










一.简介
YOLOV4出现之后不久,YOLOv5横空出世。YOLOv5在YOLOv4算法的基础上做了进一步的改进,检测性能得到进一步的提升。虽然YOLOv5算法并没有与YOLOv4算法进行性能比较与分析,但是YOLOv5在COCO数据集上面的测试效果还是挺不错的。大家对YOLOv5算法的创新性半信半疑,有的人对其持肯定态度,有的人对其持否定态度。在我看来,YOLOv5检测算法中还是存在很多可以学习的地方,虽然这些改进思路看来比较简单或者创新点不足,但是它们确定可以提升检测算法的性能。其实工业界往往更喜欢使用这些方法,而不是利用一个超级复杂的算法来获得较高的检测精度。本文主要将对YOLOv5检测算法应用到自己的场景中,适合小白入门。
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
1>输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
2> 基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
3> Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
4> Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
二.开发环境
2.1安装Anaconda
Anaconda官网:https://link.zhihu.com/?target=https%3A//www.anaconda.com/
安装完成后打开cmd:
输入conda -V,查看是否安装成功:出现版本号即为安装成功。

注:安装Anaconda的目的是为了可以配置好多独立的开发环境,不同项目互不影响。
2.2 创建虚拟环境
这里我们为yolov5单独创建一个环境,输入: conda create -n pytorch17 python=3.7
安装完成后,输入: activate pytorch17 即可激活环境
- 安装pytorch
yolov5最新版本需要pytorch1.6版本以上,因此我们安装pytorch1.7版本。由于我事先安装好了CUDA10.1,因此在环境中输入
pip install torch1.7.0+cu101 torchvision0.8.1+cu101 torchaudio===0.7.0 -f https://download.pytorch.org/wh
注:查看自己电脑CUDA是否可用
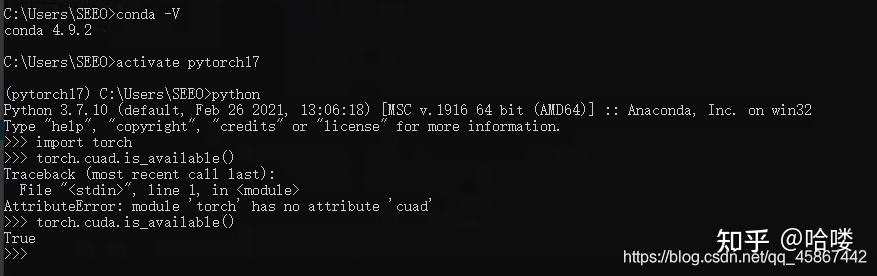
这里显示True表明正常安装。
三.模型训练
3.1代码下载
源码地址:https://link.zhihu.com/?target=https%3A//github.com/ultralytics/yolov5
下载后解压,在目录内打开cmd并激活环境
输入 pip install -r requirements.txt 安装依赖库
3.2数据准备
首先我们要对自己的数据进行标注,标注的工具LabelImg,如果是windows用户的话,可以直接下载可执行文件,labelImg的下载地址以及使用,可以参考博客windows下使用labelImg标注图像。https://link.zhihu.com/?target=https%3A//blog.csdn.net/python_pycharm/article/details/85338801
在根目录下建立一个VOCData文件夹,再建立两个子文件;其中,jpg文件放置在VOCData/images下,xml放置在VOCData/Annotations下 这里我使用的是自己整理的交通指示信号灯照片,标签划分为12类speed limits、go straight、no enter、turn right、turn left、driving around the island、go straight and turn left、go straight and turn right、no turn right、no turn left、road narrows on right、road narrows on left。
想要数据集小伙伴可以私信。
3.3数据预处理
创建 split.py 文件,运行结束后,可以看到VOCData/labels下生成了几个txt文件;
然后新建 txt2yolo_label.py 文件用于将数据集转换到yolo数据集格式;转换后可以看到VOCData/labels下生成了每个图的txt文件;
在data文件夹下创建myvoc.yaml文件,修改训练类别数nc为12
3.4预训练权重下载
这里训练yolov5m模型,因此将它的预训练模型下载到weights文件夹下
运行train.py 即可开始训练 这里迭代了300次 效果还不错 大家可以根据自己情况相应处理
四.检测结果
输入detect.py 将生成的最佳模型 best.pt加载到指定位置
将测试图片提前放到相应文件夹,根据自己路径进行修改路径,运行结果会在detect下的exp文件夹下生成。
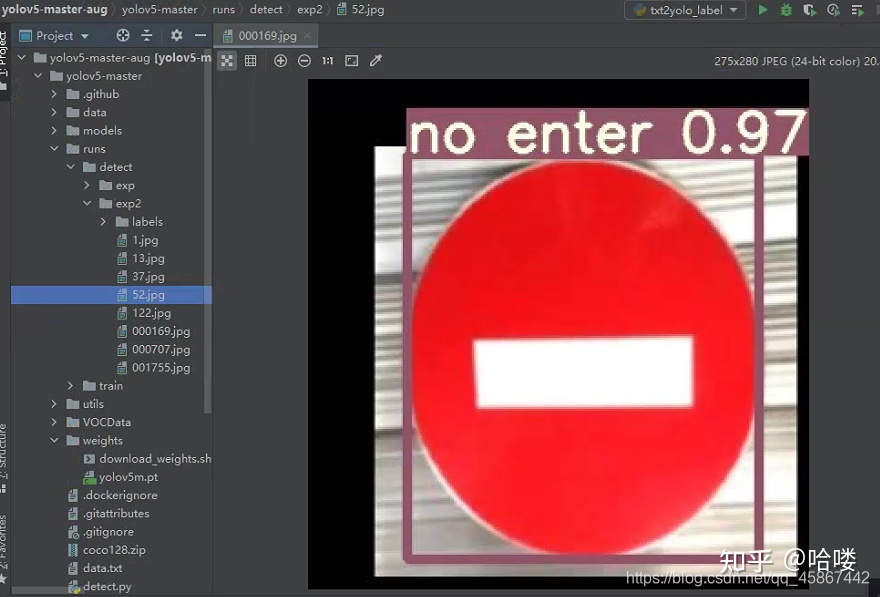
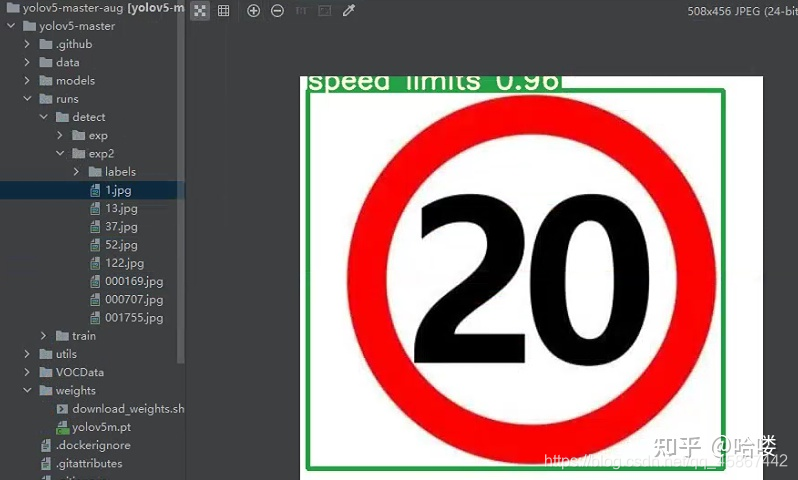
4.1 部分检测结果图
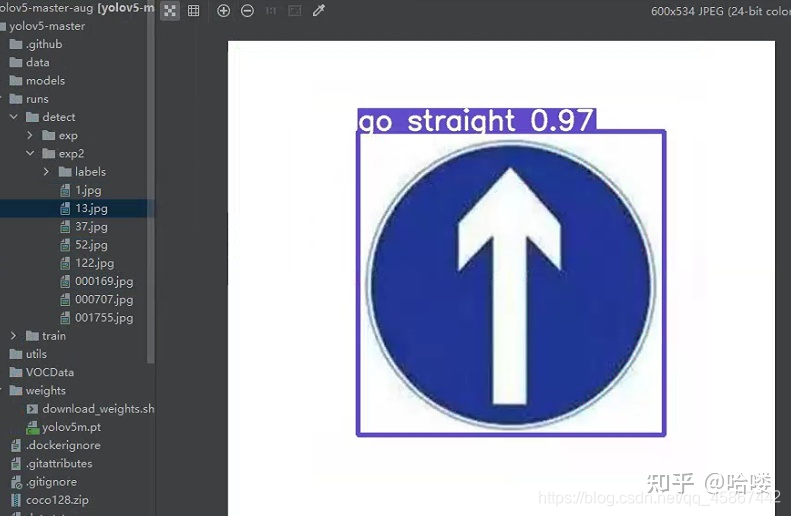
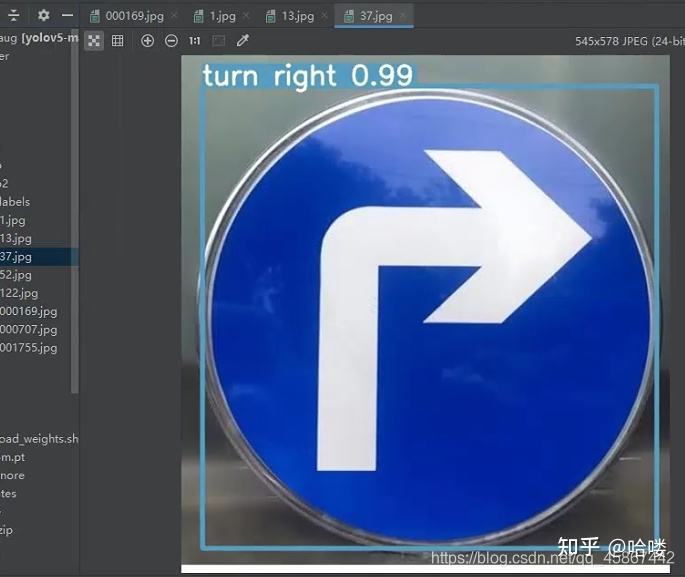
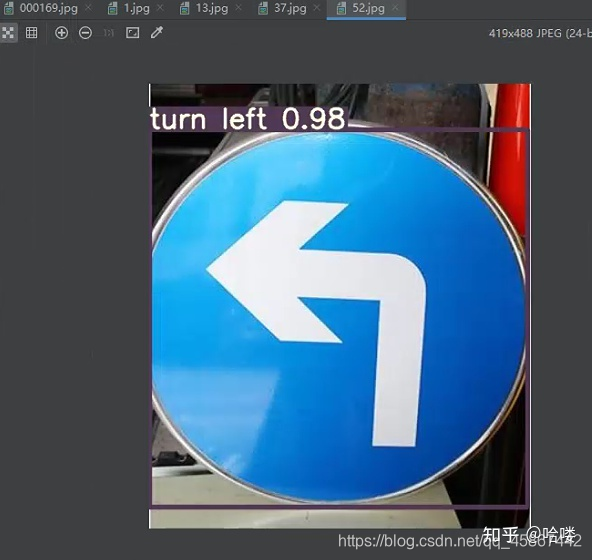



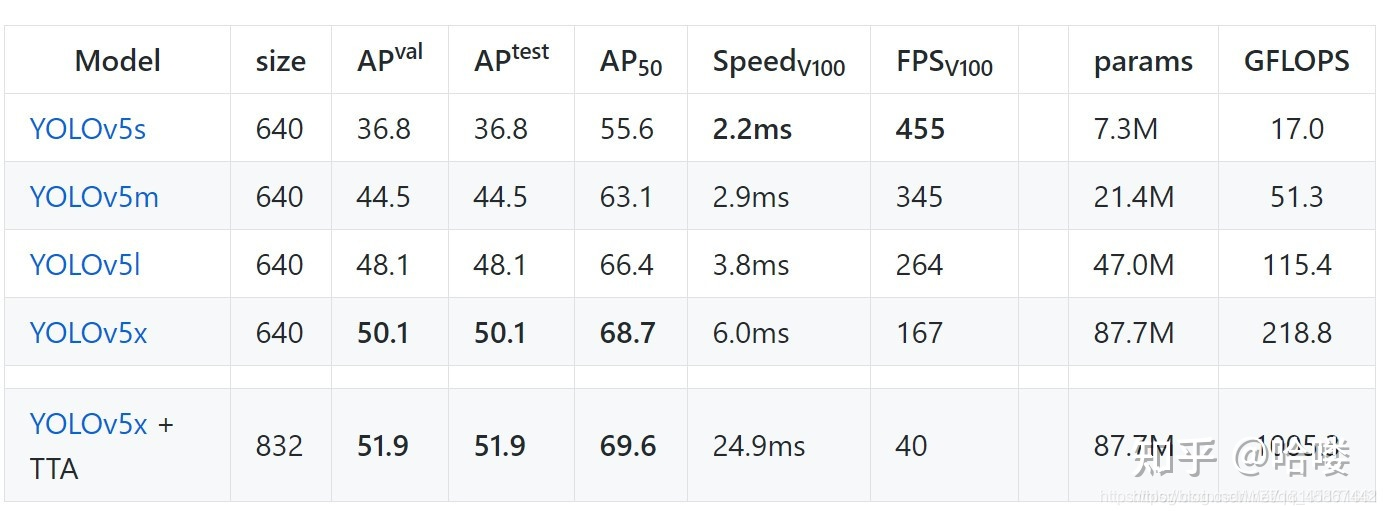
4.2模型评价指标
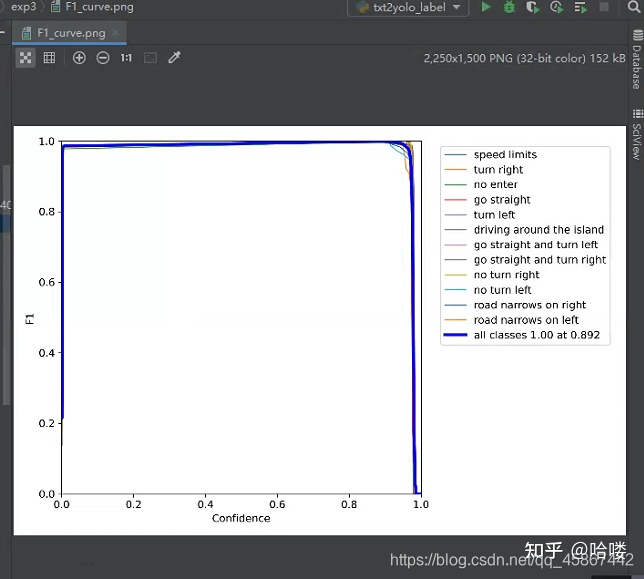
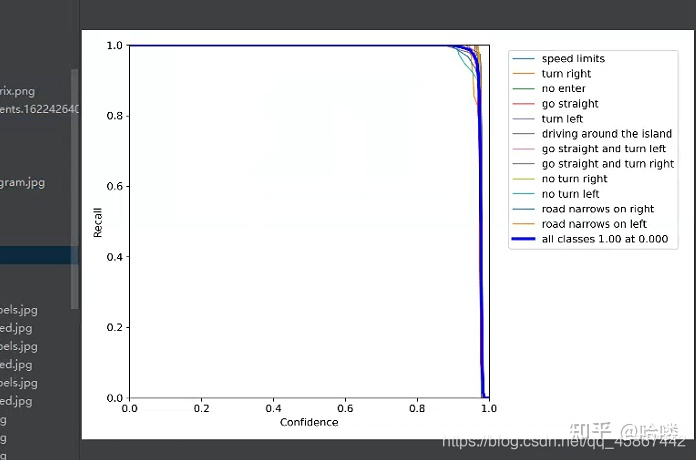
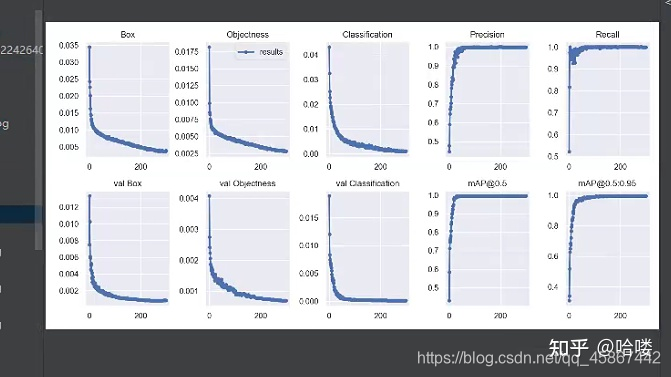
由于水平有限,文章中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!有任何疑问的小伙伴都可以私信,大家一起学习交流。

参考
我的知乎首发 https://zhuanlan.zhihu.com/p/378766432














 1334
1334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









