







PyTorch
加载数据集&&Dataset类实战
from torch.utils.data import Dataset
torch工具区的dataset区引入抽象类Dataset
所有子类继承他 并需要重写_getitem_ _len_,
class MyData(Dataset):#继承
def __init__(self,root_dir,label_dir):#初始化
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):#重写 获取每个图片
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):#重写 图片数量
return len(self.img_path)
引入os的包
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
os.path.join合并目录
os.listdir读取目录 返回一个列表


from PIL import Image
读取图片的包&&展示图片


类实例化后的数据集可以合并
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)
train_dataset= ants_dataset + bees_dataset
print(len(train_dataset))
tensorboard使用
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")#实例化这个类 参数代表文件夹名字 文件夹里面是生成的事件
#简单例子 描绘y=5x
for i in range(100):
writer.add_scalar("y=5x",5*i,i)#参数: 题目 纵轴值 横轴值
writer.close()

图片可查看很多东西
**http://localhost:6006/**为默认tensorboard网址

后面加 --port=xxxx改端口号(保证与其他服务器不同)
import numpy as np
from PIL import Image
image_path = "datasets/train/ants_image/5650366_e22b7e1065.jpg"
image_path2="datasets/train/bees_image/16838648_415acd9e3f.jpg"
img = Image.open(image_path)
img2 = Image.open(image_path2)
img_array = np.array(img)
img_array2 = np.array(img2)
print(type(img_array))
print(img_array.shape)
writer = SummaryWriter("logs")
writer.add_image("bees",img_array2,1,dataformats='HWC')#add_image支持的图片类型有要求 dataformats保证图片格式与读取相同(高、宽、频道数)
writer.close()


使用同一标题 不同迭代次数的图片显示可滑动查看
常见transforms的使用
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
import cv2#opencv的包 可以直接以array的形式读取图片
ToTensor
##totensor
img_path = "datasets/train/bees_image/29494643_e3410f0d37.jpg"
img = Image.open(img_path)
tensor = transforms.ToTensor()
tensor_img = tensor(img)
print(tensor_img)
cv_img = cv2.imread(img_path)
print(type(cv_img))#opencv方式读入 转换同上

Normalize
#normalize
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(tensor_img)
writer = SummaryWriter("logs")
writer.add_image("tensor_img",tensor_img,1)
writer.add_image("norm_img",img_norm)

初始化带上平均值和标准差(以列表形式) 列表的长度取决于图片的频道数
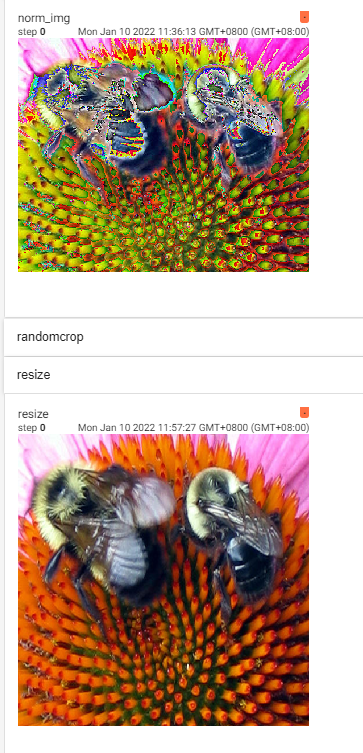
效果如上 会改变色调
Resize
#resize
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img)
img_resize = tensor(img_resize)
writer.add_image("resize",img_resize,0)
img_resize2 = trans_resize(tensor_img)
writer.add_image("resize2",img_resize2,0)

改变图片尺寸 输入可以是PIL类型或直接输入tensor类型
初始化时可以是一个元组(即图片大小) 若只输入int星 可理解为等比缩放

原图-》改变后的
Compose
#resize2 compose
trans_resize2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize2,tensor])
img_resize3 = trans_compose(img)
writer.add_image("compose_resize",img_resize3,1)

初始化以列表形式 列表里元素是transforms类型 (要按照执行顺序输入)
为等比例缩放后的图片 按顺序执行compose里的transform
RandomCrop
#randomcrop随即裁剪
trans_randomcrop = transforms.RandomCrop(50)
trans_compose2 = transforms.Compose([trans_randomcrop,tensor])
for i in range(10):
img_crop = trans_compose2(img)
writer.add_image("randomcrop",img_crop,i)
writer.close()

随机裁剪 初始化的参数可以指定裁剪大小 或 int类型默认裁剪大小为(int * int)

一部分 可以拖拽查看十个部分
其余方法 可查看官方文档 获取输入输出信息及格式 按住CTRL进入即可
torchvision中数据集使用
官网找torchvision.datasets

以CIFAR数据集为例
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]
)
train_set = torchvision.datasets.CIFAR10(root="./datasets_CIFAR10", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./datasets_CIFAR10", train=False, transform=dataset_transform, download=True)
参数:
- root设定数据集路径
- train 设置是否为训练集(反之则为测试集)
- tranform 采取的一系列transform操作
- download 是否下载
print(test_set[0])#返回图片和 tag
print(test_set.classes)#每一个测试集图片的标签集合
writer = SummaryWriter("datasets_transform")
for i in range(10):
img, tag = test_set[i]
writer.add_image("test_img_resize2", img, i)
writer.close()

dataloader使用

import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_set = torchvision.datasets.CIFAR10(root="./datasets_CIFAR10",train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_set, batch_size=4, shuffle=True, num_workers=0, drop_last=True)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, tags = data
writer.add_images("eopch:{}".format(epoch),imgs, step)
step=step+1
writer.close()
dataloader参数
- dataset 选择的数据集
- batch_size一批选择的数量
- shuffle 多次选择是否洗牌(打乱顺序)
- num_workers一般为0 表示线程工作数
- drop_last 最后一页数量不够时是否取余或全部删除

说明shuffle

drop_last对比
神经网络基本骨架nn.moudle

import torch
from torch import nn
class Ssy(nn.Module):
def __init__(self):
super(Ssy, self).__init__()
def forward(self, input):
output = input * 2 +1
return output
ssy = Ssy()
x = torch.tensor(341)
output = ssy(x)
print(output)
此处即把输入的tenso类型341 转换为341*2+1输出
即网络内部是(*2+1)的工作
卷积层
卷积层具体原理见机器学习


参数:
- 输入频道数:一般为3(RGB三通道)
- 输出频道数
- 内核大小
- 步长:一次走几步
- 填充:默认为0
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#下载数据集
test_set = torchvision.datasets.CIFAR10(root="./datasets_CIFAR10",train=False,transform=torchvision.transforms.ToTensor())
#调用dataloader
test_loader = DataLoader(dataset=test_set, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
writer = SummaryWriter("conv2d")
class Ssy(nn.Module):
def __init__(self):
super(Ssy, self).__init__()
#卷积操作 变为6通道 内核大小为3(具体矩阵会自动变化调整)
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):#神经网络中实现卷积层
x = self.conv1(x)
return x
ssy = Ssy()
step=0
for data in test_loader:
imgs, target = data
output = ssy(imgs)
print(imgs.shape)
print(output.shape)
writer.add_images("imgs",imgs,step)
#需要把卷积后的图像重新变为3通道 否则不能显示
output = torch.reshape(output,(-1,3,30,30))
writer.add_images("imgs_conv2d",output,step)
step=step+1
writer.close()

由于3通道变为6通道 一页显示了128个图片
池化层


[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p1JpfQHS-1649240049324)(https://cdn.jsdelivr.net/gh/girlsdontget341/image@master/img/202201172200524.png)]
参数:
-
内核大小
-
步长:默认为内核大小
-
填充
-
空洞大小 详见
-
ceilmode:选择是否舍弃
池化原理


即 内核类似卷积操作覆盖输入矩阵上元素 并选出最大的作为输出
与卷积不同的是 池化的步长默认为内核大小
当遇到如上情况 ceil_mode=True即不舍弃残缺的矩阵 从中选择最大的
ceil_mode=False 即舍弃矩阵 内核继续向下移动

import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
data = torchvision.datasets.CIFAR10("./datasets_CIFAR10", train=False, transform= torchvision.transforms.ToTensor() )
dataloader= DataLoader(data,batch_size=64 )
matrix_in = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype= torch.float)
input = torch.reshape(matrix_in, (-1,1,5,5))#注意输入的格式
#-1表示模糊 即函数自适应调整大小
writer = SummaryWriter("max_pool")
class Ssy(nn.Module):
def __init__(self):
super(Ssy, self).__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool(input)
return output
ssy = Ssy()
step = 0
for data in dataloader:
img, tag = data
writer.add_images("input", img, step)
output = ssy(img)
writer.add_images("output", output,step)
step = step+1
writer.close()


显而易见,池化后图片变模糊了,神经网络中常用池化层减少输入数据量,保留必要纹理信息,加快训练速度。
非线性激活
ReLU

inplace为true即输出直接替换输入
置为false生成一个新的变量输出

import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
input = torch.tensor([[1,-1],
[-25,100.2]],dtype=torch.float)
input= torch.reshape(input,(-1,1,2,2))
class Ssy(nn.Module):
def __init__(self):
super(Ssy, self).__init__()
self.relu1 = ReLU()
#self.sigmoid = Sigmoid()
def forward(self,input):
output = self.relu1(input)
return output
ssy = Ssy()
output = ssy(input)
print(output)

很明显结果与截断函数一致
Sigmoid


import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
data = torchvision.datasets.CIFAR10("./datasets_CIFAR10", train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(data, batch_size=64)
class Ssy(nn.Module):
def __init__(self):
super(Ssy, self).__init__()
self.relu1 = ReLU()
self.sigmoid = Sigmoid()
def forward(self,input):
output = self.sigmoid(input)
return output
ssy = Ssy()
writer = SummaryWriter("sigmoid")
step = 0
for data in dataloader:
imgs, tags = data
writer.add_images("imgs",imgs,step)
imgs_sigmoid = ssy(imgs)
writer.add_images(("imgs_sigmoid"), imgs_sigmoid,step)
step =step +1
writer.close()


目的是增加一些非线性特征便于训练
正则化层



(详见官方文档)
Recurrent Layer
多用于文字识别等
详见官方文档
线性层


目的是把5*5—>1*25—>1*10
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10(root="../dataset_/datasets_CIFAR10", train=False, transform= torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size= 64, drop_last=True)
class SSY(nn.Module):
def __init__(self):
super(SSY, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
ssy = SSY()
for data in dataloader:
imgs, tag = data
print(imgs.shape)
# imgs = torch.reshape(imgs, (1, 1, 1, -1))
imgs = torch.flatten(imgs)#flatten即展平 作用与上相同
print(imgs.shape)
output = ssy(imgs)
print(output.shape)

Sequential

有点类似于transforms中的Compose。。
实例

网络搭建根据图片顺序(卷积-池化-卷积-池化-卷积-池化-展平-线性层-线性层)
计算卷积层stride与padding大小
-
根据公式

-
经验
为了保持卷积后大小不会发生变化
一般来说,在stride为1的情况下,padding等于奇数内核大小 一半的向下取整即(x-1)/2
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.tensorboard import SummaryWriter
#网络中注释和非注释内容执行效果一致
class SSY(nn.Module):
def __init__(self):
super(SSY, self).__init__()
# self.conv1 = Conv2d(3,32,5,padding=2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32,32,5,padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32,64,5,padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024,64)
# self.linear2 = Linear(64,10)
self.model1 = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model1(x)
return x
ssy = SSY()
print(ssy)
#一般为了检查网络构建参数是否正确
input = torch.ones((64, 3, 32, 32))
output = ssy(input)
print(output.shape)
writer = SummaryWriter("../tensorboard_dirs/logs_seq")
writer.add_graph(ssy, input)
writer.close()



使用tensorboard可以查看网络搭建具体情况,路线上会显示传输数据的大小
Loss Function


import torch
from torch import nn
input = torch.tensor([1,3,5], dtype=torch.float32)
targets = torch.tensor([2,4.5,9], dtype = torch.float32)
# input = torch.reshape(input,(1,1,1,3))
# targets = torch.reshape(targets,(1,1,1,3))
loss = nn.L1Loss()
result = loss(input, targets)
loss_mse = nn.MSELoss()
resu_mse = loss_mse(input, targets)
print(result)##6.5/3
print(resu_mse)#19.25/3
交叉熵

input = torch.tensor([1,3,5], dtype=torch.float32)
loss_cro = nn.CrossEntropyLoss()
print(input.shape)
input2 = torch.reshape(input,(1,3))##直接使用input会报错,input的shape为[3]需要转变为[1,3]
print(input2.shape)
y = torch.tensor([1])
res_cro = loss_cro(input2, y)
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../dataset_/datasets_CIFAR10",train=False,transform=torchvision.transforms.ToTensor(),download=False)
dataloader = DataLoader(dataset,batch_size=1)
class SSY(nn.Module):
def __init__(self):
super(SSY, self).__init__()
self.model1 = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
ssy = SSY()
loss_ = nn.CrossEntropyLoss()
for data in dataloader:
imgs, tag = data
output = ssy(imgs)
res = loss_(output,tag)
# print(res)
res.backward()#利用反向传播确定梯度权重 如下图


优化器

ssy = SSY()
loss_ = nn.CrossEntropyLoss()
optim = torch.optim.SGD(ssy.parameters(), lr=0.01)
for epoch in range(5):
running_loss = 0.00
for data in dataloader:
imgs, tag = data
output = ssy(imgs)
res = loss_(output,tag)
# print(res)
optim.zero_grad()#梯度置0
res.backward()#反向传播确定梯度参数
optim.step()#更新参数(优化)
running_loss += res
print(running_loss)















 6955
6955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









