







先看题目噢---------------------价值学习(还有一种方法是策略学习)
一、DQN与Q学习
1. DQN
- 我们希望知道 Q ⋆ Q ⋆ Q⋆ ,因为它就像是先知一般,可以预见未来,在 t 时刻就预见 t 到 n时刻之间的累计奖励的期望。近似学习“先知”Q ⋆ 最有效的办法是深度 Q网络(deep Q network,缩写 DQN),记作 Q ( s , a ; w ) Q(s,a;\bf{w}) Q(s,a;w),
- 首先随机初始化参数 w,随后用“经验”去学习 w。学习的目标是:对于所有的 s 和 a,DQN 的预测 Q(s,a;w) 尽量接近 Q ∗ ( s , a ) Q_*(s,a) Q∗(s,a)。
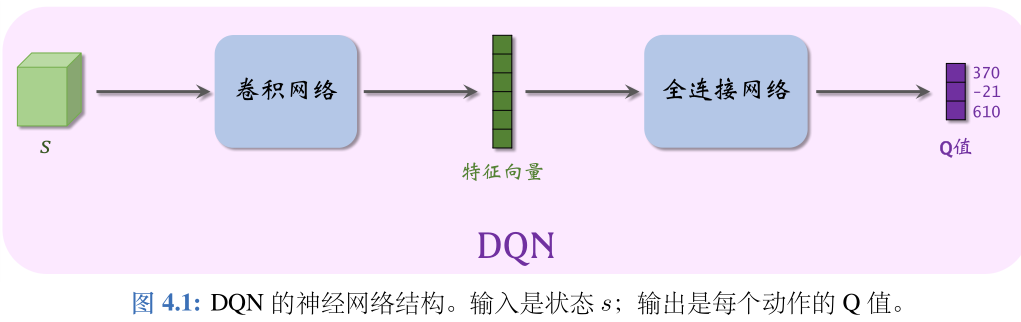
- DQN 的输出是离散动作空间 A 上的每个动作的 Q 值,
2.时间差分 (TD) 算法
- 训练 DQN 最常用的算法是时间差分(temporal difference,缩写 TD)。
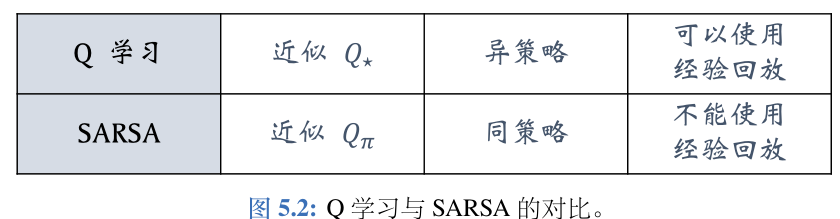
- TD 算法是一大类算法,常见的有 Q 学习和 SARSA。Q 学习的目的是学到
最优动作价值函数 Q ⋆,而 SARSA 的目的是学习动作价值函数Q π Q_\pi Qπ。 - TD 算法的目的是通过更新参数 w 使得损失 L ( w ) = 1 2 ∗ ( q ^ − y ^ ) 2 L(w) =\frac{1}{2}*(\hat{q}-\hat{y})^2 L(w)=21∗(q^−y^)2减小。
- 训练过程:一大堆公式
3.Q learning
-
表格法,记为 Q ~ \tilde{Q} Q~

-
收集训练数据e–greedy(也称为行为策略)

-
经验回放更新表格 Q ~ \tilde{Q} Q~


4. 同策略 (On-policy) 与异策略 (Off-policy)
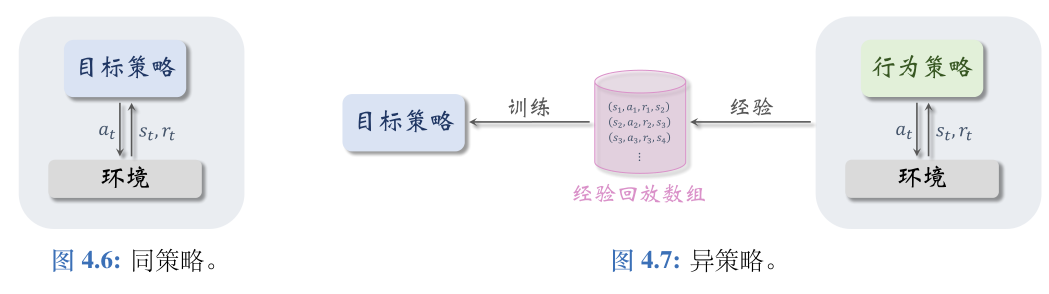
首先介绍行为策略和目标策略:
- 行为策略:作用是收集经验(experience),即观测的状态、动作、奖励。最常用的行为策略是 ϵ-greedy
- 目标策略:强化学习的目的是就是得到一个策略函数,用这个策略函数来控制智能体。这个策略函
数就叫做目标策略。 - 本章的 Q 学习算法可以用任意的行为策略收集
(
s
t
,
a
t
,
r
t
,
s
t
+
1
)
(s t ,a t ,r t ,s_{t+1 })
(st,at,rt,st+1) 这样的四元组,然后拿它们训
练目标策略,即 DQN。
同策略 与 异策略
- 同策略是指用相同的行为策略和目标策略。
- 异策略是指用不同的行为策略和目标策略,本章的 DQN属于异策略。

二、 SARSA 算法
Q 学习的目的是学习最优动作价值函数 Q ⋆ 。SARSA 的目的是学习动作价值函数
Q
π
(
s
,
a
)
Q _π (s,a)
Qπ(s,a).现在
Q
π
Q _π
Qπ通常被用于评价策略的好坏,而非用于控制智能体.

1. 表格法的SARSA
SARSA 算法的目标是学到表格 q,作为动作价值函数 Q π 的近似。
2. 神经网络形式的SARSA
用一个神经网络
q
(
s
,
a
;
w
)
q(s,a;\bf{w})
q(s,a;w)来近似
Q
π
(
s
,
a
)
Q_π (s,a)
Qπ(s,a),神经网络
q
(
s
,
a
;
w
)
q(s,a;\bf{w})
q(s,a;w)被称为价值网络(value network)。首先随机初始化 w,然后用 SARSA 算法更新 w。
三、价值学习高级技巧
1.经验回放
- 经验回放的一个好处在于打破序列的相关性。
- 经验回放的另一个好处是重复利用收集到的经验,而不是用一次就丢弃,这样可以用更少的样本数量达到同样的表现。
注意:
- 经验回放数组里的数据全都是用行为策略(behavior policy)控制智能体收集到的。在收集经验同时,我们也在不断地改进策略。策略的变化导致收集经验时用的行为策略是过时的策略,不同于当前我们想要更新的策略——即目标策略(target policy)。我们真正想要学的目标策略不同于过时的行为策略。
- 比如 Q 学习、确定策略梯度 (DPG) 都属于异策略。由于它们允许行为策略不同于目标策略,过时的行为策略收集到的经验可以被重复利用。经验回放适用于异策略。
- 比如 SARSA、REINFORCE、A2C 都属于同策略。它们要求经验必须是当前的目标策略收集到的,而不能使用过时的经验。经验回放不适用于同策略。
优先经验回放:
- 优先经验回放给每个四元组一个权重,然后根据权重做非均匀随机抽样。如果 DQN 对 ( s j , a j ) (s j ,a j ) (sj,aj)的价值判断不准确,即 Q ( s j , a j ; w ) Q(s j ,a j ;w) Q(sj,aj;w) 离 Q ⋆ ( s j , a j ) Q ⋆ (s j ,a j ) Q⋆(sj,aj) 较远,则四元组 ( s j , a j , r j , s j + 1 ) (s j ,a j ,r j ,s j+1 ) (sj,aj,rj,sj+1) 应当有较高的权重。
2.高估问题及解决方法
用 Q 学习训练出的 DQN 会高估真实的价值,而且高估通常是非均匀的。Q 学习产生高估的原因有两个:
- 第一,自举导致偏差的传播;
- 第二,最大化导致 TD 目标高估真实价值。
(1)目标网络
想要切断自举,可以用另一个神经网络计算 TD 目标,而不是用 DQN 自己计算 TD 目标。另一个神经网络被称作目标网络(target network)。把目标网络记作:
Q
(
s
,
a
;
w
−
)
Q(s,a;w^-)
Q(s,a;w−)
它的神经网络结构与 DQN 完全相同,但是参数
w
−
w^-
w−不同于 w。

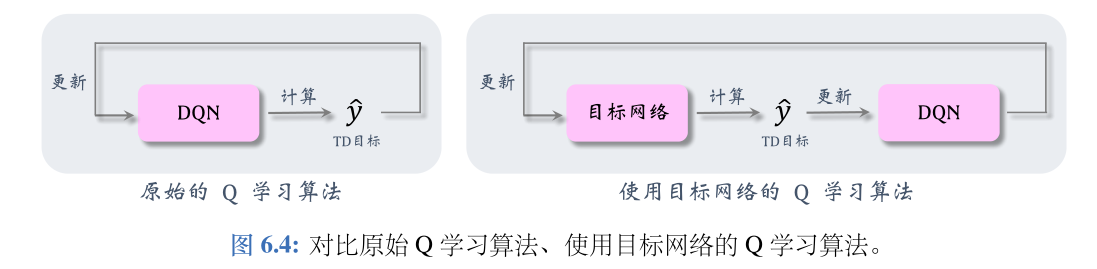
改用目标网络计算
y
^
\hat{y}
y^,避免了用DQN的估计更新DQN自己,降低自举造成的危害。然而这种方法不能完全避免自举,因为目标网络的参数仍然与DQN相关。
(2)双Q学习算法
在 Q 学习算法中使用目标网络,可以缓解自举造成的偏差,但是无助于缓解最大化造成的高估。DDQN在目标网络的基础上做改进,缓解最大化造成的高估。
注:
- 双 Q 学习(即所谓的 DDQN)只是一种 TD 算法而已,它可以把 DQN 训练得更好。
- 双 Q 学习并没有用区别于 DQN 的模型。本节中的模型只有一个,就是 DQN。
- 我们讨论的只是训练 DQN 的三种 TD 算法:原始的 Q 学习、用目标网络的 Q 学习、双 Q 学习。
介绍DDQN:

梯度更新:

注:如果使用 SARSA 算法(比如在 actor-critic 中),自举的问题依然存在,但是不存在最大化造成高估这一问题。对于 SARSA,只需要解决自举问题,所以应当将目标网络应用到 SARSA。
3.对决网络
对决网络与 DQN 一样,都是对最优动作价值函数 Q ⋆ 的近似;两者的唯一区别在于神经网络结构。
4.噪声网络
噪声网络是一种特殊的神经网络结构,神经网络中的参数带有随机噪声。噪声网络可以用于 DQN 等多种深度强化学习模型。噪声网络中的噪声可以鼓励探索,让智能体尝试不同的动作,这有利于学到更好的策略。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









