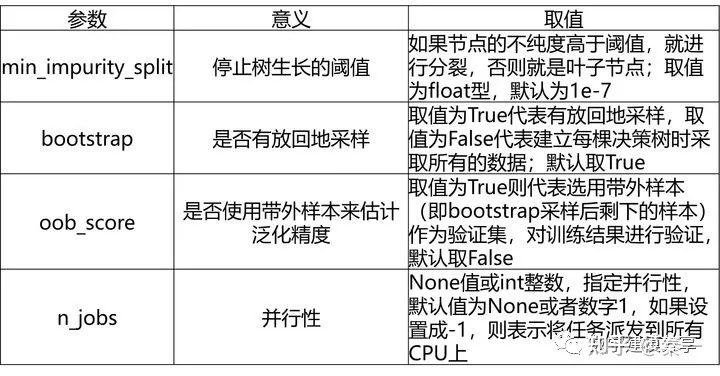
2、随机森林
随机森林分类模型(RandomForestClassifier)、随机森林回归模型(RandomForestRegressor)模型

3、AdaBoost算法
AdaBoost分类模型(AdaBoostClassifier)及AdaBoost回归模型


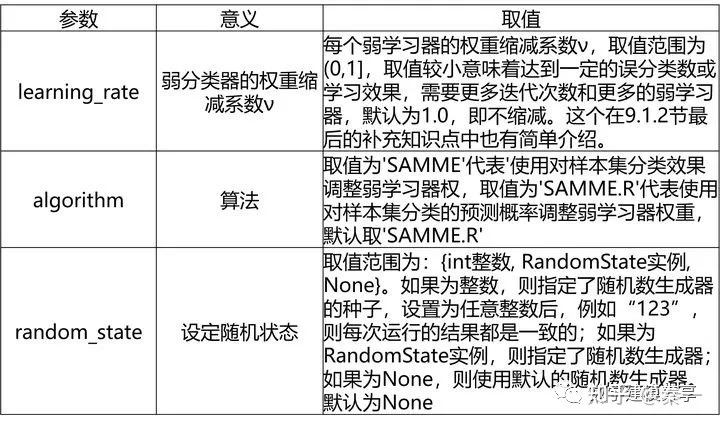
AdaBoost回归模型比分类模型多了一个loss参数

4、GDBT算法
GBDT分类模型(GradientBoostingClassifier)、GBDT回归模型(GradientBoostingRegressor)

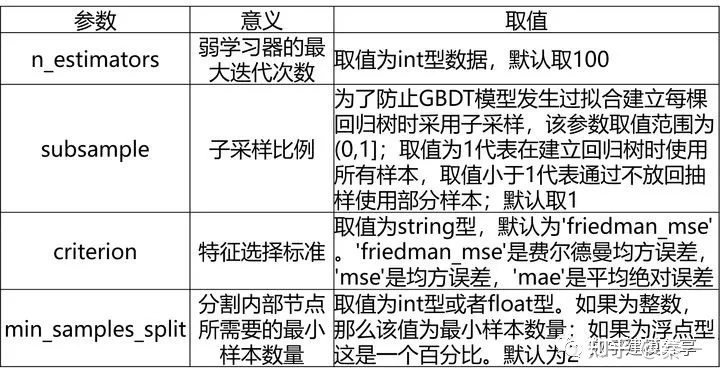
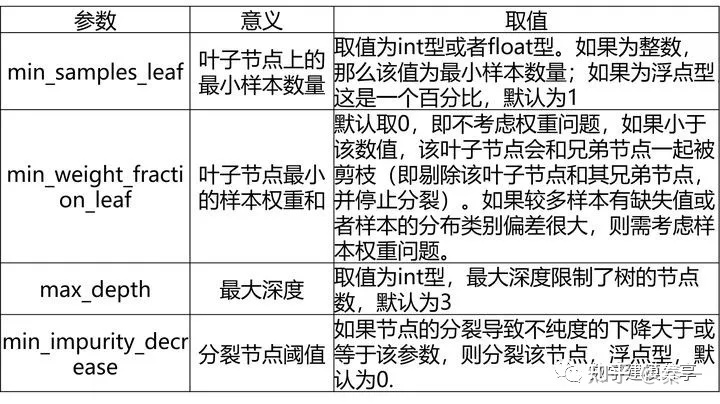


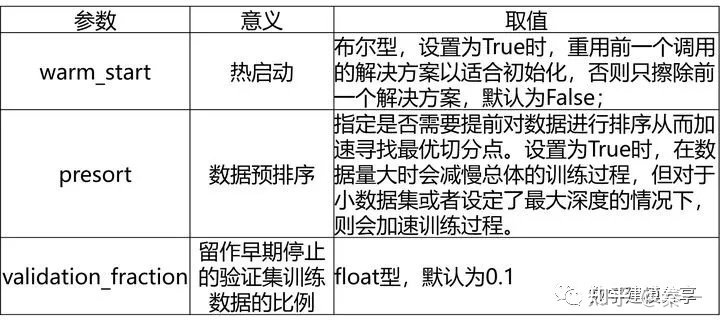
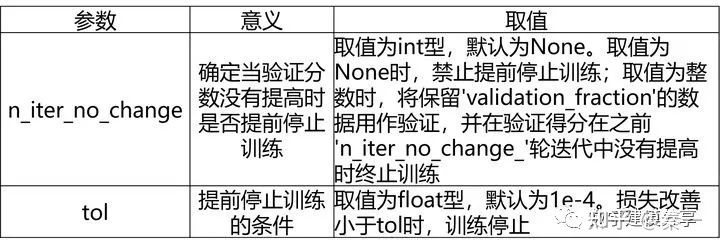
GDBT分类模型的常用参数和GDBT回归模型基本一致,唯一的不同是多了一个loss参数。
5、XGBoost算法
官方文档地址为:https://xgboost.readthedocs.io
XGBoost分类模型(XGBClassifier)及XGBoost回归模型(XGBRegressor)
XGBoost分类模型的常见超参数:
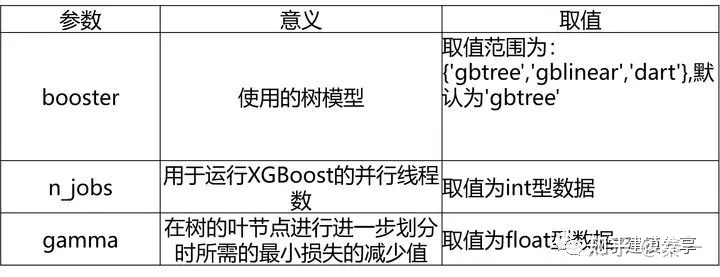
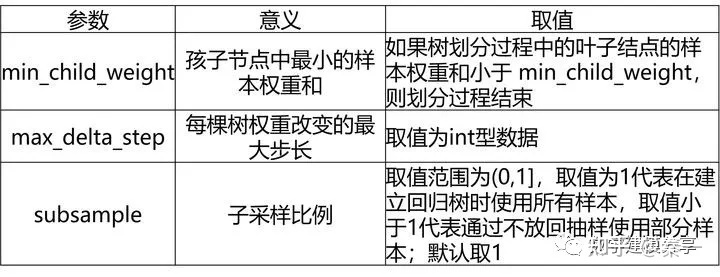
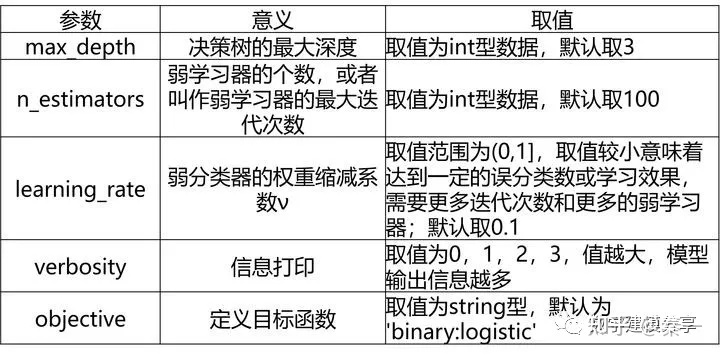

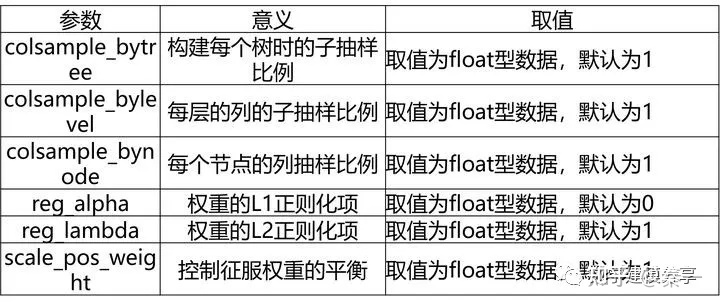
6、LightGBM算法
官方文档为:https://lightgbm.readthedocs.io
LightGBM分类模型(LGBMClassifier)及LightGBM回归模型(LGBMRegressor)
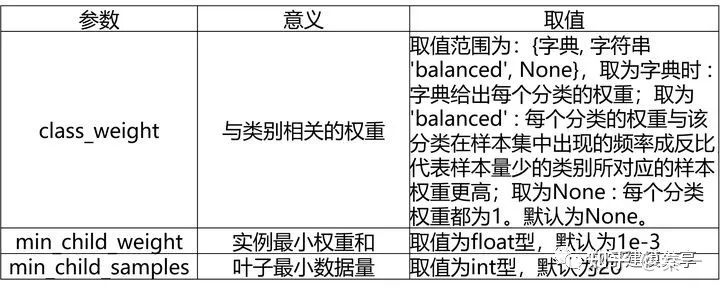
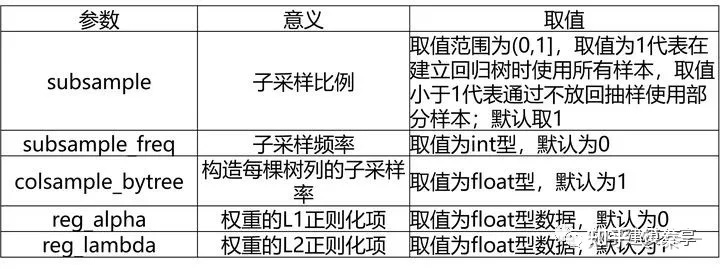
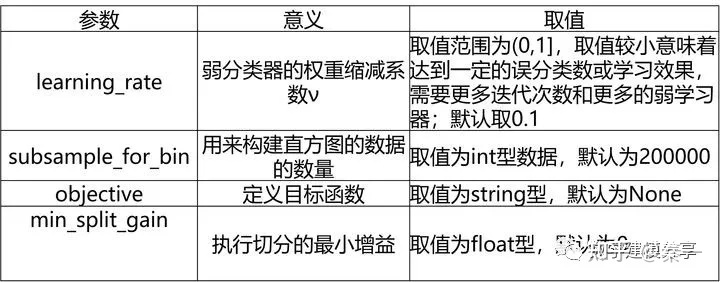
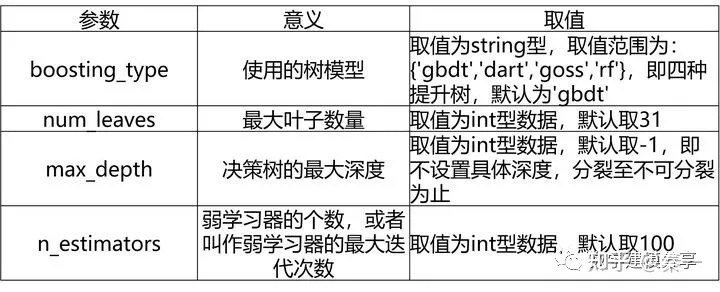
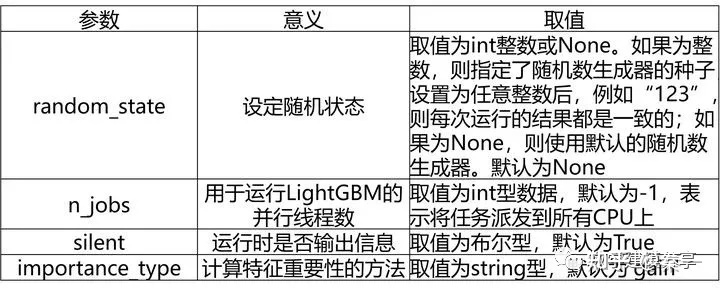
7、LightGBM的重要参数
1.1 基本参数调整
- num_leaves参数 这是控制树模型复杂度的主要参数,一般的我们会使num_leaves小于(2的max_depth次方),以防止过拟合。由于LightGBM是leaf-wise建树与XGBoost的depth-wise建树方法不同,num_leaves比depth有更大的作用。
- min_data_in_leaf 这是处理过拟合问题中一个非常重要的参数. 它的值取决于训练数据的样本个树和 num_leaves参数. 将其设置的较大可以避免生成一个过深的树, 但有可能导致欠拟合. 实际应用中, 对于大数据集, 设置其为几百或几千就足够了.
- max_depth 树的深度,depth 的概念在 leaf-wise 树中并没有多大作用, 因为并不存在一个从 leaves 到 depth 的合理映射。
1.2 针对训练速度的参数调整
- 通过设置 bagging_fraction 和 bagging_freq 参数来使用 bagging 方法。
- 通过设置 feature_fraction 参数来使用特征的子抽样。
- 选择较小的 max_bin 参数。
- 使用 save_binary 在未来的学习过程对数据加载进行加速。
1.3 针对准确率的参数调整
- 使用较大的 max_bin (学习速度可能变慢)
- 使用较小的 learning_rate 和较大的 num_iterations
- 使用较大的 num_leaves (可能导致过拟合)
- 使用更大的训练数据
- 尝试 dart 模式
1.4 针对过拟合的参数调整
- 使用较小的 max_bin
- 使用较小的 num_leaves
- 使用 min_data_in_leaf 和 min_sum_hessian_in_leaf
- 通过设置 bagging_fraction 和 bagging_freq 来使用 bagging
- 通过设置 feature_fraction 来使用特征子抽样
- 使用更大的训练数据
- 使用 lambda_l1, lambda_l2 和 min_gain_to_split 来使用正则
- 尝试 max_depth 来避免生成过深的树
8、XGBoost的重要参数
1.eta[默认0.3]
通过为每一颗树增加权重,提高模型的鲁棒性。
典型值为0.01-0.2。
2.min_child_weight[默认1]
决定最小叶子节点样本权重和。
这个参数可以避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。
但是如果这个值过高,则会导致模型拟合不充分。
3.max_depth[默认6]
这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。
典型值:3-10
4.max_leaf_nodes
树上最大的节点或叶子的数量。
可以替代max_depth的作用。
这个参数的定义会导致忽略max_depth参数。
5.gamma[默认0]
在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关。
6.max_delta_step[默认0]
这参数限制每棵树权重改变的最大步长。如果这个参数的值为0,那就意味着没有约束。如果它被赋予了某个正值,那么它会让这个算法更加保守。
但是当各类别的样本十分不平衡时,它对分类问题是很有帮助的。
7.subsample[默认1]
这个参数控制对于每棵树,随机采样的比例。
减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。
典型值:0.5-1
8.colsample_bytree[默认1]
用来控制每棵随机采样的列数的占比(每一列是一个特征)。
典型值:0.5-1
9.colsample_bylevel[默认1]
用来控制树的每一级的每一次分裂,对列数的采样的占比。
subsample参数和colsample_bytree参数可以起到相同的作用,一般用不到。
10.lambda[默认1]
权重的L2正则化项。(和Ridge regression类似)。
这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。
11.alpha[默认1]
权重的L1正则化项。(和Lasso regression类似)。
可以应用在很高维度的情况下,使得算法的速度更快。
12.scale_pos_weight[默认1]
在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。
参考:
https://tianchi.aliyun.com/course/278?spm=5176.21206777.J_3641663050.11.5b7617c9LEQth0
Python大数据分析与机器学习
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









