




文章目录
0、先了解最基础的:什么是bit(位)、Byte(字节)
1bit(位)、1字节(Byte)和8位(8bits)是数据存储和传输的基本单位,它们的定义和关系如下:
1bit(比特、位)
比特和位: 因中文翻译习惯差异,可能误认为二者不同,实际是同一单位的不同表达
定义: 计算机中最小的数据单位,表示一个二进制状态,只能是 0 或 1。
用途: 表示二进制编码的最小单元;
示例: 用 1bit 表示灯泡的开关(0=关,1=开);网络带宽的单位是 bit/s(如 100Mbps 表示每秒传输 1 亿个二进制位)。
1字节(1 Byte)
定义: 由 8 个二进制位(8bits) 组成,是计算机存储的基本单位。
用途: 存储一个英文字符(ASCII 编码);内存和硬盘容量以字节为单位(如 1GB = 10^9 Bytes);文件大小的基本计量单位。
示例: 字符 ‘A’ 的 ASCII 码是 01000001,占用 1 字节;一张 1MB 的图片占用约 100 万字节的存储空间。
bit与byte的关系
换算公式:
1 Byte = 8bits
位和比特是同一个概念,二者均指计算机中最小的二进制数据单元。
1、拿到一个大模型到底需要什么样配置才能跑起来这个模型?
模型参数量: 模型名称带70B、14B、32B等字眼,这些就是表示模型参数的个数, 反映出模型大小, b代表英文单词“billion”的意思, 也就是10亿. 所以70B就是700亿个参数左右, 14B就是140亿个参数左右, 32B就是320亿个参数左右. 在大模型以前的时代, 也有一些比较小模型,单位一般都是M(百万)为计算单位, LLM出现之后, 基本模型参数数量基本是以亿为基本单位.
参数精度: 影响模型占用显存大小,除了参数量, 还有参数精度。所谓参数精度,就是参数的数据类型. 神经网络中的参数一般都是用具体数字表示, 参数的数据类型都是浮点数, 常见浮点数的精度类型有以下几种:
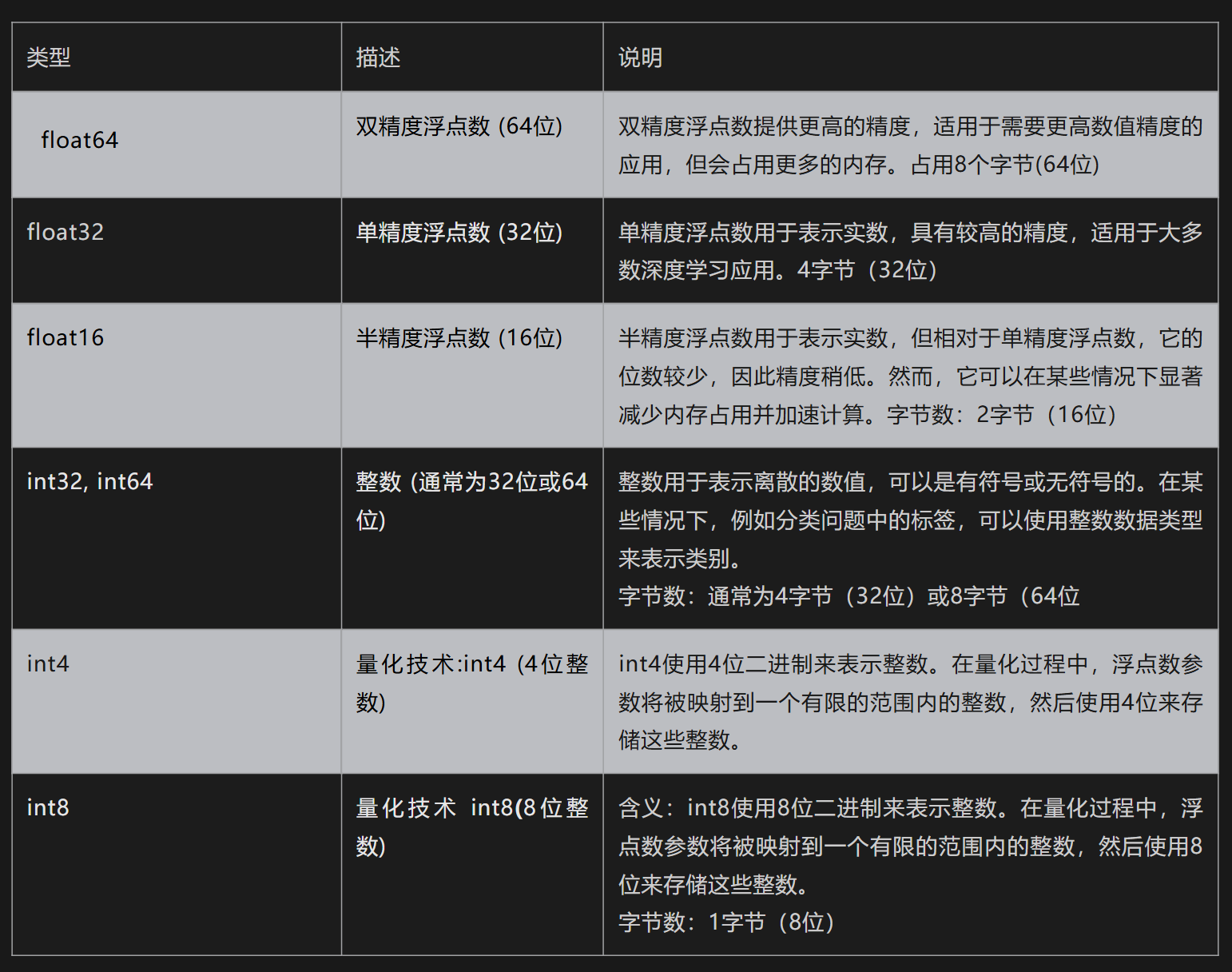
模型参数精度的选择往往是一种权衡。
使用更高精度的数据类型可以提供更高的数值精度,但会占用更多的内存并可能导致计算速度变慢。
相反,使用较低精度的数据类型可以节省内存并加速计算,但可能会导致数值精度损失.
有了参数个数和每个参数的数据类型, 我们就可以开始估算GPU显存大小, 但是推理和训练又不太一样. 推理一般相对训练需要的资源要少, 接下来我们分为2大块内容介绍一下,在推理和训练分别需要的资源是多少?
2、推理显存组成
1)模型权重: 主要由模型的参数个数 × 参数的数据类型占用字节数
2) 输入数据大小: 数据维度和batchsize(批次大小), 所以现在大模型api一般都用输入token和输出token进行收费
3) 推理中间结果:在模型的推理过程中,可能会产生一些中间计算结果,这些中间结果也会占用一定的显存。
3、训练显存组成
1)模型权重: 主要由模型的参数个数 × 参数的数据类型占用字节数。
2) 梯度 : 计算梯度用于更新模型的参数值, 梯度数量与模型参数是相同。
-
优化器参数:一般优化器需要保存一些参数状态,以便更新调整,不同的优化器占用的显存大小是不一样的,比如SGD和参数数量是一样的, 而AdamW是参数的2倍 -
输入数据:数据维度和batchsize(批次大小) -
训练中间结果:在模型的训练前向传播和后向传播过程中,可能会产生一些中间计算结果,这些中间结果也会占用一定的显存。
4、估算LLama3-8B
假设: 参数精度是float32,那就是一个参数使用32位存储的,1个字节=8位,因此使用32位存储的一个参数float32,占用4个字节:
1)模型参数
首先知道:1GB = 1024MB =
1024
2
1024^2
10242 KB =
1024
3
1024^3
10243 B =
1024
3
∗
8
1024^3*8
10243∗8bit
分子:80亿参数* 每个参数是4字节
———————————————— = 29.8G
分母:
1024
∗
1024
∗
1024
1024 * 1024 * 1024
1024∗1024∗1024
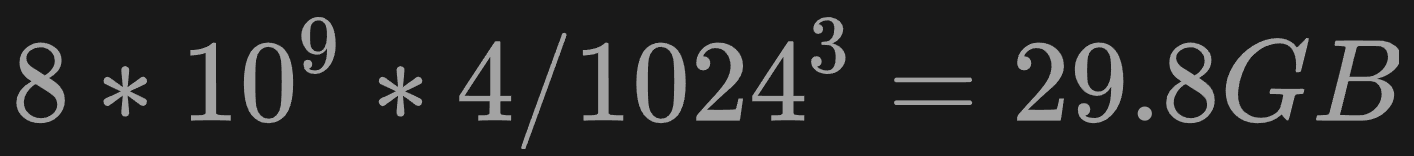
如果显存不够,可以用FP16精度,或者更低,一般都是2倍关系
2)梯度大小
一般和模型一样的大小29.8GB
3)优化器参数
以Adamw 为例优化器参数是模型参数的2倍, 29.8*2GB
4)中间激活
对于每一层,都会有一些中间的激活值。这些激活值的数量通常与模型的宽度和输入数据的大小有关。假设每层的激活需X个浮点数,那么激活的总大小为:X*4字节
5) 输入数据的激活大小
假设批次大小为B, BX4字节,
推理显存: 所以如果是推理的话基本是29.8GB+中间激活+输入数据激活大小即可, 差不多在30GB左右。
训练显存: 但是如果训练的话, 那就**4倍(120G)**以上.
5、总结
上面所说的推理大小也是不考虑用户并发的情况,如果考虑并发的情况永不止这些. 由于训练所需要的资源是巨大,现在为了让普通人也能训练大模型, 行业内已经出现一些相关技术,比如上面所说量化,如果使用量化int8,基本是上面计算的1/4左右, 模型切分、混合精度计算、微调框架等等.
有人说,那每一次我要估算资源,都要充分了解模型结构,然后再计算, 当然不用了,现在HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator, 有在线版和官方版本,可以帮大家快速计算出来, 即使有工具,我们也要知道其中原理, 这样我们才能知其然知其所以然也.
模型参数和显存占用的关系
6、另一种分析方法
首先,搞清楚这么几个概念。
-
显存:1GB=1024M=(10241024)KB=(10241024*1024)字节(1个字节=8比特)≈10^9字节;
-
参数量:参数的个数,1B(B代表billion,也就是10亿,也就是10^9);
-
精度:全精度(fp32,32比特,4个字节);半精度(fp16,16比特,2个字节);
因此,1B-fp32参数量的模型全精度所占显存:1B4/10^9=4G
1B-fp16参数量的模型全精度所占显存:1B2 /10^9=2G
计算的核心:将大模型的参数量换算成字节,字节是参数量与存储之间的桥梁
7、参考
参考:
1、【小白入门篇6】常识|怎么计算模型需要的资源
2、百度部署的deepseek帮助



















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











