






SalFAU-Net:显著性目标检测的显著性融合注意U-Net
SalFAU-Net: Saliency Fusion Attention U-Net for Salient Object Detection
摘要
显著目标检测(SOD)在计算机视觉中仍然是一个重要的任务,其应用范围从图像分割到自动驾驶。基于全卷积网络(FCN)的方法在过去几十年里在视觉显著性检测方面取得了显著进展。然而,这些方法在准确检测显著目标方面存在局限性,尤其是在具有多个目标、小目标或低分辨率目标的具有挑战性的场景中。
为了解决这个问题,作者提出了一种显著性融合注意力U-Net(SalFAU-Net)模型,该模型在每个解码器块中引入了一个显著性融合模块,以从每个解码器块生成显著性概率图。
SalFAU-Net采用了一种注意力机制,有选择地聚焦于图像中最具信息性的区域,并抑制非显著区域。作者使用二进制交叉熵损失函数在DUTS数据集上训练SalFAU-Net。作者在六个流行的SOD评估数据集上进行了实验,以评估所提出方法的有效性。实验结果表明,作者的方法SalFAU-Net在平均绝对误差(MAE)、F-measure、s-measure和e-measure方面与其他方法相比具有竞争力。
Introduction
显著目标检测(SOD),也称为视觉显著性检测,是指在场景中检测最显眼、独特且视觉上与众不同的物体或区域,这些物体或区域能吸引人的目光[3]。人类的视觉感知系统具有迅速识别并关注场景中视觉独特和突出物体或区域的能力[37]。这种天生的能力吸引了计算机视觉领域中许多研究者的兴趣,他们的目标是基于人类视觉注意力系统的心理和生物学特性来模拟这一过程。目标是识别图像和视频中具有重要性和有价值信息的显著物体。
鉴于SOD在计算机视觉各个领域应用的多样性,它在图像分割、目标检测、图像字幕生成[43]、自动驾驶[29]和增强现实[8]等任务中作为预处理步骤发挥着关键作用,提出了许多视觉显著性检测方法。这些方法旨在从较不重要的背景中区分出最独特的前景图像。尽管传统的显著性检测方法依赖于低级启发式视觉特征,但这些方法常常无法在具有挑战性的场景中检测到显著物体。近年来,深度学习方法,尤其是卷积神经网络(CNNs),在包括显著性检测在内的多种计算机视觉任务中显示出卓越的有效性。与传统的学习方法相比,基于CNN的方法通过利用先进的语义特征[16]取得了显著进展。
由于代表性特征对算法性能的重大影响,研究利用多级特征和上下文信息以增强显著性检测的模型是有益的。此外,尽管已经引入了基于全卷积网络(FCNs)的端到端模型,但在显著性检测任务中融合和提升传统的FCN模型,如U-Net[34]及其变体仍然具有重要意义。U-Net的一个著名变体,因其有效用于医学图像分割而知名,是Attention U-Net网络[28],它通过在其架构中集成注意力机制,有选择地关注输入图像的相关区域,从而提高了模型捕捉复杂模式和重要特征的能力。注意力机制在图像分割等任务中可以改善性能。基于其在医学图像分割上的成功,本研究探讨了将Attention U-Net应用于显著性检测任务的可能性。作者在网络的每个解码器块中添加了一个显著性融合模块(SFM)。
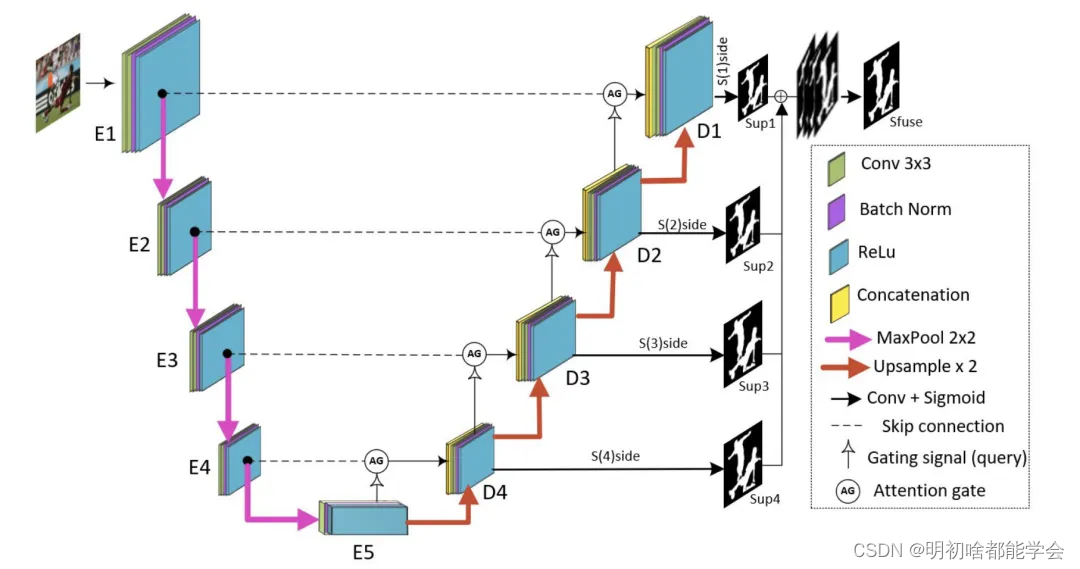
该模块使作者能够有效地生成显著性图,然后作者将每个解码器的侧输出显著性图进行拼接以获得最终的显著性图。所提出方法中的注意力门模块帮助模型学习关注不同大小和形状的显著特征。这样,SalFAU-Net能够抑制输入图像中的不相关区域,同时强调对显著性检测最重要的特征。总之,本文的主要贡献如下:
(1) 作者提出了一种用于视觉显著性检测的显著性融合注意力U-Net(SalFAU-Net)。
(2) 在网络的每个解码器块中添加显著性融合模块,以从每个解码器生成显著性图,并将这些显著性图拼接在一起,以获得最终的视觉表达,突出图像中最重要的区域或物体。
(3) 作者在六个公开可用的具有挑战性的SOD数据集上进行了实验,结果证明了SalFAU-Net在视觉显著性检测任务中的有效性。
Related Works
一般来说,显著性检测方法可以分为两类:传统方法和基于深度学习的方法。传统方法基于低级启发式视觉特征,如对比度、位置和纹理。这些方法大多数是无监督或半监督的。传统显著性检测方法的例子包括基于局部对比度[22]、全局对比度[44]、背景先验[45]、中心先验[42]、目标性先验[20]等。这些方法在简单图像或仅包含单个目标的场景中取得了良好的效果。然而,这些方法无法检测复杂场景、低分辨率或包含多个显著目标的场景中的显著物体。
这种局限性源于它们依赖于低级特征,这些特征对于处理由这类具有挑战性的视觉环境引入的复杂性是不够的。
近年来,基于深度学习的方法,尤其是卷积神经网络(CNNs),在多种计算机视觉任务中展示了卓越的性能,包括图像分类[17],语义图像分割[24]和目标检测[41]。CNN能够通过提取高级语义特征来学习输入数据的丰富和层次化表示。然而,在视觉显著性检测(SOD)中,低级和高级特征对于开发良好的视觉显著性检测模型都至关重要。全卷积网络(FCNs)[25]的引入彻底改变了端到端的像素级显著性检测方法。
最初为语义分割设计的FCN,在单一网络结构中无缝结合了特征提取和像素标签预测的任务,该结构由下采样和上采样路径组成。随后,提出了许多基于FCN的视觉显著性检测模型,包括深度对比学习(DCL),多级卷积特征聚合框架(Amulet),递归全卷积网络(RFCN)[39],以及深度不确定卷积特征(UCF)。这些进展显著提高了视觉显著性检测算法的有效性。尽管如此,探索针对不同目的设计的有效的基于FCN的模型仍然是有益的。U-Net是医学图像分割[34]中最广泛使用的网络之一。
在U-Net成功的基础上,为不同的任务引入了许多网络变体。U-Net的一个典型变体是关注U-Net模型,它专为胰腺图像分割而设计,在其他组织和器官分割中展示了令人印象深刻的结果,得益于关注门模块,能够专注于图像中相关和可变大小的区域。
大多数基于FCN的显著性模型都基于普通的U-Net,并在显著性检测方面取得了显著性能。[32]中,秦等人提出了一种双 Level 嵌套U结构,通过使用残差U块(RSU)作为视觉显著性检测的主干。与许多其他使用预训练网络作为主干的网络相比,U-2-Net的RSU块在不显著增加计算成本的情况下增加了架构深度,同时实现了竞争性性能。[14]中,韩等人提出了一种修改后的U-Net网络用于显著性检测,利用了边缘卷积约束。
这个变体有效地整合了来自多层的特征,减少了信息丢失,并实现了像素级的显著性图预测,而不是基于块级的预测,这是CNN模型中常见的。
尽管基于普通U-Net的方法在显著性检测方面取得了显著性能,但通过将不同的技术融入其架构的编码器和解码器块中,可以进一步提升其性能。最近,注意力机制在包括显著性检测在内的各种计算机视觉应用中显示出显著成果。在[21]中,Li 等人 提出了一个U形网络,该网络采用堆叠层并融合通道注意力来提取最重要的通道特征,并通过集成并行膨胀卷积模块(PDC)和多级注意力级联反馈(MACF)模块有效地利用这些特征。
为了分别用不同的衰减因子递归地转换和聚合上下文特征,Hu 等人 [15] 提出了一个空间衰减上下文模块。之后,该模块仔细学习权重以自适应地融合集体上下文特征。在[48]中,Zhang 等人 提出了一种新的视觉显著性检测方法,该方法利用注意力机制来细化显著性图,并通过双向细化来提高准确性。
引入双向细化突出了对全面特征提取和优化的关注。在[49]中,Zhao和Wu将空间注意力(SA)和通道注意力(CA)应用于模型的各个方面。具体来说,SA用于低级特征图,而CA融合到具有上下文感知的金字塔特征图中。这种策略性方法旨在指导网络关注给定样本的最相关特征。在[13]中,Gong等人 提出了一个增强型U-Net模型,该模型融合了金字塔特征注意力、通道注意力和金字塔特征提取模块,以提升U-Net主干网络的性能。
在这项研究中,作者尝试探索注意力U-Net架构在视觉显著性检测领域的应用。作者在网络的每个解码器中添加了一个显著性融合模块(SFM),并将它们的输出连接起来以获得最终的显著性图。所提出方法中的注意力门模块帮助模型学习关注不同大小和形状的显著特征。因此,SalFAU-Net能够学习在输入图像中抑制不相关或不需要的区域,同时强调对于显著性检测任务最为关键和显著的特性。
Methodology
在本节中,作者提供了作者提出方法的架构的详细描述。随后是网络监督、所使用的数据集和评估指标以及实现细节。
Architecture of SalFAU-Net
本文提出的用于视觉显著性检测的融合显著性注意U-Net(SalFAU-Net)主要由四部分组成:
1)一个五级编码块
2)一个四级解码块
3)一个注意门控模块
4)一个显著性融合模块。
图1展示了所提出的SalFAU-Net模型的架构。与用于胰腺图像分割的[28]提出的Attention U-Net模型相比,作者在架构的每个解码器中增加了一个显著性融合模块,并将它们最终连接在一起以获得最终的显著性图。
Encoder Block
每个编码器块包含两个卷积层,其后分别跟着批量归一化层和ReLu激活函数,这会将特征图的数量从3增加到1024。在每个块的末尾,除了最后一个块,都应用了2x2步长的最大池化进行下采样,将图像大小从288x288减少到18x18。编码器块逐步降低特征图的空间分辨率,同时增加通道数,捕捉不同尺度的特征。
Decoder Block
解码器块负责上采样和生成显著图。它由一个上采样层、两个卷积层、批量归一化和ReLU激活函数组成。解码器块通过跳跃连接与注意力门控块相连。每个解码器块将特征图的数量减少一半,同时将空间分辨率从18x18增加到288x288。其目的是恢复在编码器下采样过程中丢失的空间细节,从而便于精确地定位和检测显著物体。
Attention Gate Module
注意力门(AGs)在捕捉关键区域、减少无关背景区域中的特征响应以及消除对图像中感兴趣区域(ROI)进行裁剪的需求方面表现出显著的有效性。这对于视觉显著性检测任务尤为重要。将AGs整合到传统的U-Net架构中,增强了模型通过跳跃连接强调显著特征的能力。对于一个跳跃连接特征
F
R
∈
R
C
×
H
×
W
FR \in \mathbb{R}^{C \times H \times W}
FR∈RC×H×W,其中
C
C
C是通道数,
H
H
H和
W
W
W是高度和宽度,作者首先应用一个卷积层、批量归一化和ReLU激活函数以获得一个关键特征
K
K
K,并令
Q
Q
Q来自前一层或通过卷积层以及批量归一化和ReLU激活后得到的输入门控特征
F
g
F_g
Fg的门控信号。注意力系数
α
\alpha
α通过对
Q
Q
Q和
K
K
K的逐元素求和后应用ReLU函数来获得。最终的注意力系数值
V
V
V是通过将注意力系数
α
\alpha
α送入一个卷积层、批量归一化和sigmoid激活函数来得到的。最后,将注意力系数值
V
V
V与跳跃连接特征图进行逐元素相乘,产生最终的注意力门输出,其计算如下方程所示:
att = σ 2 ( o 2 ( W T ⋅ o 1 ( W T ⋅ K i + b x ) + b y ) ) \text{att} = \text{σ}_2(\text{o}_2(W_{\text{T}} \cdot \text{o}_1(W_{\text{T}} \cdot K_i + b_{\text{x}}) + b_{\text{y}})) att=σ2(o2(WT⋅o1(WT⋅Ki+bx)+by))
o = o 2 ( att ( Q , K i ; e att ) ) , c = o ⋅ K i , \text{o} = \text{o}_2(\text{att}(Q, K_i; e_{\text{att}})), \quad c = o \cdot K_i, o=o2(att(Q,Ki;eatt)),c=o⋅Ki,
其中
σ
2
(
z
i
,
c
)
=
1
1
+
e
−
z
i
,
c
\text{σ}_2(z_{i,c}) = \frac{1}{1+e^{-z_{i,c}}}
σ2(zi,c)=1+e−zi,c1 表示sigmoid激活函数。因此,注意力生成(AG)由参数集
θ
att
θ_{\text{att}}
θatt 定义,包括线性变换
W
∈
R
F
×
F
t
W \in \mathbb{R}^{F \times F_t}
W∈RF×Ft,
W
q
∈
R
F
×
F
n
t
W_q \in \mathbb{R}^{F \times F_{nt}}
Wq∈RF×Fnt,
o
1
∈
R
F
n
t
×
1
\text{o}_1 \in \mathbb{R}^{F_{nt} \times 1}
o1∈RFnt×1 和偏置项
b
y
∈
R
b_y \in \mathbb{R}
by∈R,
b
∈
R
F
m
t
b \in \mathbb{R}^{F_{mt}}
b∈RFmt。线性变换可以通过对输入张量使用逐通道的
1
×
1
1 \times 1
1×1卷积来计算。
显著性融合模块
显著性图融合模块是生成显著性概率图的关键组成部分。与文献[32]中的方法类似,作者的模型采用多阶段方法。最初,它生成了四个侧输出显著性概率图,分别表示为
S
side
(
1
)
S^{(1)}_{\text{side}}
Sside(1),
S
side
(
2
)
S^{(2)}_{\text{side}}
Sside(2),
S
side
(
3
)
S^{(3)}_{\text{side}}
Sside(3)和
S
side
(
4
)
S^{(4)}_{\text{side}}
Sside(4),这些图来自解码器1、解码器2、解码器3和解码器4的相应阶段。这是通过一个
3
×
3
3 \times 3
3×3卷积层以及一个sigmoid激活函数完成的。随后,这些侧输出显著性图的sigmoid函数之前的卷积输出被上采样到与输入图像相同的大小。通过ConCat操作,然后是一个
1
×
1
1 \times 1
1×1卷积层和一个sigmoid函数,来完成这些显著性图的整合。这一融合过程的输出是最终的显著性图
S
final
S_{\text{final}}
Sfinal(如图1右下所示)。
从数学上讲,每个阶段的显著性概率图生成如下:
S
side
(
i
)
=
σ
(
Conv
(
i
)
(
X
)
)
S^{(i)}_{\text{side}} = \sigma(\text{Conv}^{(i)}(X))
Sside(i)=σ(Conv(i)(X))
其中
i
i
i表示阶段(1、2、3或4),
σ
\sigma
σ表示sigmoid函数,
Conv
(
i
)
\text{Conv}^{(i)}
Conv(i)是在第
i
i
i阶段的卷积操作,
X
X
X是解码器的输出特征图。然后侧输出被上采样并拼接以生成最终的显著图
S
final
S_{\text{final}}
Sfinal:
S
final
=
σ
(
Conv
fine
(
Concat
(
S
side
(
i
)
)
)
)
S_{\text{final}} = \sigma(\text{Conv}_{\text{fine}}(\text{Concat}(S^{(i)}_{\text{side}})))
Sfinal=σ(Convfine(Concat(Sside(i))))
其中
Concat
\text{Concat}
Concat表示拼接操作,
Conv
fine
\text{Conv}_{\text{fine}}
Convfine是专门用于融合过程的
1
×
1
1 \times 1
1×1卷积层,
α
\alpha
α表示sigmoid函数。
Network Supervision
损失函数在优化显著性检测模型中起着至关重要的作用。在二分类问题中最广泛使用的损失函数之一是二元交叉熵(BCE)损失[5]。对于视觉显著性检测,它衡量在二分类设置中预测的显著性图与真实标签(GT)之间的不相似性。
作者采用了与[32]中类似的深度监督方法,该方法已经证明了其有效性。作者的训练损失表述如下:
L
=
∑
i
=
1
m
w
side
i
L
side
i
+
w
fuse
L
fuse
L = \sum_{i=1}^m w_{\text{side}}^i L_{\text{side}}^i + w_{\text{fuse}} L_{\text{fuse}}
L=i=1∑mwsideiLsidei+wfuseLfuse
总损失由两部分组成。第一部分是与侧面输出显著性图相关的损失,记作
L
side
i
L_{\text{side}}^i
Lsidei,其中
m
m
m表示图1中显示的四个监督阶段(Sup1, Sup2, Sup3, 和Sup4)。第二部分是最终融合输出显著性图的损失,由
L
fuse
L_{\text{fuse}}
Lfuse表示。分配给这些损失项的权重分别是
w
side
w_{\text{side}}
wside和
w
fuse
w_{\text{fuse}}
wfuse。
作者使用传统的二元交叉熵计算每个项的损失,以计算预测显著性图与GT之间的像素级比较。
L
=
−
1
H
W
∑
(
x
,
y
)
[
G
(
x
,
y
)
log
P
(
x
,
y
)
+
(
1
−
G
(
x
,
y
)
)
log
(
1
−
P
(
x
,
y
)
)
]
L = -\frac{1}{HW} \sum_{(x, y)} [G(x, y) \log P(x, y) + (1 - G(x, y)) \log(1 - P(x, y))]
L=−HW1(x,y)∑[G(x,y)logP(x,y)+(1−G(x,y))log(1−P(x,y))]
其中
(
H
,
W
)
(H, W)
(H,W)是图像的高度和宽度,
(
x
,
y
)
(x, y)
(x,y)是像素的坐标。GT和预测显著性概率图的像素值分别由符号
G
(
x
,
y
)
G(x, y)
G(x,y)和
P
(
x
,
y
)
P(x, y)
P(x,y)表示。训练过程的目标是减少总损失
L
L
L。在测试过程中,作者选择融合输出
L
fuse
L_{\text{fuse}}
Lfuse作为作者的最终显著性图。

















 3400
3400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









