







- Hadoop版本: 2.7.6
- CentOS版本: 7.6.1810
- 集群: 3台
百度网盘: 提取码:1111
Hadoop HA说明
HDFS集群中NameNode 存在单点故障(SPOF)。对于只有一个NameNode的集群,如果NameNode机器出现意外情况,将导致整个集群无法使用,直到NameNode 重新启动。
HDFS自动故障转移
HDFS的自动故障转移主要由Zookeeper(Zookeeper很重要啊)和ZKFC两个组件组成。
Zookeeper集群作用主要有:
一:是故障监控。每个NameNode将会和Zookeeper建立一个持久session,如果NameNode失效,那么此session将会过期失效,此后Zookeeper将会通知另一个Namenode,然后触发Follower;
二:是NameNode选举。ZooKeeper提供了简单的机制来实现Acitve Node选举,如果当前Active失效,Standby将会获取一个特定的排他锁,那么获取锁的Node接下来将会成为Active。
HA部署就是 如果集群的一个NameNode没了,那么备胎就会被Zookeeper迅速激活
规划:
| 主机名 | 服务 |
|---|---|
| master | jdk、NameNode、DataNode、JouranlNode、ResourceManger、NodeManager |
| salve1 | jdk、NameNode、DataNode、JouranlNode、ResourceManger、NodeManager |
| salve2 | jdk、DataNode、JouranlNode、NodeManager |
注意:
-
JDK要配置好
-
Zookeeper集群要部署好
具体可以看下面这篇文章

1. 上传文件
- 上传文件的工具有很多例如SecureCRTPortable,WinSCP,Xshell.
2. SSH免密登录
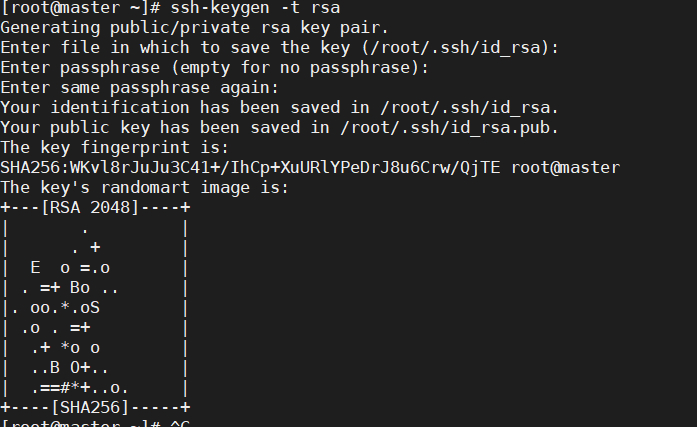
# 生成公私密钥对 一路回车即可 切记不要多按其他键 不然会出问题
# 拷贝过程中会要求 输入yes 和密码
[root@master ~]# ssh-keygen -t rsa
# 将master上的公钥拷贝到master
# 拷贝过程中会要求 输入yes 和密码
[root@master ~]# ssh-copy-id master
# 将master上的公钥拷贝到salve1
[root@master ~]# ssh-copy-id salve1
# 将master上的公钥拷贝到salve2
[root@master ~]# ssh-copy-id salve2
#要实现HA要两个NameNode 所以还要有一台机也能免密master
#这里用salve1作为为备用的NameNode 一旦master挂了 Zookeeper能迅速激活
# 生成salve1公私密钥对
[root@salve1 ~]# ssh-keygen -t rsa
# 将salve1上的公钥拷贝到salve1
[root@salve1 ~]# ssh-copy-id salve1
# 将salve1上的公钥拷贝到master
[root@salve1 ~]# ssh-copy-id master
#测试
[root@salve1 ~]ssh [跟上主机名即可]
#exit或者快捷键 ctrl+d可以登出
3. 解压并配置环境变量 三台都需要配置
#解压
[root@master ~]# tar zxvf /home/package/hadoop-2.7.6.tar.gz -C /usr/local/src/
#配置Hadoop环境变量
[root@master ~]# vi /etc/profile
#配置如下:
export HADOOP_HOME=/usr/local/src/hadoop-2.7.6/
export PATH=$PATH:$JAVA_HOME/bin:$ZK_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#刷新
[root@master ~]# source /etc/profile
#验证Hadoop环境变量配置成功否
[root@master ~]# which start-all.sh
4.修改配置文件
- 把configuration标签包裹的内容配置进去
- 注意主机名称要改
hadoop-env.sh
#进入到Hadoop的配置文件目录
[root@master /]# cd /usr/local/src/hadoop-2.7.6/etc/hadoop/
[root@master hadoop]# vi hadoop-env.sh
#修改如下
#把export JAVA_HOME=${JAVA_HOME}修改为
export JAVA_HOME=/usr/local/src/jdk1.8.0_191/
core-site.xml
[root@master hadoop]# vi core-site.xml
<configuration>
<!--指定hdfs文件系统的默认名-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://lan</value>
</property>
<!--指定zk的集群地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,salve1:2181,salve2:2181</value>
</property>
<!--指定hadoop的临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadata/tmp</value>
</property>
</configuration>
mapred-site.xml
#先改下名称
[root@master hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
<configuration>
<!--配置mapreduce的框架名称-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<!--指定jobhistoryserver的内部通信地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!--指定jobhistoryserver的web地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
hdfs-site.xml
[root@master hadoop]# vi hdfs-site.xml
<configuration>
<!--指定块的副本数,默认是3-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定数据块的大小-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!--指定namenode的元数据目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadata/dfs/name</value>
</property>
<!--指定datanode存储数据目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadata/dfs/data</value>
</property>
<!--hdfs的命名空间,逻辑名称-->
<property>
<name>dfs.nameservices</name>
<value>lan</value>
</property>
<!--qianfeng下的namenode的别名-->
<property>
<name>dfs.ha.namenodes.lan</name>
<value>nn1,nn2</value>
</property>
<!--指定nn1和nn2的通信地址-->
<property>
<name>dfs.namenode.rpc-address.lan.nn1</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.lan.nn2</name>
<value>salve1:9000</value>
</property>
<!--指定namenode的web通信地址-->
<property>
<name>dfs.namenode.http-address.lan.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.lan.nn2</name>
<value>salve1:50070</value>
</property>
<!--指定共享日志目录-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;salve1:8485;salve2:8485/lan</value>
</property>
<!--指定开启namenode失败自动转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--指定失败转移的类-->
<property>
<name>dfs.client.failover.proxy.provider.lan</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--防止namenode的脑裂-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--指定超时时间设置-->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!--指定日志的本地目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadata/journal1</value>
</property>
<!--是否开启webhdfs的-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--是否开启hdfs的权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
yarn-site.xml
[root@master hadoop]# vi yarn-site.xml
<configuration>
<!--指定mapreduce的shuffle服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--是否开启yarn的HA-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>qianfeng_yarn</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>salve1</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>salve1:8088</value>
</property>
<!--指定zookeeper的集群地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,salve1:2181,salve2:2181</value>
</property>
</configuration>
slaves
[root@master hadoop]# vi slaves
#把localhost删除
#写三个主机的名称
master
salve1
salve2
5.远程拷贝
[root@master hadoop]# scp -r /usr/local/src/hadoop-2.7.6/ salve1:/usr/local/src/
[root@master hadoop]# scp -r /usr/local/src/hadoop-2.7.6/ salve2:/usr/local/src/
6.测试NameNode的HA:
#确保Zookeeper已经启动
1. #先启动JournalNode
[root@master hadoop-2.7.6]# hadoop-daemons.sh start journalnode
2. # 选择其中一个namenode进行格式化
[root@master ~]# hdfs namenode -format
3. #并启动namenode进程
[root@master ~]#hadoop-daemon.sh start namenode
4. #在另一台namenode上拉取已格式化的那台机器的镜像文件(数据的一致性)
[root@salve1 ~]# hdfs namenode -bootstrapStandby
5. #格式化zkfc
- 1、前提QuorumPeerMain服务必须处于开启状态,客户端zkfc才能格式化成功
[root@master ~]# zkServer.sh start
[root@salve1 ~]# zkServer.sh start
[root@salve2 ~]# zkServer.sh start
- 2、选择其中一个namenode节点进行格式化zkfc(master 和 salve1)
[root@master ~]# hdfs zkfc -formatZK
6.#启动所有服务
[root@master hadoop]# start-all.sh
#停止所有服务
[root@master hadoop]# stop-all.sh

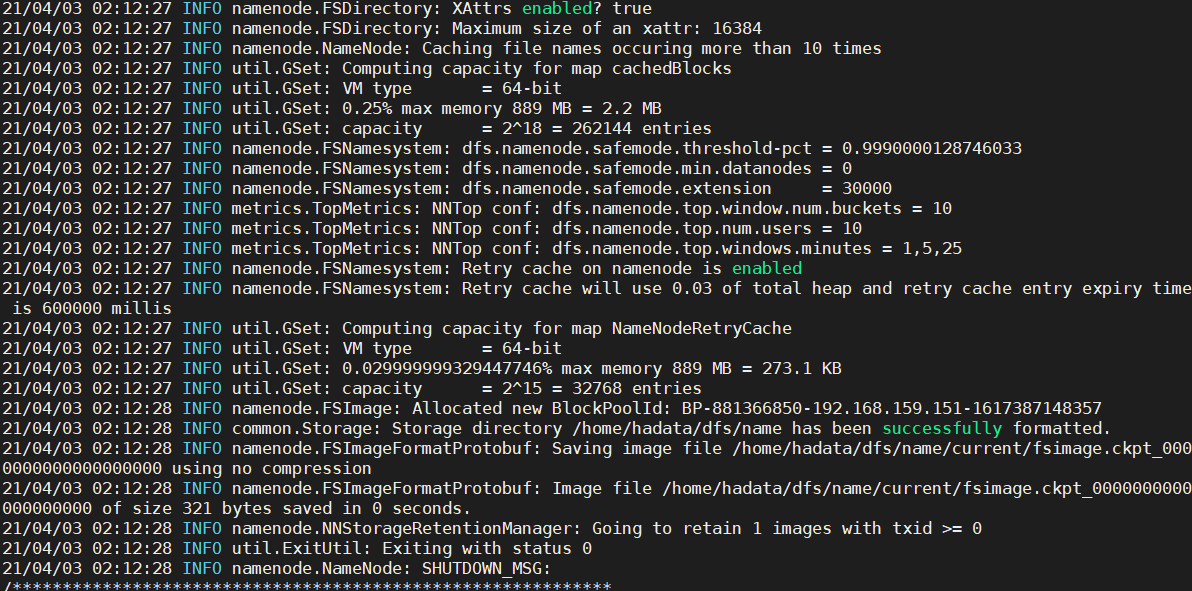
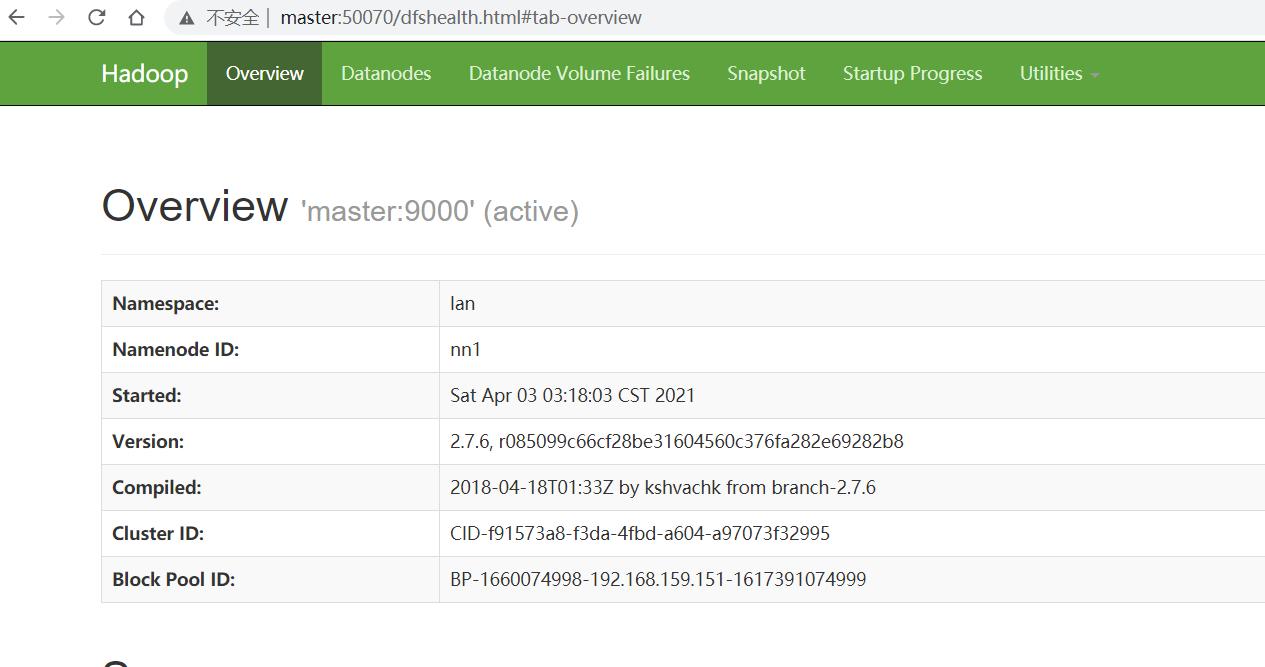
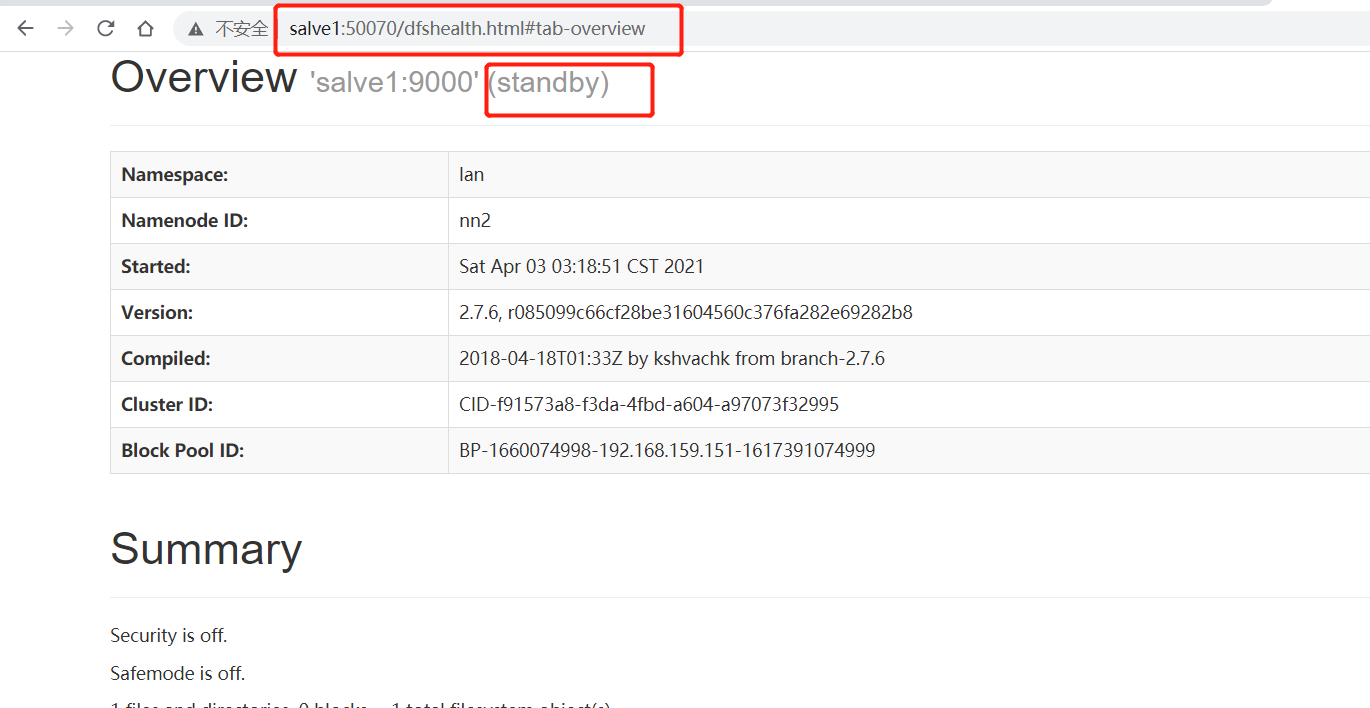
#先停止master的NameNode
#查看
[root@master hadoop]# jps
82513 DataNode
50097 QuorumPeerMain
81671 JournalNode
82007 NameNode
84710 Jps
82843 DFSZKFailoverController
83083 NodeManager
82973 ResourceManager
[root@master hadoop]# jps
82513 DataNode
50097 QuorumPeerMain
81671 JournalNode
82007 NameNode
82843 DFSZKFailoverController
83083 NodeManager
82973 ResourceManager
89756 Jps
#杀死NameNode
[root@master hadoop]# kill -9 82007
#再进去web看下 salve1的standby 已经变成active
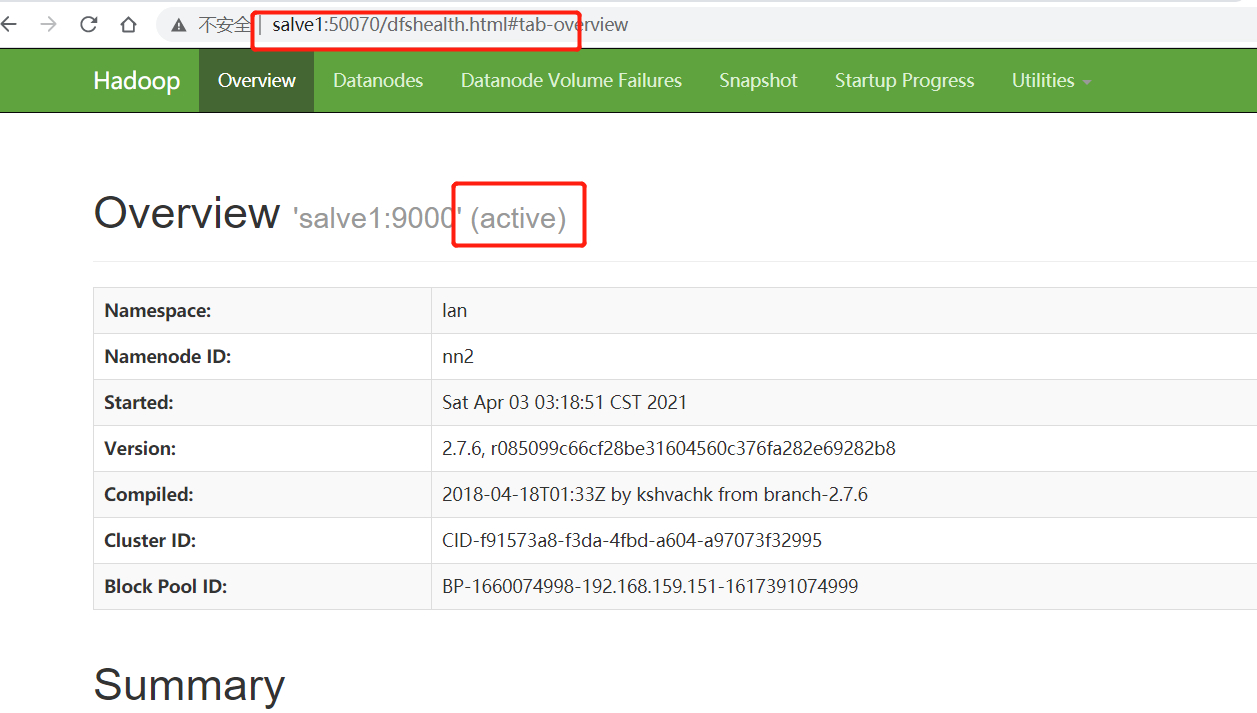
7.测试上传文件
[root@master ~]# hdfs dfs -ls hdfs://salve1:9000/
[root@master bak]# touch e.txt
#在hdfs创建bak文件目录
[root@master bak]# hdfs dfs -mkdir hdfs://salve1:9000/bak
#上传文件到hdfs的bak目录下
[root@master bak]# hdfs dfs -put e.txt hdfs://salve1:9000/bak
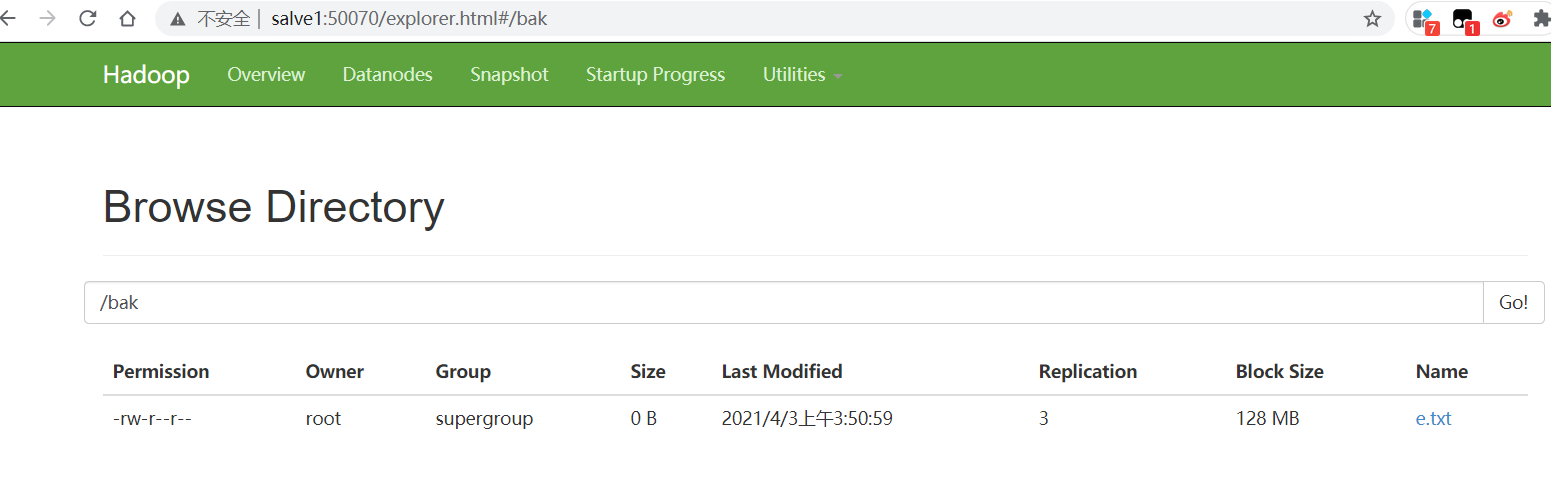
8.补充
- 三台节点都执行
#如果配置错误了 格式化错误了才执行这一步
#在启动datanode和namenode服务器上删除临时数据
[root@master ~]# rm -rf /home/hadata/tmp
#在启动namenode服务器上删除元数据
[root@master ~]# rm -rf /home/hadata/dfs/name
#在启动datanode服务器上删除块数据
[root@master ~]# rm -rf /home/hadata/dfs/data
#在启动journalnode服务器上删除恭喜日志数据
[root@master ~]# rm -rf /home/hadata/journal1
#进入zk客户端
[root@master ~]# zkCli.sh
# 删除NameNode协调数据,必须在zk启动后,进入客户端删除
[zk: localhost:2181(CONNECTED) 4] rm -r /hadoop-ha
#下面是重新配置Yarn的HA删除数据:
[zk: localhost:2181(CONNECTED) 4] rm -r /yarn-leader-election

















 4199
4199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











