






-
安装requests库和BeautifulSoup库:
在pycharm的file下拉列表中选择setting进行安装:
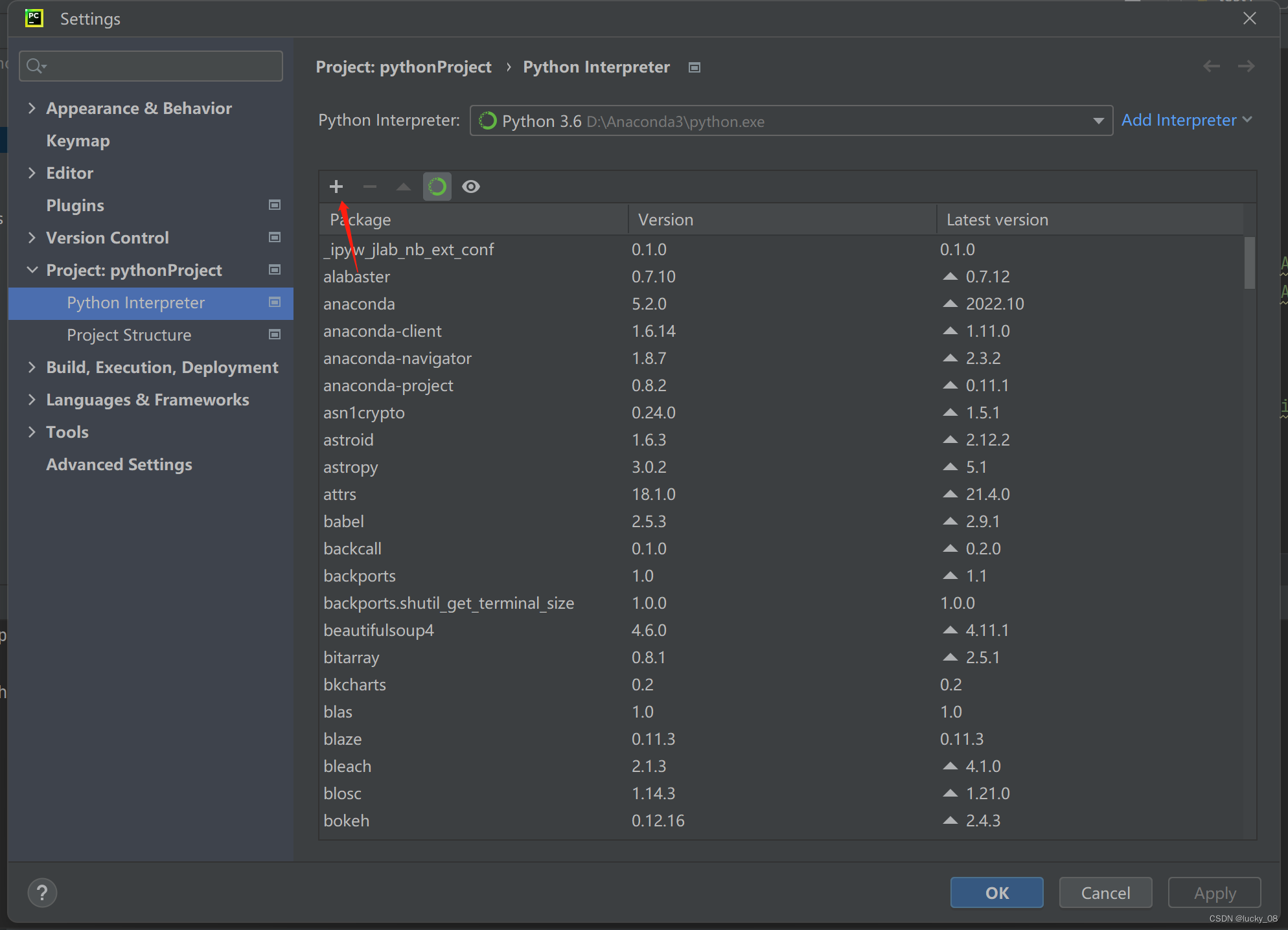
-
获取爬虫所需的header和cookie:
以爬取百度热搜文本为例,右键网页选择检查,选择网络,crtl+r刷新,选择第一个文件右键复制cURL

粘贴到下面的网站 Convert curl commands to code (curlconverter.com) 里得到header和cookie,直接复制
-
使用request请求获得网页地址
点击左上角的小图标,选择要爬取的信息,在对应源码处右键复制selector,多复制几个再观察规律,推断目标爬取信息的代码,示例如下:

#sanRoot > main > div.container.right-container_2EFJr > div > div:nth-child(2) > div:nth-child(1) > div.content_1YWBm > a > div.c-single-text-ellipsis
#sanRoot > main > div.container.right-container_2EFJr > div > div:nth-child(2) > div:nth-child(5) > div.content_1YWBm > a > div.c-single-text-ellipsis
#sanRoot > main > div.container.right-container_2EFJr > div > div > div > div.content_1YWBm > div.hot-desc_1m_jR.small_Uvkd3.ellipsis_DupbZ 上面两处代码只有child()不同,故推断出目标爬取数据代码
整体爬取代码如下:
import os
import requests
from bs4 import BeautifulSoup
cookies = {
'BIDUPSID': '6D4ECAE5184B0FD2223CE4EB639ED21B',
'PSTM': '1666252145',
'BAIDUID': '6D4ECAE5184B0FD23D9110EF1AE2968E:FG=1',
'BDUSS': 'nk0UU9DdjVYc1NDOHNKbzVCRXczTzFXUFhzSTVxTHY3VW94bUFVeTlRd3RTSXhqRVFBQUFBJCQAAAAAAAAAAAEAAAAP-3GQNDY2MTO~qAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAC27ZGMtu2RjQ',
'BDUSS_BFESS': 'nk0UU9DdjVYc1NDOHNKbzVCRXczTzFXUFhzSTVxTHY3VW94bUFVeTlRd3RTSXhqRVFBQUFBJCQAAAAAAAAAAAEAAAAP-3GQNDY2MTO~qAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAC27ZGMtu2RjQ',
'ZFY': 'KGFcQdUfzjPydX91k2qm4YZ2uQBTrxGR73uVGPwhhVI:C',
'BAIDUID_BFESS': '6D4ECAE5184B0FD23D9110EF1AE2968E:FG=1',
'__bid_n': '1844ba6a32c3f032914207',
'RT': '"z=1&dm=baidu.com&si=vo6qc7obakq&ss=labvgtd8&sl=e&tt=7l4&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=ndj4&ul=1kt98&hd=1ktet"',
'BDORZ': 'B490B5EBF6F3CD402E515D22BCDA1598',
'BDRCVFR[-BxzrOzUsTb]': 'mk3SLVN4HKm',
'H_PS_PSSID': '26350',
'BA_HECTOR': '0la52la10l0lala001018fjq1hn6c741f',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# Requests sorts cookies= alphabetically
# 'Cookie': 'BIDUPSID=6D4ECAE5184B0FD2223CE4EB639ED21B; PSTM=1666252145; BAIDUID=6D4ECAE5184B0FD23D9110EF1AE2968E:FG=1; BDUSS=nk0UU9DdjVYc1NDOHNKbzVCRXczTzFXUFhzSTVxTHY3VW94bUFVeTlRd3RTSXhqRVFBQUFBJCQAAAAAAAAAAAEAAAAP-3GQNDY2MTO~qAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAC27ZGMtu2RjQ; BDUSS_BFESS=nk0UU9DdjVYc1NDOHNKbzVCRXczTzFXUFhzSTVxTHY3VW94bUFVeTlRd3RTSXhqRVFBQUFBJCQAAAAAAAAAAAEAAAAP-3GQNDY2MTO~qAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAC27ZGMtu2RjQ; ZFY=KGFcQdUfzjPydX91k2qm4YZ2uQBTrxGR73uVGPwhhVI:C; BAIDUID_BFESS=6D4ECAE5184B0FD23D9110EF1AE2968E:FG=1; __bid_n=1844ba6a32c3f032914207; RT="z=1&dm=baidu.com&si=vo6qc7obakq&ss=labvgtd8&sl=e&tt=7l4&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=ndj4&ul=1kt98&hd=1ktet"; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDRCVFR[-BxzrOzUsTb]=mk3SLVN4HKm; H_PS_PSSID=26350; BA_HECTOR=0la52la10l0lala001018fjq1hn6c741f',
'Referer': 'https://top.baidu.com/board?platform=pc&sa=pcindex_entry',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.42',
'sec-ch-ua': '"Microsoft Edge";v="107", "Chromium";v="107", "Not=A?Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
params = {
'tab': 'realtime',
}
#数据存储
fo = open("./热搜1.txt",'a',encoding="utf-8")
#获取网页
response = requests.get('https://top.baidu.com/board', params=params, cookies=cookies, headers=headers)
#解析网页
response.encoding='utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
#爬取内容
content="#sanRoot > main > div.container.right-container_2EFJr > div > div > div > div.content_1YWBm > div.hot-desc_1m_jR.small_Uvkd3.ellipsis_DupbZ"
#清洗数据
a=soup.select(content)
'''BeautifulSoup.select可以找出含有CSS属性的元素,输出形式为list
使用select找出所有id为title的元素(id前面需加#)
使用select找出所有class为link的元素(class前面需加.)
使用select找出所有a tag的href连接'''
for i in range(0,len(a)):
a[i] = a[i].text#提取列表的文本
fo.write(a[i]+'\n')
fo.close()















 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









