







目录
1.导入
没有下载lxml库的可以先 pip install lxml 下载一下
如果出现错误,先检查pip的版本是否需要更新
再不行则尝试换源
from lxml import etree2.etree解析数据的两种情况
1.解析本地文件
tree= etree.parse('XX.html')
当把获取的网页源码保存到本地,以.html为后缀,这个时候就需要使用parse来解析本地的html文件
把爬取下来的网页源码保存到本地的好处是:从源码中获取想要的数据时,频繁的修改解析数据的代码而不用频繁的向网站发出请求,避免出现ip被封等情况。
2.解析服务器响应文件
这个就是获取到网页的源码,直接丢给etree.HTML()解析,不用将源码保存到本地
tree = etree.HTML(获取的网页源码)
3.常用符号及其含义
| 符号 | 描述 |
| / | 从根节点选取 |
| // | 不考虑层级关系,查找所有子、孙节点, |
| @ | 选取属性 |
| . | 当前节点 |
| .. | 当前节点的父节点 |
| * | 任意节点元素 |
4.xpath基本语法
1.查找标签
1.------查找标签------
//div[@id="d"] 查找id属性等于d的div标签
//div[@class="price"] 查找class属性为price的div标签
//ul[@class="list"]/li/a 查找class属性为list的ul标签,ul下的li标签内的a标签
2.获取标签内的文本值
2.------若要获取标签内的文本值,则需要输入text()------
//div[@class="nav"]/span/text() 获取span标签的内容
//div[@class="price"]/text() 获取div标签的内容
3.获取标签的属性
3.------查询属性------
找到对应的标签后,后边跟 @要查询的属性
//div/a/@href 获取a标签的href属性
//ul[@class="list"]/div/@class 获取div标签的class属性4. 多个节点的选取用 “|” (选取若干路径)
在选取多个节点时用 | 隔开
选取id属性为nav的div标签和class属性为left的div标签
//div[@id="nav"] | //div[@class="left"]感觉经常使用的就是前三条
5.案例练习
<div id="123">
<ul class="list">
<li class="item-0"> <a href="https://www.baidu.com">百度</a> </li>
<li class="item-1"> <a href="https://www.jd.com/">京东</a> </li>
<li class="item-2"> <a href="link3.html">第三</a> </li>
<li class="item-3"> <a href="link4.html">第四</a> </li>
<li class="item-4"> <a href="link5.html">第五</a> </li>
</ul>
</div>
<div class="nav">我是一个导航条</div>
<div class="text">
<span>快来获取我的内容啊!</span>
<h1>你不要过来啊!</h1>
</div>1.获取class属性为list的ul列表中的第一个li标签
//ul[@class="list"]/li[1]
2.获取class属性为text的div标签内的span标签的内容
//div[@class="text"]/span/text() #快来获取我的内容啊!
3.获取class属性为text的div标签内的所有内容
//div[@class="text"]//text() #快来获取我的内容啊! 你不要过来啊!
//可以忽略层级,查找某标签的子、孙节点
4..获取class属性为nav的div标签的内容
//div[@class="nav"]/text() #我是一个导航条
3..获取ul列表中的第一个li标签内的a标签的href属性
//ul/li[1]/a/@href #https://www.baidu.com
在上方的html代码中只有一个ul标签,所以在这不指定ul的class属性也可以找到这个ul标签
4.获取class属性为nav和class属性为text的两个div标签
//div[@class="nav"] | //div[@class="text"]6.插件推荐
1.Chrome插件 XPath Helper
安装这个插件后,在网页的界面按下ctrl+shift+x 唤醒插件,左侧输入xpath语法,右侧根据你输入的语法显示结果
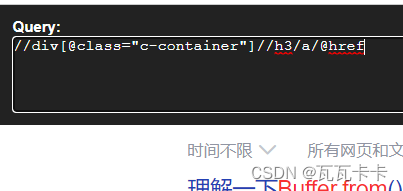
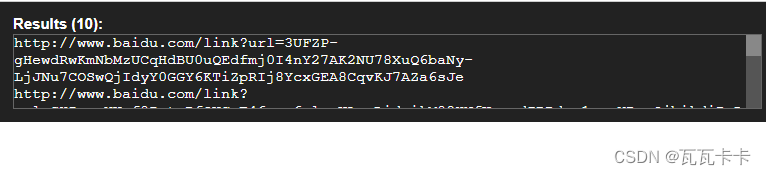
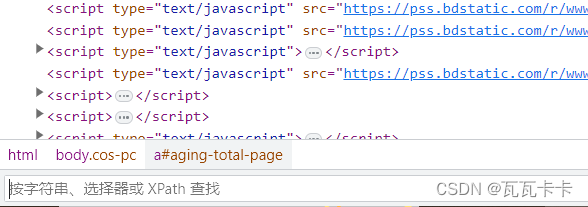
2.Chrome浏览器自带的检测xpath语法的搜索框
在Chrome浏览器中,右键点击检查或按下F12,在显示html代码的页面中按下ctrl+F进行搜索,在搜索框内也可以输入xpath语法进行定位















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









