







一、PPO算法
1. actor网络
Actor 网络输出在给定状态 s t s_t st下采取每个动作的概率分布,通常使用一个神经网络表示: [ π θ ( a t ∣ s t ) ] [ \pi_\theta(a_t | s_t) ] [πθ(at∣st)].PPO 迭代地更新这个 policy,以改进策略并提高性能。
2. Critic网络
[
V
ϕ
(
s
t
)
]
[ V_\phi(s_t) ]
[Vϕ(st)]用于估计状态的值函数。Critic 网络的目标是学习一个准确估计的状态值函数,以便计算优势函数(Advantage Function)。这个 value 网络帮助计算 advantage(优势),即在某个状态下执行某个动作相对于平均水平的优越性。

二、DDPG算法
1. actor网络
DDPG 使用一个 actor 网络 [ μ θ ( s t ) ] [ \mu_\theta(s_t) ] [μθ(st)],其输出是在给定状态下采取的动作。与 PPO 不同,DDPG 的输出是连续的动作,而不是动作概率分布。
2. Critic网络
DDPG 有一个 critic 网络 [ Q ϕ ( s t , a t ) ] [ Q_\phi(s_t, a_t) ] [Qϕ(st,at)],用于估计在给定状态和动作下的 Q 值(动作的质量)。这个 Q 值用于计算 policy gradient,以更新 actor 网络。
Critic 网络的训练目标是最小化 Q 值的均方误差,以使其能够准确估计累积奖励。

三、比较
- 更新目标:PPO 通过迭代更新 policy 来提高性能,而 DDPG 则使用 critic 网络的 Q 值来计算 policy gradient,并更新 actor 网络。
四、Model-based and Model-free
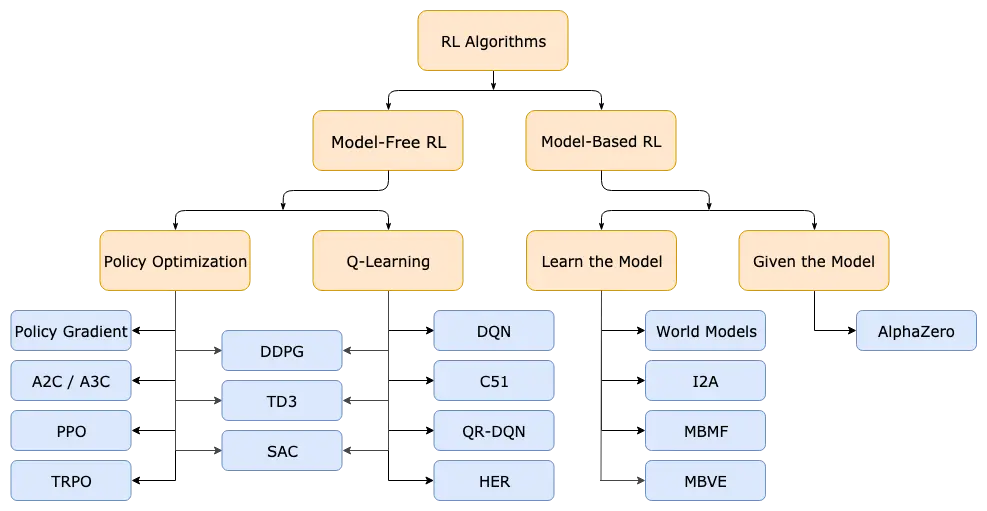
关于到底policy iteration和value iteration哪个好的问题。可能针对不同的问题可以有不同的解。
Deepmind开发的AlphaGo,下棋可以大量生成随机博弈的样本,所以更适合value iteration;但OpenAI是马斯克赞助的,可希望解决实际问题而不是打游戏,实际问题的样本当然是比较昂贵的,比如自动驾驶,要获得真实数据需要开车实地去跑,因此样本很珍贵,这样更适合用policy iteration。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









