







图像增强
- 图像增强领域的发展和研究
- 论文阅读与总结
-
- ==标题==:
- ==标题==:Division gets better: Learning brightness-aware and detail-sensitive representations for low-light image enhancement
- ==标题==:A Dynamic Histogram Equalization for Image Contrast Enhancement(2007 IEEE)
- ==标题==:INSPIRATION: A reinforcement learning-based human visual perception-driven image enhancement paradigm for underwater scenes
- ==标题==:Revisiting coarse-to-fine strategy for low-light image enhancement with deep decomposition guided training
- ==标题==:Retinexmamba: Retinex-based Mamba for Low-light Image Enhancement
- ==标题==:Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancemen
- ==标题==:DICAM: Deep Inception and Channel-wise Attention Modules for underwater image enhancement
- ==标题==:Degraded Structure and Hue Guided Auxiliary Learning for low-light image enhancemen
- ==标题==:Deep Retinex Decomposition for Low-Light Enhancement
- ==标题==:Diff-Retinex: Rethinking Low-light Image Enhancement with A Generative Diffusion Model
- ==标题==:Implicit Neural Representation for Cooperative Low-light Image Enhancement
- ==标题==:Empowering Low-Light Image Enhancer through Customized Learnable Priors(2023 优)
- ==标题==:ExposureDiffusion: Learning to Expose for Low-light Image Enhancement(2023 ICCV)
- ==标题==:Equipping Diffusion Models with Differentiable Spatial Entropy for Low-Light Image Enhancement
- ==标题==:Low-Light Image Enhancement with Wavelet-based Diffusion Models
- ==标题==:Semantic-aware enhancement: Integrating semantic compensation with 3-Dimensional Lookup Tables for low-light image enhancement
- ==标题==:基于跨域特征融合的低光图像增强算法
- ==标题==:You Only Need One Color Space: An Efficient Network for Low-light Image Enhancement
- 常用的数据集
- 图像增强领域相关知识的总结
- 阅读感悟
图像增强领域的发展和研究
标题:基于生成模型的低光照图像增强算法综述(来自知网)
基于自编码器的方法
基于生成对抗网络的方法(GAN)
基于扩散模型的方法(DDPM)
本文总结
本文主要介绍了这三种生成模型在图像增强方面的方法,通过这篇文章获得的创新点就是可不可以将扩散模型用于图像的增强。
标题:Advancements in Low Light Image Enhancement Techniques and Recent Applications
摘要
 这张图展示了低光照图像增强的不同技术方法,包括灰度变换、直方图均衡、去雾模型、Retinex方法、图像融合、小波变换和机器学习方法。每种主要方法又被细分为不同的子类。
这张图展示了低光照图像增强的不同技术方法,包括灰度变换、直方图均衡、去雾模型、Retinex方法、图像融合、小波变换和机器学习方法。每种主要方法又被细分为不同的子类。
-
灰度变换(Gray Transformation):
- 线性变换(Linear Transformation)
- 非线性变换(Non Linear Transformation)
-
直方图均衡(Histogram Equalization)
-
去雾模型(Defogging Models)
-
Retinex方法(Retinex Methods):
- 单尺度Retinex(Single Scale Retinex)
- 多尺度Retinex(Multi Scale Retinex)
-
图像融合(Image Fusion)
-
小波变换(Wavelet Transform)
-
机器学习方法(Machine Learning Methods)
这些技术各自针对不同的低光照图像增强需求,提供了多种手段来改善图像质量。通过这些方法,可以在不同场景下有效地提升图像的对比度、亮度和细节,进而提高图像的可用性和视觉效果。
灰度变换技术
数字图像由称为像素的二维数组组成。每个像素对应于图像中的一个位置,由其(x, y)坐标定义。根据强度级别,每个像素值的范围从0到255,分别表示其暗度或亮度。仅具有像素强度作为图像细节的图像是灰度图像。颜色空间、图像大小、内存空间、分辨率等是其他关键图像细节。众所周知,任何观察到的颜色都是由红、绿、蓝三种主要颜色成分组合而成的。因此,彩色图像有三个不同的强度层,分别表示红色、绿色和蓝色的强度。这三种颜色的组合比例决定了该像素的真实颜色。通常,低光照图像的像素值比对应的真实图像要小。灰度变换方法通过基于映射的方法将每个像素的低灰度值转换为较高的灰度值。该方法通过修改灰度值和分布的动态范围来增强图像。该方法有两种子类:线性灰度变换和非线性灰度变换。
总结:
-
像素和图像组成:
- 数字图像由像素组成,每个像素都有一个(x, y)坐标。
- 像素值根据其暗度或亮度范围在0到255之间。
-
灰度图像和彩色图像:
- 灰度图像仅使用像素强度表示图像细节。
- 彩色图像由红、绿、蓝三个颜色强度层组成,每个颜色层都有其强度值。
-
低光照图像:
- 低光照图像的像素值通常较低。
- 灰度变换方法通过映射将低灰度值转换为较高灰度值,以增强图像质量。
-
灰度变换方法:
- 该方法通过修改灰度值的动态范围和分布来增强图像。
- 包括两种子类:线性灰度变换和非线性灰度变换。
这段内容详细解释了数字图像的基本组成、灰度图像和彩色图像的区别、低光照图像的特点以及灰度变换方法如何通过调整灰度值来增强图像质量。
线性灰度变换
在这种方法中,灰度值被线性变换,因此称为线性拉伸,其公式为:
[ 𝑔(𝑎,𝑏) = 𝐶 \cdot 𝑓(𝑎,𝑏) + 𝑅 ]
其中,( f(a,b) ) 和 ( g(a,b) ) 分别表示输入图像和输出图像,C 和 R 是线性变换系数。在线性变换过程中使用了两种类型的线性变换曲线:连续曲线和分段曲线。这种方法执行时间较短,但会导致输出细节较少和图像增强不均匀。
总结:
-
线性变换方法:
- 该方法使用线性拉伸公式将灰度值转换:
𝑔(𝑎,𝑏) = 𝐶 𝑓(𝑎,𝑏) + 𝑅 - 公式中, f(a,b) 是输入图像,g(a,b) 是输出图像,C 和 R 是线性变换系数。
- 该方法使用线性拉伸公式将灰度值转换:
-
线性变换曲线:
- 使用两种类型的线性变换曲线:连续曲线和分段曲线。
-
方法优缺点:
- 优点:执行时间较短,效率较高。
- 缺点:输出细节较少,图像增强不均匀。
这段内容解释了线性变换方法的基本原理、公式及其优缺点,特别强调了该方法在执行效率和图像质量上的平衡问题。
非线性灰度变换—对数函数
非线性灰度变换方法通过非线性函数转换灰度值。两种常用的非线性函数是伽马函数和对数函数。对数函数使用对数关系来转换输入像素。公式如下:
[ g(a,b) = \log(1 + c \times f(a,b)) ]
其中,( f(a,b) ) 是输入图像,( g(a,b) ) 是输出图像,( c ) 是控制变量。图2(a)显示了上述方程对应的对数变换函数,其中 ( c=1 ) 和 ( c=10 )。如图所示,对数函数拉伸了像素的低灰度值,同时压缩了像素的高灰度值。
总结
- 非线性灰度变换:通过非线性函数(如伽马函数和对数函数)转换灰度值。
- 对数函数:使用对数关系转换输入像素,公式为 [ g(a,b) = \log(1 + c \times f(a,b)) ]。
- 函数解释:
- ( f(a,b) ) 是输入图像的灰度值。
- ( g(a,b) ) 是输出图像的灰度值。
- ( c ) 是控制变量。
- 效果:对数函数拉伸低灰度值像素,同时压缩高灰度值像素,使得低光照部分细节增强,而高光部分压缩,避免过曝。

非线性灰度变换—伽马函数
伽马也是一种非线性函数,其公式如下:
[ g(a,b) = f(a,b)^\gamma ]
其中,(\gamma) 是一个常数,称为“伽马校正因子”。图像的属性会随 (\gamma) 值的变化而变化,如表1所示。图2(b)显示了 (\gamma = 0.3, 1, 3) 时的伽马变换函数。从图3(a)到图3(h)分别展示了不同 (\gamma) 值(从0.2到0.8)以及原始低光照图像((\gamma = 1))。通过比较图3(a)((\gamma = 0.2))和图3(h)((\gamma = 1)),可以注意到高灰度值的拉伸和低灰度值的压缩效果。
总结
6. 伽马变换:是一种非线性函数,用于调整图像的灰度值。
7. 公式:[ g(a,b) = f(a,b)^\gamma ],其中 (\gamma) 是伽马校正因子。
8. 属性变化:图像的属性会随 (\gamma) 值的变化而改变。
9. 图示:
- 图2(b)显示了不同 (\gamma) 值(0.3, 1, 3)的伽马变换函数。
- 图3(a)到图3(h)展示了从0.2到0.8的不同 (\gamma) 值图像,以及原始低光照图像((\gamma = 1))。
- 效果:(\gamma) 值较小时(如0.2),会拉伸高灰度值像素,而压缩低灰度值像素;(\gamma) 值为1时,不进行校正。
这些变换方法有助于增强图像的细节和对比度,使得在不同光照条件下的图像能够更清晰地展示重要信息。


模型
总结
模型
总结
模型
总结
模型
总结
模型
总结
模型
总结
模型
总结
论文阅读与总结
标题:
摘要
创新
模型
总结
标题:Division gets better: Learning brightness-aware and detail-sensitive representations for low-light image enhancement
摘要
弱光图像增强致力于提高对比度,调整可见度,并恢复颜色和纹理的失真。现有的方法通常更注重通过增加低照度图像的亮度来提高图像的可见度和对比度,而忽略了高质量图像的色彩和纹理恢复的重要性。针对上述问题,本文提出了一种用于微光图像增强的亮度和色度双分支网络LCDBNet,该网络将微光图像增强分为亮度调整和色度恢复两个子任务。具体来说,LCDBNet由两个分支组成,即亮度调整网络(LAN)和亮度恢复网络(CRN)。在局域网中,我们设计了一个全局和局部聚合块(GLAB)来提取亮度感知特征,该聚合块由一个变压器分支和一个双注意分支组成,用于模拟远程依赖和局部注意关联。在CRN中,我们引入小波变换来获取高频细节信息。最后,设计了一个融合网络,将学习到的特征融合在一起,产生令人印象深刻的视觉图像。在七个基准数据集上进行的大量实验验证了我们提出的LCDBNet的有效性,结果表明LCDBNet在多个参考/非参考质量评估器方面与其他最先进的竞争对手相比具有优越的性能。我们的代码和预训练模型可在https://github.com/WHK-Huake/LCDBNet上获得。
本文创新
分析了亮度空间和色度空间在微光图像增强中的优势。为此,我们提出了一种新的双支路低光图像增强方法,将难以处理的图像增强问题转化为两个易于处理的子任务:亮度调整和色度恢复。设计了一种亮度和色度双分支网络(LCDBNet),该网络由亮度调节网络(LAN)和色度恢复网络(CRN)两个子网络组成。利用局域网络从亮度通道中获取亮度感知特征,利用CRN从亮度通道中提取细节敏感特征。
本文架构

 阅读总结
阅读总结
从这篇文章中学习到,可以将图像处理的问题分级为连个子问题,使用多分支网络来解决子问题,最后再将解决的问题融合在一起,可以称之为分而治之的方法。(两个子问题为,亮度调整,色度恢复)
标题:A Dynamic Histogram Equalization for Image Contrast Enhancement(2007 IEEE)
摘要
本文提出了一种基于传统直方图均衡(HE)算法的智能对比度增强技术。这种动态直方图均衡化(DHE)技术控制了传统直方图均衡化的效果,从而在增强图像效果的同时不会丢失任何细节。DHE 根据局部最小值对图像直方图进行分区,并为每个分区分配特定的灰度级范围,然后再分别对它们进行均衡。这些分区还要经过重新分区测试,以确保不存在任何占主导地位的部分。这种方法能很好地增强对比度,而不会带来严重的副作用,如冲淡外观、棋盘格效果等,也不会产生不良的人工痕迹,因此优于其他现有方法。
本文创新
本文中提出了一种动态直方图均衡技术。与直方图均衡不同的是,直方图中较高的成分会支配较低的部分,而本文提出的动态直方图均衡(DHE)则对输入直方图进行分割操作,将其切成一些子直方图,使其没有支配成分。然后,每个子直方图都要经过均衡化处理,并在增强后的输出图像中占据指定的灰度级范围。因此,通过 DHE,灰度级的动态范围得到了控制,整体对比度得到了更好的增强,同时消除了低直方图成分被压缩的可能性,因为低直方图成分可能会导致图像的某些部分出现冲淡的外观。此外,DHE 还能确保保存图像细节的一致性,并且不会产生任何严重的副作用。
本文方法细节
在所提出的方法中,我们的主要观察点是消除图像直方图中较高直方图成分对较低直方图成分的支配,并控制灰度级的拉伸量,以合理增强图像特征。尽管一次使用变换函数处理整个直方图,但 DHE 仍会将其划分为多个子直方图,直到确保新创建的子直方图中不存在任何支配部分。然后,为每个子结构图分配一个动态灰度级 (GL) 范围,HE 可将其灰度级映射到该范围内。具体做法是,根据输入图像中灰度级的动态范围和直方图值的累积分布 (CDF),在各子直方图之间分配总的可用灰度级动态范围。这种对比度伸展范围的分配可防止输入图像中的细小特征被遮挡和冲淡,并确保整个图像的每个部分都能得到适度的对比度增强。最后,根据传统的 HE 方法,为每个子直方图计算单独的变换函数,并将输入图像的灰度级相应地映射到输出图像上。
整个技术可以分为三个部分——分区直方图、为每个子直方图分配 GL 范围以及对每个子直方图应用 HE。
A. 直方图划分
DHE 根据局部最小值对直方图进行分割。首先,它在直方图上应用大小为 1 x 3 的一维平滑滤波器,以去除不重要的极小值。然后,它将直方图中位于两个局部极小值之间的部分进行分区(子直方图)(第一个和最后一个非零直方图分量被视为极小值)。在数学上,如果 m0、m1、…、mn 是 (n+1) 个灰度级 (GL),对应于图像直方图中的 (n+1) 个局部极小值,那么第一个子直方图将选取 GL 范围 [m0, m1] 的直方图分量,第二个子直方图将选取 [m1+1, m2],以此类推。这些直方图分区有助于防止直方图的某些部分被其他部分占据。图 4(a) 展示了这种分区方法的一个示例
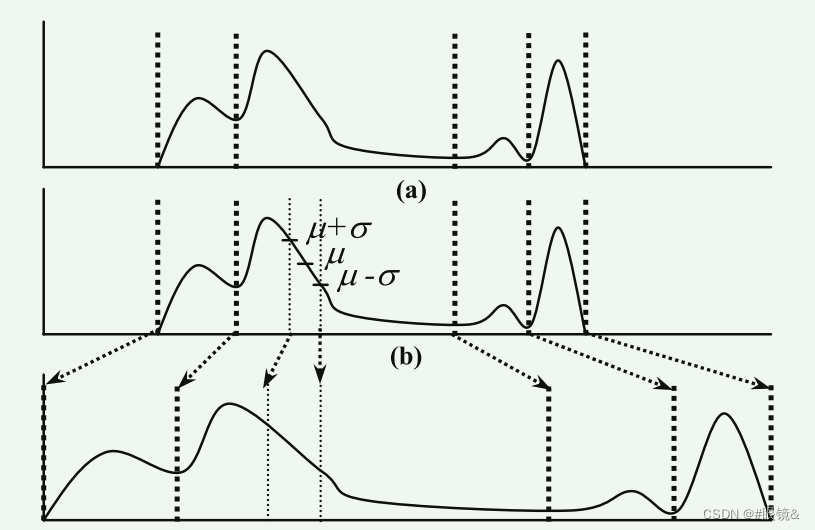
然而,仅靠这种划分方法并不能保证避免某些直方图成分的支配。为了检验是否存在支配部分,我们首先要找出每个子组图区的 GL 频率(直方图成分)的平均值 μ 和标准偏差 σ。如果在一个子柱状图中,频率在 (μ -σ) 到 (μ+σ) 范围内的连续灰度级的数量超过了该子柱状图所有灰度级总频率的 68.3%,那么我们就可以认为该子柱状图的频率呈正态分布[18],没有可能影响其他柱状图的主导部分。但另一方面,如果该百分比小于 68.3%,我们可能会担心子直方图中存在某些支配部分。在这种情况下,DHE 会通过在灰度级(μ-σ)和(μ +σ)对子组图进行分割,将其分成三个较小的子组图。图 4(b) 展示了这样一个实例。然后,第一和第三个子组图会进行相同的支配检验,必要时会重新分割。中间的分区保证无支配性。这种直方图拆分操作使直方图的低频部分在 HE 对其执行时不会有支配风险。
B. 灰度分配
将图像直方图分割成一些子直方图,使其中没有任何一个子直方图具有支配性部分,并不能保证获得很好的增强效果,从而避免支配性部分。这是因为一些具有较高值的子直方图可能会拉伸过多,使其他具有较低直方图值的子直方图获得显著对比度增强的空间变小,这是 GHE 中的一个常见现象
对于每个子直方图,DHE 都会在输出图像直方图中分配一个特定的灰度级跨度范围。这主要是根据输入图像直方图中子组图所占灰度级跨度的比率来决定的。这里的直接方法是
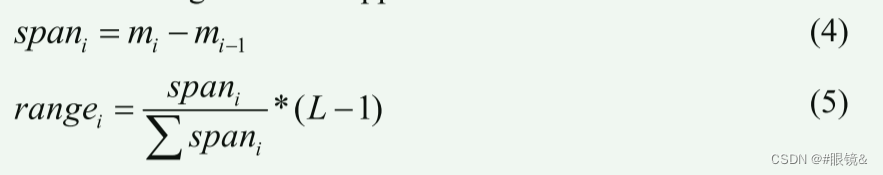 rangei = 输出图像中子直方图 i 的动态灰度范围。(你可以不明白这个式子是什么意思但是你知道如何计算就行)
rangei = 输出图像中子直方图 i 的动态灰度范围。(你可以不明白这个式子是什么意思但是你知道如何计算就行)
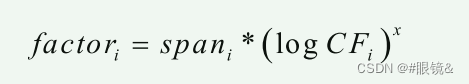
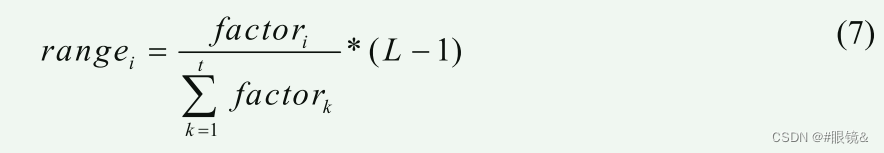 C. 直方图均衡
C. 直方图均衡
传统的 HE 适用于每个子直方图,但允许其在输出图像直方图中的跨度限制在指定的 GL 范围内。因此,输入图像直方图的任何部分都不允许在 HE 中占主导地位。
我的阅读理解
关于这篇文章提到的方法就是,将直方图进行分割,直至任何一个子直方图都不存在主导成分,那么分割结束,然后为分割后的直方图限制器可以处理的像素的范围,之后进行直方图均衡化,当这个图像中的像素处于那个映射对应的范围是就使用那个函数去处理,而不是使用单一的函数去处整个图片。
代码
标题:INSPIRATION: A reinforcement learning-based human visual perception-driven image enhancement paradigm for underwater scenes
本文提出的观点
(a) 应避免不加区分地使用单一方法来增强从各种水下场景中获取的水下图像,有必要有策略地选择一系列图像增强方法。这些方法应相辅相成,协同工作,以有效处理各种水下退化场景。
(b) 防止增强不足或过度,图像增强过程需要合理的指导。这种指导可以有效地增强水下图像,使其符合人类的审美偏好。
© 针对深度模型需要成对训练数据的局限性,有必要建立一个可行且可持续的增强基线,不依赖非水图像作为参考图像。
本文创新
(a) 为了避免不加区别地使用单一方法来增强从各种水下场景获得的水下图像,将水下图像增强建模任务表述为马尔可夫决策过程(MDP),并提出了基于强化学习的范式。如图所示,该范式有策略地选择图像增强算法并将其组织为一个最佳序列,旨在明确实现逐步增强的图像增强过程,并获得最佳增强性能。
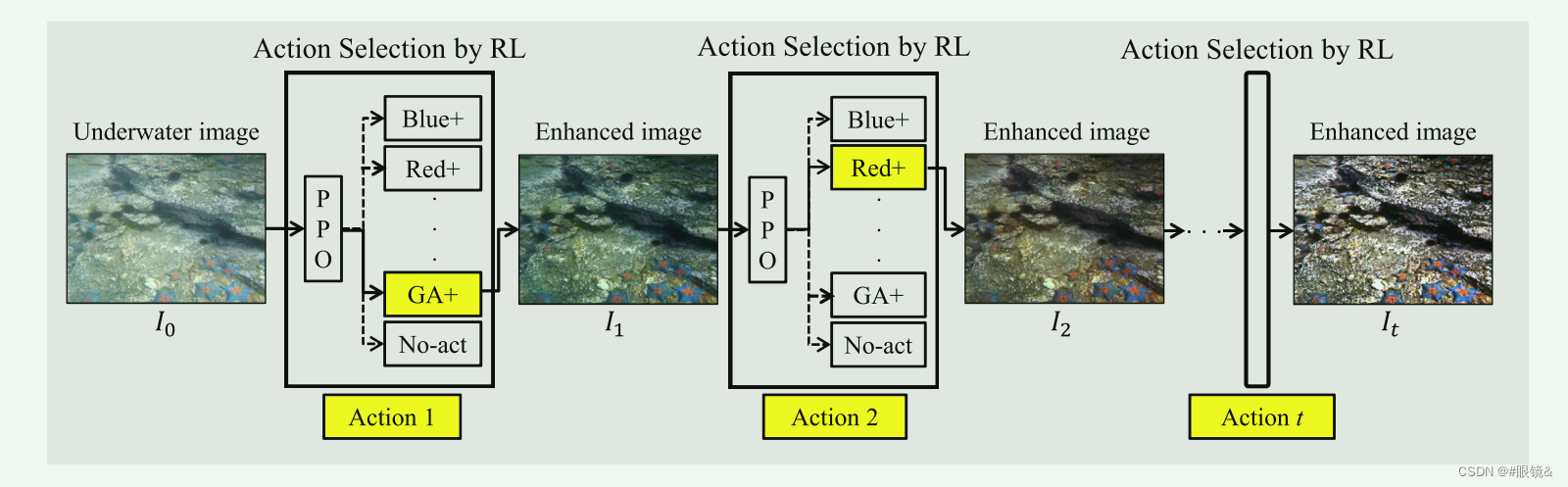 (b) 为了防止增强不足或过度,我们采用了三种非参考水下图像质量度量(水下图像质量度量(UIQM)(Panetta 等人,2016 年)、水下彩色图像质量评估度量(UCIQE)(Yang 和 Sowmya,2015 年)以及最小颜色损失(MCL)(Zhang 等人,2022 年c))来为基于强化学习的范式构建奖励。这些措施的设计灵感来自人类的视觉感知,能有效指导水下图像增强,使其与人类的视觉感知相一致。
(b) 为了防止增强不足或过度,我们采用了三种非参考水下图像质量度量(水下图像质量度量(UIQM)(Panetta 等人,2016 年)、水下彩色图像质量评估度量(UCIQE)(Yang 和 Sowmya,2015 年)以及最小颜色损失(MCL)(Zhang 等人,2022 年c))来为基于强化学习的范式构建奖励。这些措施的设计灵感来自人类的视觉感知,能有效指导水下图像增强,使其与人类的视觉感知相一致。
© 为了解决深度模型需要成对训练数据的局限性,我们开发了一种仅使用水下图像作为输入的范式实施方案。具体来说,利用残差增强网络提取特征作为状态,利用图像增强算法作为动作,利用多非参考人类视觉感知指标的增量作为奖励,利用近端策略优化(PPO)(Schulman 等人,2017 年)作为强化学习模型。为了确保我们的范式具有可重复性和可复制性,可以通过替换特征提取器、图像增强算法、图像质量度量和强化学习模型来修改所提供的代码,从而验证我们范式的有效性。
用于形成状态的模型
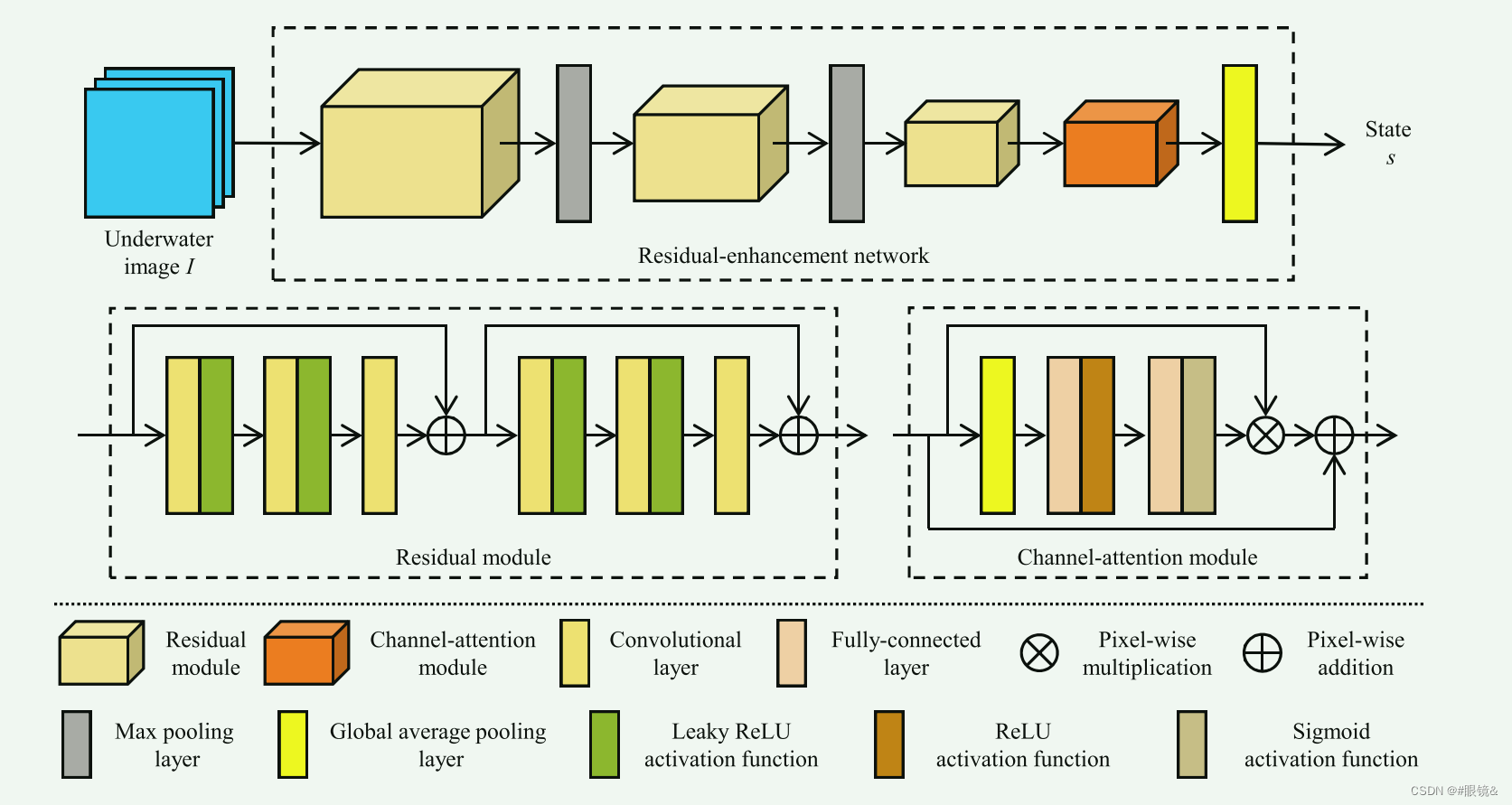 状态𝑠 表示水下图像𝐼的特征。如图 2 所示,残差增强网络包括残差模块和通道注意模块,用于提取特征。残差模块旨在保持数据的保真度并防止梯度消失(He 等人,2016 年),在水下图像增强中已被证明是有效的(Li 等人,2021 年)。它由两个残差块组成,除最后一层外,每个残差块包含三个具有 Leaky ReLU 激活函数的卷积层。在每个残差块之后,使用像素加法作为标识连接。每个残差模块中的卷积层具有相同数量的滤波器。使用了三个残差模块,在前两个残差模块之后使用最大池化层进行降采样。
状态𝑠 表示水下图像𝐼的特征。如图 2 所示,残差增强网络包括残差模块和通道注意模块,用于提取特征。残差模块旨在保持数据的保真度并防止梯度消失(He 等人,2016 年),在水下图像增强中已被证明是有效的(Li 等人,2021 年)。它由两个残差块组成,除最后一层外,每个残差块包含三个具有 Leaky ReLU 激活函数的卷积层。在每个残差块之后,使用像素加法作为标识连接。每个残差模块中的卷积层具有相同数量的滤波器。使用了三个残差模块,在前两个残差模块之后使用最大池化层进行降采样。
此外,还利用通道注意模块来增强与人类视觉感知相关的信息特征,并抑制不那么有用的特征。首先,对输入通道注意模块的原始特征 应用全局平均池化层,从而产生一个通道描述符𝑑,该描述符囊括了各通道特征响应的嵌入式全局分布。其次,使用自门控机制(Hu 等人,2020 年)生成每个通道的调制权重。自门控机制包括两个全连接层,分别具有不同的 ReLU 和 Sigmoid 激活函数。然后,将这些权重应用于原始特征 ,生成重构特征 ,以防止梯度消失问题并保留原始特征的良好特性,具体如下:
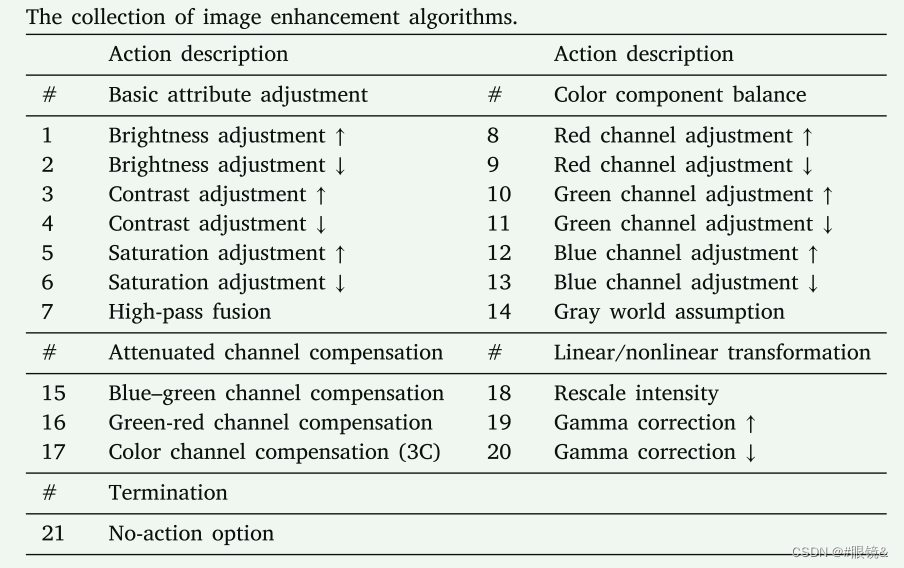
动作集合
 依据状态选择动作的策略
依据状态选择动作的策略
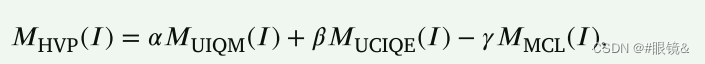
奖励计算方式
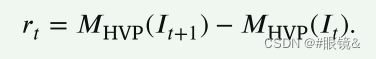
假设 𝑟𝑡 为正值。在这种情况下,它表示行动 𝑎𝑡 对改善当前图像 𝐼𝑡 的视觉效果有利,因此应鼓励代理网络选择该行动。相反,假设 𝑟𝑡 为负值。在这种情况下,它表示行动 𝑎𝑡 对改善当前图像 𝐼𝑡 的视觉效果不利。因此,应鼓励代理网络不要选择该操作。
标题:Revisiting coarse-to-fine strategy for low-light image enhancement with deep decomposition guided training
摘要
先前的粗到细策略通常在特征提取和特征重建上花费相等的精力,逐步从图像底部到顶部改善亮度,导致计算资源在恢复过程中利用效率不高。本文提出了一种名为RFLLIE的新型深度框架,用于强大且快速的低光图像增强。具体而言,首先采用由少量卷积层和池化层组成的轻量级CNN编码器,构建特征金字塔进行图像恢复。接着,提出了粗到细的恢复模块,包括级联的深度块、设计良好的空间注意层以及渐进扩张Resblocks,用于特征聚合和全局到局部的恢复。因此,RFLLIE采用了轻头重尾的架构,更加注重特征重建而非提取。
此外,还提出了基于Retinex理论的分解引导恢复损失,采用了“先对低光图像进行增强之后在分解”的策略,而非常见的“分解后再增强”,以进一步改善对比度并抑制噪声。我们的代码将会在https://github.com/JianghaiSCU/RFLLIE 上开放。
总结:本文提出了RFLLIE框架,通过轻量级CNN编码器和粗到细的恢复模块实现低光图像增强,采用了新颖的Retinex理论引导损失,方法在实验中表现出色,比现有方法在量化和视觉上都有显著优势,达到了性能和效率的良好平衡。
创新
-
提出了RFLLIE轻头重尾网络:我们通过重新审视粗到细恢复策略,提出了一种名为RFLLIE的轻头重尾网络,用于强大且快速的低光图像增强。该方法在计算效率高的同时,性能优于现有的最先进方法。
-
提出了粗到细恢复模块:我们设计了一个粗到细恢复模块,用于RFLLIE的特征重建阶段。该模块由级联的深度Resblocks、空间注意层和渐进扩张Resblocks组成,旨在从全局到局部重建特征信息。
-
提出了基于Retinex理论的分解引导恢复损失:我们提出了一种基于Retinex理论的分解引导恢复损失,采用“先增强在分解”策略,以进一步提高增强结果的视觉质量。
模型


图示详细解释
图(a):总体概述 -
输入与编码器:
- 输入的低光图像 ( S_{low} )。
- 多尺度CNN编码器将输入图像转换为多个尺度的特征金字塔 (\mathcal{F}),具体分为不同的特征层 (\mathcal{F}_0, \mathcal{F}_1, \mathcal{F}_2)。
-
粗到细恢复模块(CRM):
- GLEM(Global Enhancement Layer Module):在 (\mathcal{F}_2) 层进行全局特征增强。
- 结合深度Resblock、空间注意层和渐进扩张Resblock,对不同尺度的特征 (\mathcal{F}_i) 进行特征重建,从全局到局部逐步恢复。
-
重建与损失计算:
- 使用3x3卷积和1x1卷积层对重建后的特征进行融合,生成恢复后的图像 ( S_{restored} )。
- 使用预训练的分解网络将高质量图像 ( S_{high} ) 和恢复图像 ( S_{restored} ) 分解为反射图 ( R ) 和光照图 ( I )。
- 计算对比度损失 (\mathcal{L}{contrast}) 和去噪损失 (\mathcal{L}{denoise}),以及内容损失 (\mathcal{L}_{content})。
图(b):渐进扩张Resblock
- 输入特征: ( f_{input} )。
- 卷积操作:
- 通过一系列3x3卷积层进行处理,每个卷积层使用不同的扩张率(dilation)来捕捉不同尺度的特征。
- 扩张率从1到3逐渐增加,然后再逐渐减小回1。
- 输出特征: ( f_{output} ) 是处理后的输出特征。
图©:深度Resblock
- 输入特征:使用多层深度卷积(Depth Conv)处理输入特征。
- 深度卷积操作:
- 每个深度卷积层独立处理通道,保留空间信息的同时减少计算量。
- 输出特征:经过多层深度卷积处理后的输出特征。
关键点总结
- 多尺度特征提取:使用多尺度CNN编码器,将输入图像转换为不同尺度的特征层,形成特征金字塔。
- 粗到细恢复:通过粗到细恢复模块,从全局到局部逐步重建图像细节,确保高效且高质量的图像增强。
- 损失函数优化:使用基于分解引导的损失函数(包括对比度损失和去噪损失)和内容损失,指导网络优化,提高图像的视觉质量。
整体效果
RFLLIE框架通过以上方法,在保持计算效率的同时,显著提高了低光图像的增强效果,达到更好的视觉质量。
总结
使用先增强在分解的策略计算增强后的图像的分解图像的损失和正常图像分解之后的损失来计算损失指导权重的更新。
标题:Retinexmamba: Retinex-based Mamba for Low-light Image Enhancement
摘要
本文介绍了 RetinexMamba 架构。RetinexMamba 不仅抓住了传统 Retinex 方法的物理直观性,还集成了 Retinexformer 的深度学习框架,利用状态空间模型(SSM)的计算效率提高了处理速度。该架构具有创新的光照估计器和损伤恢复机制,可在增强过程中保持图像质量。==此外,RetinexMamba 还用融合注意力机制取代了 Retinexformer 中的 IG-MSA(光照引导多头注意力),提高了模型的可解释性。==在 LOL 数据集上进行的实验评估表明,RetinexMamba 在定量和定性指标上都优于基于 Retinex 理论的现有深度学习方法,这证实了它在增强弱光图像方面的有效性和优越性。代码见 https://github.com/YhuoyuH/RetinexMamba。
突出贡献
本文首次引入用于弱光增强的 Mamba,使用 SS2D 代替 Transformers 捕捉远距离依赖。
本文提出了一种融合模块,能更好地实现符合 Retinex 理论的光照特征嵌入。
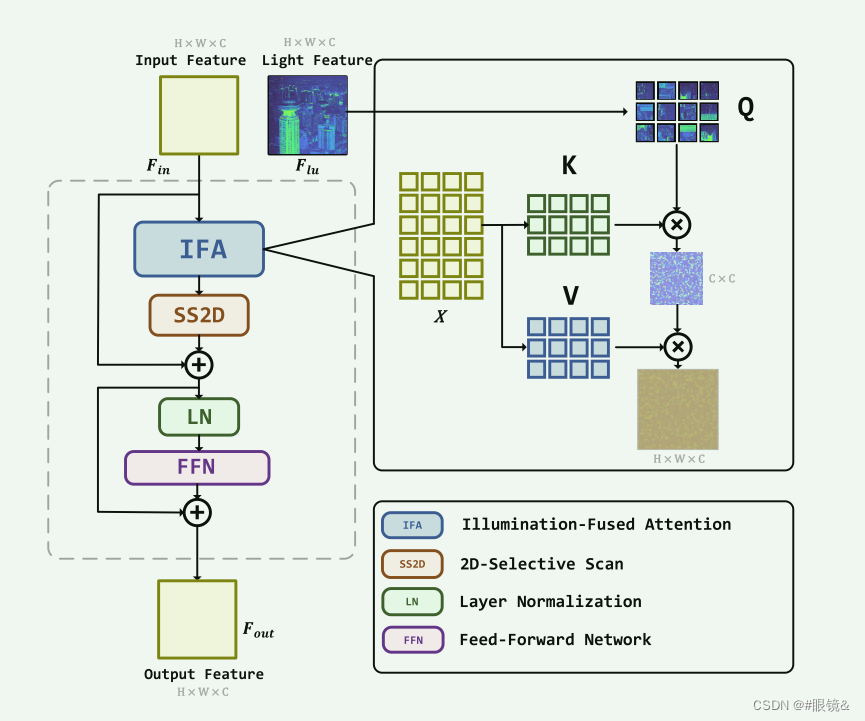
本文的网络架构
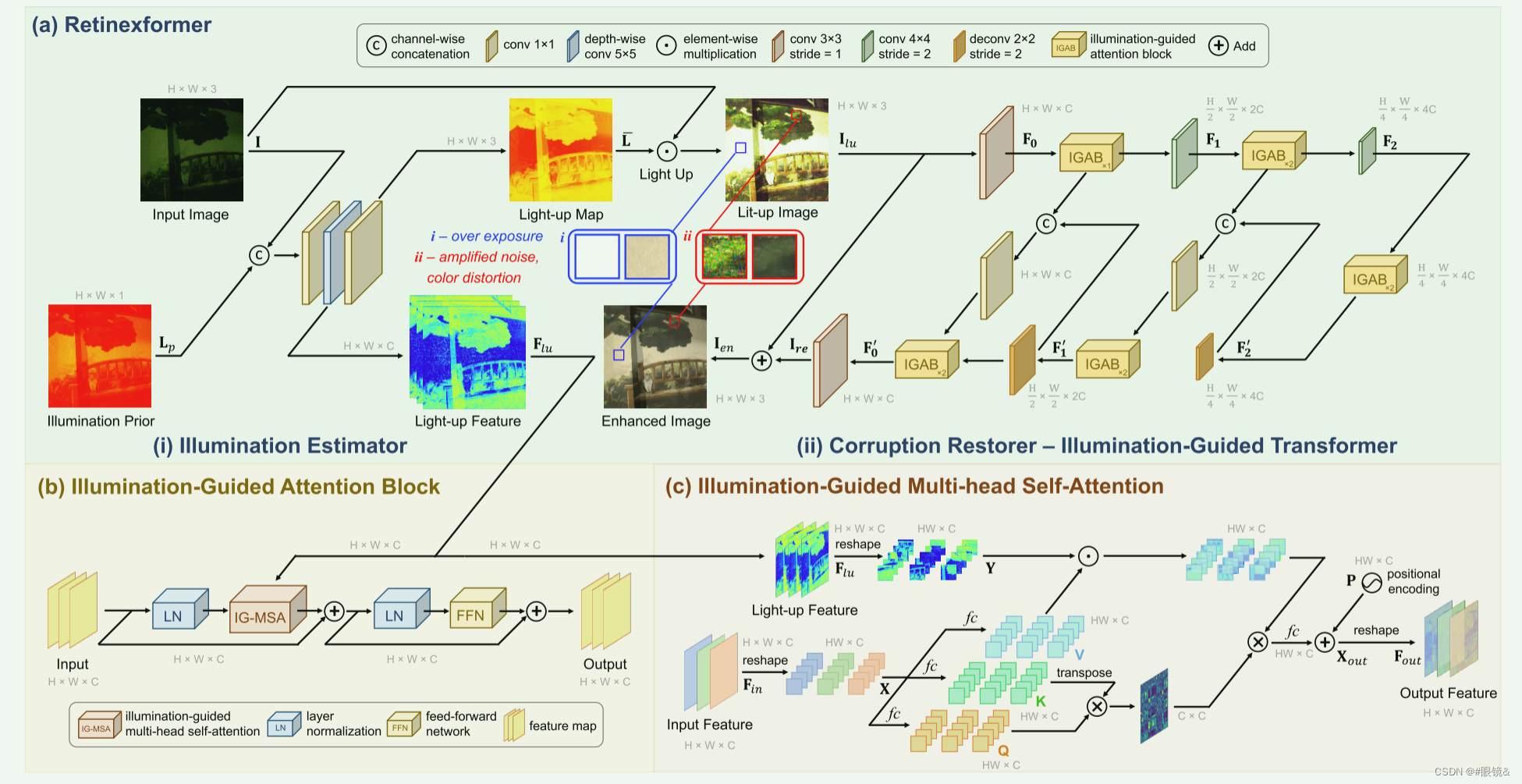
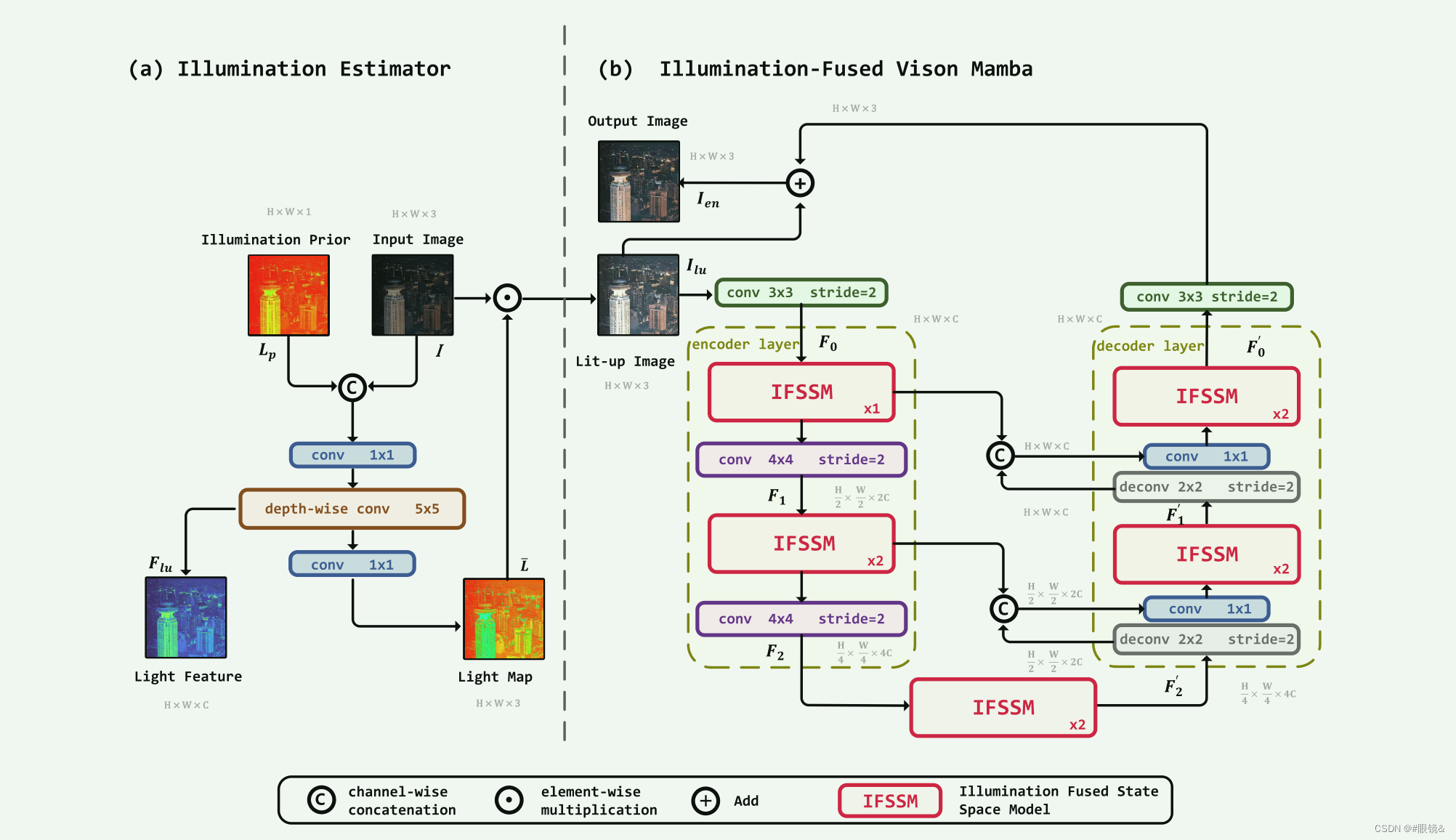 本文的 RetinexMamba 由照明度估算器(a)和损伤恢复器(b)组成。
本文的 RetinexMamba 由照明度估算器(a)和损伤恢复器(b)组成。
照明估计器(IE)受传统 Retinex 理论的影响。损伤恢复器的设计基于光照融合视觉曼巴(IFVM)。
照度估计器(IE)的结构如图(a)所示。我们将低照度原始图像 I 与通过计算获得的照度先验 Lp 合并,并增加通道维度作为输入。随后进行三次卷积以提取特征。第一个卷积 1 × 1 合并之前合并的输入,即把融合前的光照度应用到低照度图像中。第二个深度可分离卷积 5 × 5 对输入进行升采样,进一步提取特征,生成光照特征图 Flu,特征维数 nfeat 设为 40。最后,使用另一个 conv 1 × 1 进行降采样,以恢复 3 通道光照映射图 ¯L,然后将其元素乘以低照度图像 I,得到照明图像 Ilu。
损坏恢复器(IFVM)的结构如图 2(b)所示,它由基于光照融合视觉曼巴的编码器和解码器组成。编码器代表降采样过程,而解码器代表升采样过程。上采样和下采样过程是对称的,分为两个层次。首先,通过光照度估计器 IE 获得的照明图像 Ilu 被 3×3 的 conv(步长 = 2)降采样,以匹配照明特征图 Flu 的维度,从而方便后续操作。接下来,我们进行降采样,以降低计算复杂度并提取深度特征。下采样过程分为两层,每层包括一个光照融合状态空间模型(IFSSM)和一个步长为 2、核大小为 4 × 4 的卷积层。因此,经过两级下采样后,最深的特征维度应为 4C。提取图像特征后,我们需要进行上采样来恢复图像。与下采样类似,上采样也分为两层,每层包括一个 2 × 2 的去卷积层(步长 = 2)和一个 1 × 1 的卷积层,以及一个光照融合状态空间模型(IFSSM)。在每个解卷积层之后,图像的宽度和高度都会增加一倍,而特征维度则减半。然后,解卷积层的输出与相应的降采样照明融合状态空间模型(IFSSM)输出层相连接,以减少降采样过程中图像信息的丢失。最后,对图像进行 3 × 3(stride = 2)转换,以降低维度,并将其还原为具有三个通道的 RGB 格式。通过对恢复后的图像和 Ilu 进行残差连接,得到增强图像 Ien。
其中,◦ 表示元素相乘。反射分量 R 由物体的固有属性决定,而照明分量 L 则代表照明条件。然而,在这种公式表达式下,传统的 Retinex 算法无法考虑光线分布不均衡或弱光条件下的暗场景所产生的噪声和伪影,而且这种质量损失会随着图像的增强而进一步放大。因此,受 Retinex 算法的启发,我们采用了文献[2]提出的扰动建模方法,在原公式中引入了光照分量˜L 和反射分量˜R 的扰动项,如下式所示:
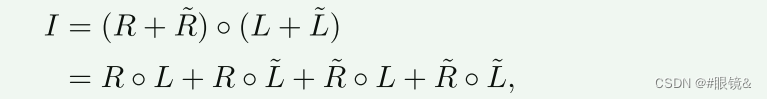
标题:Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancemen
摘要
本文中,我们提出了一个简单而原则性强的基于 Retinex 的单阶段框架(ORF)。ORF 首先估计照度信息以照亮低照度图像,然后恢复损坏的图像以生成增强图像。我们设计了一个光照引导变换器(IGT),利用光照表征来引导不同光照条件区域的非局部交互建模。通过将 IGT 插入 ORF,我们得到了我们的算法 Retinexformer。全面的定量和定性实验证明,我们的 Retinexformer 在 13 个基准测试中的表现明显优于最先进的方法。用户研究和弱光物体检测应用也揭示了我们方法的潜在实用价值。代码见 https://github. com/caiyuanhao1998/Retinexformer
本文贡献
本文提出了首个基于变换器的低照度图像增强算法 Retinexformer。
本文提出了一种基于 Retinex 的单阶段低照度增强框架 ORF,它具有简单的单阶段训练过程,并能很好地对损坏进行建模。
本文我们设计了一种新的自我关注机制–IG-MSA,它利用光照信息作为关键线索来指导长距离依赖关系的建模。
本文总体架构
标题:DICAM: Deep Inception and Channel-wise Attention Modules for underwater image enhancement
摘要
在水下环境中,成像设备会受到水的浑浊度、光的衰减、散射和颗粒的影响,导致图像质量低、对比度差和色彩偏差。这给使用传统视觉技术进行水下状态监测和检测带来了巨大挑战。近年来,水下图像增强因其在提高当前计算机视觉任务中水下物体检测和分割性能方面的关键作用而受到越来越多的关注。由于现有的方法主要基于自然场景,在提高色彩丰富度和分布方面存在性能限制,因此我们提出了一种基于深度学习的新方法,即深度感知和信道注意模块(DICAM),以提高朦胧水下图像的质量、对比度和偏色。所提出的 DICAM 模型可提高水下图像的质量,同时考虑到比例退化和非均匀偏色。
着重解决的问题
捕捉到的用户界面的劣化程度与物体和摄像机之间的距离成正比 。例如,如图 所示,在原始水下图像中,距离摄像机较远的高亮区域与距离摄像机较近的中心区域相比,其内容并不清晰可见。

本文的创新
(1) 使用阈值模块进行多尺度信道特征提取,以同时量化与色彩和距离相关的比例退化、色彩和内容信息损失以及色彩丰富度;
(2) 基于自适应融合的恢复和增强流程,其中包含信道关注模块 (CAM)。
我们的方法使我们能够生成具有更好的偏色和色彩丰富度的高质量增强图像,通过专门的色彩校正阶段产生视觉上更悦目、更自然的外观。
本文解决的问题
一般来说,水下图像有两个主要缺陷:(1) 比例衰减和 (2) 非均匀光衰减导致能见度低和色彩信息丢失。
如图 上图所示,比例衰减主要影响图像中不同区域内容(如物体、颗粒等)的可见度比例,离摄像机近的内容比远的内容可见度高,这意味着水下图像中不同区域的衰减率不同。‘
另一方面,不均匀的光衰减会使大部分捕捉到的用户界面看起来偏蓝或偏绿。
因此,为了解决上述质量下降问题并相应地增强用户界面,我们设计了一种深度神经网络架构,其灵感来自于萌芽[42]和注意力模块[43],分为三个阶段,即通道级色彩恢复、色彩校正和维度缩减,如图所示。
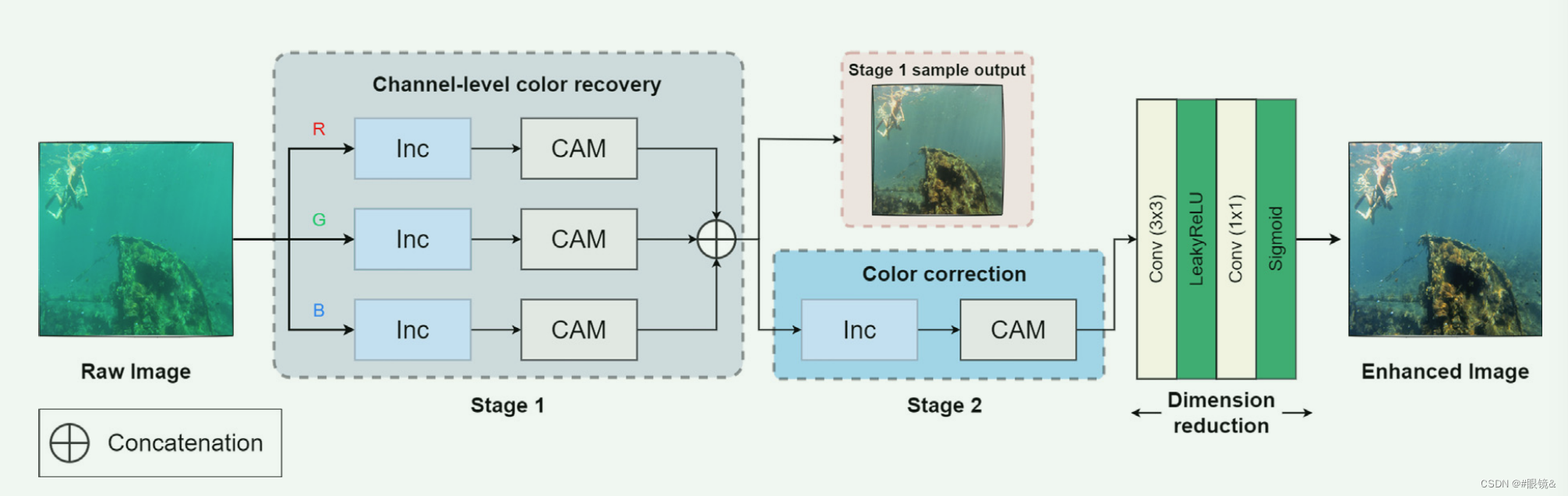 如图所示,为了有效捕捉不同尺度各彩色通道的比例退化,我们使用了著名的 Inception(Inc)模块[42](如图 3-(a)所示)进行特征提取。从图中可以看出,除了通过 Max-Pooling 层获得的轮廓信息外,Inc 还允许我们用不同尺度(即 1 × 1(像素)、3 × 3 和 5 × 5)的结构特征图来表示输入图像。然而,3 × 3、5 × 5 和轮廓信息的降解率并不相同。因此,受文献[43]的启发,我们通过使用通道关注模块(CAM)(如图 3-(b) 所示),对提取的特征图进行了权衡。所提出的策略可以同时考虑颜色通道级和各种结构尺度的质量退化,从而进一步提高增强性能和内容表现力。
如图所示,为了有效捕捉不同尺度各彩色通道的比例退化,我们使用了著名的 Inception(Inc)模块[42](如图 3-(a)所示)进行特征提取。从图中可以看出,除了通过 Max-Pooling 层获得的轮廓信息外,Inc 还允许我们用不同尺度(即 1 × 1(像素)、3 × 3 和 5 × 5)的结构特征图来表示输入图像。然而,3 × 3、5 × 5 和轮廓信息的降解率并不相同。因此,受文献[43]的启发,我们通过使用通道关注模块(CAM)(如图 3-(b) 所示),对提取的特征图进行了权衡。所提出的策略可以同时考虑颜色通道级和各种结构尺度的质量退化,从而进一步提高增强性能和内容表现力。
除了比例上的劣化之外,光线的衰减也会进一步导致色彩失真,如偏蓝或偏绿。因此,需要对提取的特征图进行自适应加权,以恢复真实色彩。在第二阶段对提取的特征图进行串联后,我们从合并的色彩特征图中提取特征,以捕捉更高层次的衰减,并使用 CAM 对其进行权重。在这一阶段,CAM 可帮助模型找回丢失的色彩信息,并通过对红、绿、蓝通道特征的自适应加权进行相应的色彩校正。
本文阅读总结
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 955
955











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}