







目录
2.2 将输出文件保存为可供YUVViewer观看的YUV文件
2.3 以txt文件输出所有的量化矩阵和所有的HUFFMAN码表
一、JPEG文件格式
1.1 JPEG概述
JPEG(Joint Photographic Experts Group)是JPEG标准的产物,该标准由国际标准化组织(ISO)制订,是面向连续色调静止图像的一种压缩标准。JPEG格式是最常用的图像文件格式,后缀名为.jpg或.jpeg。
JPEG规定了4种运行模式,以满足不同需要,分别是:
- 基于DPCM的无损编码模式:压缩比可达2:1
- 基于DCT的有损顺序编码模式:压缩比可达10:1以上
- 基于DCT的递增编码模式
- 基于DCT的分层编码模式
本实验中采用的JPEG文件为基于DCT的有损顺序编码模式。
1.2 Segment
在JPEG文件格式中,不同类型的数据以段(segment)为单位保存在文件中,在不同的JPEG文件中段的多少和长度并不是一定的,一个JPEG文件可以包含多个段。
段的共同特点为:
- 每一个段的前两个字节为段的标识,用来表示段所属的类型。标识的第一个字节为0xFF,第二个依据不同段的类型而不同。
- 每一个段中紧接着段标识的后两个字节为段的长度(除去标识之后的长度)
- 段中的数据都是高位在前低位在后
下面介绍各个段类型
1.2.1 SOI
图像开始,标识为0xFFD8
1.2.2 EOI
图像结束,标识为0xFFD9
1.2.3 APP0
应用程序保留标记0,标识为0xFFE0,包含9个具体字段:
- 数据长度,占2字节,为1~9字段的总长度
- 标识符,占5字节,固定值0x4A46494600,即字符串“JFIF0”
- 版本号,占2字节,一般是0x0102,标识JFIF的版本号1.2
- X和Y的密度单位,占1字节,只有三个值可选:0-无单位、1-点数/英寸、2-点数/厘米
- X方向像素密度,占2字节
- Y方向像素密度,占2字节
- 缩略图水平像素数目,占1字节
- 缩略图垂直像素数目,占1字节
- 缩略图RGB位图
1.2.4 DQT
定义量化表,标识为0xFFDB,包含以下具体字段:
- 数据长度,占2字节
- 量化表,在DQT段中可以重复出现,表示多个量化表,但最多只能出现4次
- 数据长度,占2字节
- 精度及量化表ID,占1字节。高4位为精度,只有两个值可选:0-8位、1-16位。低4位为量化表ID,取值范围为0~3
- 表项,占(64×(精度+1))字节
1.2.5 SOF0
帧图像开始,标识为0xFFC0,包含9个具体字段:
- 数据长度,占2字节
- 精度,占1字节,每个数据样本的位数。通常是8位,一般软件都不支持12位和16位
- 图像高度,占2字节,单位:像素
- 图像宽度,占2字节,单位:像素
- 颜色分量数,占1字节,只有3个数值可选:1-灰度图、3-YCrCb或YIQ、4-CMYK
- 颜色分量信息,颜色分量数×3字节(通常为9字节)
- 颜色分量ID,占1字节
- 水平/垂直采样因子,占1字节。高四位:水平采样因子、低四位:垂直采样因子
- 量化表,占1字节。当前分量使用的量化表的ID
1.2.6 DHT
定义哈夫曼表,标识符为0xFFC4,包含以下字段:
- 数据长度,占2字节
- huffman表,占(数据长度-2)字节,在DHT段中可以重复出现(一般4次),也可以只出现1次
- 表ID和表类型,占1字节
- 高4位:类型,只有两个值可选:0-DC直流、1-AC交流
- 低4位:哈夫曼表ID
- 不同位数的码字数量,占16个字节
- 16个不同位数的码字数量之和
1.2.7 SOS
扫描开始,标识符为0xFFDA,包含以下字段:
- 数据长度,占2字节
- 颜色分量数,占1字节。应该和SOF中的字段5的值相同
- 颜色分量信息
- 颜色分量ID,占1字节
- 直流/交流系数表号,占1字节。
- 高4位:直流分量使用的哈夫曼树编号
- 低4位:交流分量使用的哈夫曼树编号
- 压缩图像数据
- 谱选择开始,占1字节,固定值0x00
- 谱选择结束,占1字节,固定值0x3F
- 谱选择,占1字节,在基本JPEG中总为00
1.3 JPEG文件编码
JPEG编码的过程如图所示:

编码各步骤如下
1.3.1 零偏置(Level Offset)
对于灰度级是2^n的像素,通过减去2^(n-1),将无符号的整数值变成有符号数,使像素的绝对值出现3位10进制的概率大大减少
1.3.2 DCT变换
对每个单独的彩色图像分量,把整个分量图像分成8×8的图像块,并作为二维离散余弦变换DCT的输入。将原本的像素数值进行DCT变换,后续直接对DCT分量进行处理。
1.3.3 量化
对DCT分量进行量化,由于人眼对亮度信号比对色差信号更敏感,因此使用了两种量化表:亮度量化值和色差量化值。
根据人眼的视觉特性(对低频敏感,对高频不太敏感)对低频分量采取较细的量化,对高频分量采取较粗的量化。
如果原始图象中细节丰富,则去掉的数据较多,量化后的系数与量化前差别。反之,细节少的原始图象在压缩时去掉的数据少些。
JPEG提供了两种建议量化表(但现在很少用):

1.3.4 DC系数差分编码
DC直流系数有两个特点:系数的数值比较大,相邻DC系数值变化不大。
根据上述两个特点,JPEG算法使用了差分脉冲调制编码(DPCM)技术,对相邻图像块之间量化DC系数的差值DIFF进行编码:
1.3.5 AC系数之字形扫描
由于经DCT变换后,系数大多数集中在左上角,即低频分量区,因此采用Z字形按频率的高低顺序读出,可以出现很多连零的机会。可以使用游程编码。尤其在最后,如果都是零,给出 EOB (End of Block)即可。
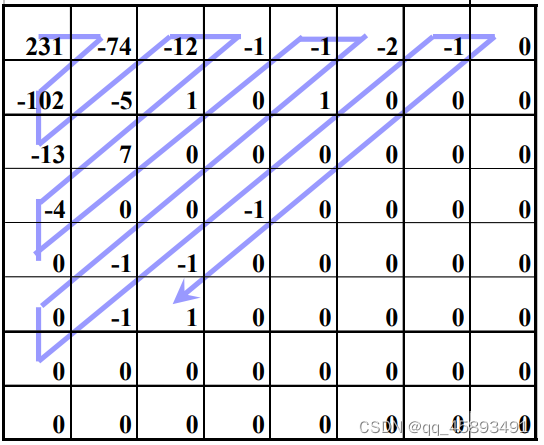
1.3.6 AC系数的游程编码
在JPEG和MPEG编码中规定为:(run,level)
- 表示连续run个0,后面跟值为level的系数
- 如:0,2,0,0,3,0,-4,0,0,0,-6,0,0 ,5,7 表示为(1, 2), (2, 3)
编码
run:最大值15,用4位标识为RRRR
level:类似DC,分成16个类别,用4位标识为SSSS
对(RRRR,SSSS)联合用Huffman编码
对类内索引用定长码编码

1.3 JPEG文件编码
JPEG文件的解码过程与编码过程相反,包括以下步骤:
- 解码Huffman数据、
- 解码DC差值
- 重构量化后的系数
- DCT逆变换
- 丢弃填充的行/列
- 反0偏置
- 对丢失的CbCr分量插值
- 将YCbCr通道数据变为RGB通道数据
二、JPEG文件解析
2.1 实验程序说明
实验程序采用C语言编写,共包含stdint.h、tinyjpeg.h、tinyjpeg-internal.h三个头文件以及tinyjpeg.c、loadjpeg.c、jidctflt.c三个源代码文件。
- stdint.h定义了程序内变量的类型。
- tinyjpeg.h声明了tynyjpeg.c中的函数。
- tinyjpeg-internal.h中定义了jidctflt.c中的函数,同时定义了解码中所用到的结构体如用于存放霍夫曼编码表的huffman_table。
- tinyjpeg.c中定义了解码所用的一些函数
- loadjpeg.c中定义了读取jpeg文件的一些函数,同时定义了程序的主入口函数main()
- jidcflt.c中定义了对数据的一些处理函数
在程序编译完成后会生成jpeg_mindec.exe可执行文件,命令格式如下:
jpeg_mindec.exe [options] <input_filename.jpeg> <format> <output_filename>- 第一个参数[options]为固定值--benchmark,可有可无,加上该参数时将对这幅图像解码1000次,验证解码器效果
- 第二个参数<input_filename.jpeg>为输入的jpeg文件
- 第三个参数<format>为转换格式,有yuv420p、rgb24、bgr24、gray四种模式可选
- 第四个参数<output_filename>为输出文件名
实验用测试图像test.jpg如下:
输入命令: jpeg_mindec.exe test.jpg yuv420p out
最终输出trace_jpeg.txt及out.U、out.V、out.Y三个通道数据文件
trace_jpeg.txt记录了程序运行过程中创建的变量数据,如霍夫曼表等。

out.U、out.V、out.Y三个文件分别存放了以4:2:0取样格式取样得到的三个通道数据。
2.2 将输出文件保存为可供YUVViewer观看的YUV文件
在loadjpeg.c文件中定义了函数write_yuv()输出.Y、.U和.V三个通道的数据文件,仅需将这三个文件的数据保存在一个文件中即可得到可供YUVViewer观看的YUV文件。
修改write_yuv()函数如下:
static void write_yuv(const char *filename, int width, int height, unsigned char **components) {
FILE *F;
char temp[1024];
snprintf(temp, 1024, "%s.Y", filename);
F = fopen(temp, "wb");
fwrite(components[0], width, height, F);
fclose(F);
snprintf(temp, 1024, "%s.U", filename);
F = fopen(temp, "wb");
fwrite(components[1], width * height / 4, 1, F);
fclose(F);
snprintf(temp, 1024, "%s.V", filename);
F = fopen(temp, "wb");
fwrite(components[2], width * height / 4, 1, F);
fclose(F);
/*将三个通道的数据均保存在yuv文件中*/
snprintf(temp, 1024, "%s.yuv", filename);
F = fopen(temp, "wb+");
fwrite(components[0], width, height, F);
fwrite(components[1], width, height/4, F);
fwrite(components[2], width, height/4, F);
fclose(F);
}而后以yuv420p模式运行程序,即可生成.yuv文件。

2.3 以txt文件输出所有的量化矩阵和所有的HUFFMAN码表
2.3.1 输出量化矩阵
在tinyjpeg.c文件中定义了函数build_quantization_table()来建立量化表,修改函数内容即可在运行程序的同时输出量化矩阵
static void build_quantization_table(float *qtable, const unsigned char *ref_table) {
int i, j;
static const double aanscalefactor[8] = {
1.0, 1.387039845, 1.306562965, 1.175875602,
1.0, 0.785694958, 0.541196100, 0.275899379
};
const unsigned char *zz = zigzag;
FILE* QTfile = fopen("QTfile.txt","a");//打开txt文档
fprintf(QTfile,"量化矩阵:\n");
for (i = 0; i < 8; i++) {
for (j = 0; j < 8; j++) {
*qtable++ = ref_table[*zz++] * aanscalefactor[i] * aanscalefactor[j];
fprintf(QTfile, "%d\t", ref_table[*zz]);//将量化矩阵输出到txt文档中
}
fprintf(QTfile,"\n");//每输出一行后换行
}
}运行程序,生成QTfile.txt文件,量化矩阵如下:

2.3.2 输出HUFFMAN码表
在trace_jpeg.txt文件中会输出霍夫曼码表,通过在头文件中宏定义TRACE的值,而后在源代码文件中多处设有判定TRACE的语句,若预先宏定义其值为1,则会编译相关语句,例如在tinyjpeg.c文件中的build_huffman_table()函数中就有:
#if TRACE
fprintf(p_trace, "val=%2.2x code=%8.8x codesize=%2.2d\n", val, code, code_size);
fflush(p_trace);
#endif上述语句块是用于将霍夫曼码表输出至trace_jpeg.txt文件,为便于查看,让霍夫曼码表输出到另一个文档HTfile.txt中。
修改build_huffman_table()和parse_DHT()函数即可实现将霍夫曼码表输出在指定txt文档中。
修改后的build_huffman_table()函数如下:
static void build_huffman_table(const unsigned char *bits, const unsigned char *vals, struct huffman_table *table) {
unsigned int i, j, code, code_size, val, nbits;
unsigned char huffsize[HUFFMAN_BITS_SIZE + 1], *hz;
unsigned int huffcode[HUFFMAN_BITS_SIZE + 1], *hc;
int next_free_entry;
/*
* Build a temp array
* huffsize[X] => numbers of bits to write vals[X]
*/
hz = huffsize;
for (i = 1; i <= 16; i++) {
for (j = 1; j <= bits[i]; j++)
*hz++ = i;
}
*hz = 0;
memset(table->lookup, 0xff, sizeof(table->lookup));
for (i = 0; i < (16 - HUFFMAN_HASH_NBITS); i++)
table->slowtable[i][0] = 0;
/* Build a temp array
* huffcode[X] => code used to write vals[X]
*/
code = 0;
hc = huffcode;
hz = huffsize;
nbits = *hz;
while (*hz) {
while (*hz == nbits) {
*hc++ = code++;
hz++;
}
code <<= 1;
nbits++;
}
/*
* Build the lookup table, and the slowtable if needed.
*/
next_free_entry = -1;
FILE *HTfile = fopen("HTfile.txt", "a");//打开txt文档
for (i = 0; huffsize[i]; i++) {
val = vals[i];
code = huffcode[i];
code_size = huffsize[i];
fprintf(HTfile, "val=%2.2x code=%8.8x codesize=%2.2d\n", val, code, code_size);//输出霍夫曼码表至txt文档
#if TRACE
fprintf(p_trace, "val=%2.2x code=%8.8x codesize=%2.2d\n", val, code, code_size);
fflush(p_trace);
#endif
table->code_size[val] = code_size;
if (code_size <= HUFFMAN_HASH_NBITS) {
/*
* Good: val can be put in the lookup table, so fill all value of this
* column with value val
*/
int repeat = 1UL << (HUFFMAN_HASH_NBITS - code_size);
code <<= HUFFMAN_HASH_NBITS - code_size;
while (repeat--)
table->lookup[code++] = val;
} else {
/* Perhaps sorting the array will be an optimization */
uint16_t *slowtable = table->slowtable[code_size - HUFFMAN_HASH_NBITS - 1];
while (slowtable[0])
slowtable += 2;
slowtable[0] = code;
slowtable[1] = val;
slowtable[2] = 0;
/* TODO: NEED TO CHECK FOR AN OVERFLOW OF THE TABLE */
}
}
fclose(HTfile);
}
修改后的parse_DHT()函数如下:
static int parse_DHT(struct jdec_private *priv, const unsigned char *stream) {
unsigned int count, i;
unsigned char huff_bits[17];
int length, index;
length = be16_to_cpu(stream) - 2;
stream += 2; /* Skip length */
#if TRACE
fprintf(p_trace, "> DHT marker (length=%d)\n", length);
fflush(p_trace);
#endif
FILE *HTfile = fopen("HTfile.txt", "a");//打开txt文档
fprintf(HTfile, "> DHT marker (length=%d)\n", length);
fclose(HTfile);
while (length > 0) {
index = *stream++;
/* We need to calculate the number of bytes 'vals' will takes */
huff_bits[0] = 0;
count = 0;
for (i = 1; i < 17; i++) {
huff_bits[i] = *stream++;
count += huff_bits[i];
}
#if SANITY_CHECK
if (count >= HUFFMAN_BITS_SIZE)
snprintf(error_string, sizeof(error_string), "No more than %d bytes is allowed to describe a huffman table",
HUFFMAN_BITS_SIZE);
if ((index & 0xf) >= HUFFMAN_TABLES)
snprintf(error_string, sizeof(error_string), "No more than %d Huffman tables is supported (got %d)\n",
HUFFMAN_TABLES, index & 0xf);
#if TRACE
fprintf(p_trace, "Huffman table %s[%d] length=%d\n", (index & 0xf0) ? "AC" : "DC", index & 0xf, count);
fflush(p_trace);
#endif
#endif
HTfile = fopen("HTfile.txt", "a");//打开txt文档
fprintf(HTfile, "Huffman table %s[%d] length=%d\n", (index & 0xf0) ? "AC" : "DC", index & 0xf,
count);//输出霍夫曼码表信息
fclose(HTfile);
if (index & 0xf0)
build_huffman_table(huff_bits, stream, &priv->HTAC[index & 0xf]);
else
build_huffman_table(huff_bits, stream, &priv->HTDC[index & 0xf]);
length -= 1;
length -= 16;
length -= count;
stream += count;
}
#if TRACE
fprintf(p_trace, "< DHT marker\n");
fflush(p_trace);
#endif
HTfile = fopen("HTfile.txt", "a");//打开txt文档
fprintf(HTfile, "> DHT marker (length=%d)\n", length);
fclose(HTfile);
return 0;
}运行程序,生成HTfile.txt,输出霍夫曼码表如下:

2.4 输出DC图像和AC图像并统计其概率分布
解码函数为tinyjpeg.c中的tinyjpeg_decode(),因此修改其中内容如下:
/....../
resync(priv);
/* Don't forget to that block can be either 8 or 16 lines */
bytes_per_blocklines[0] *= ystride_by_mcu;
bytes_per_blocklines[1] *= ystride_by_mcu;
bytes_per_blocklines[2] *= ystride_by_mcu;
bytes_per_mcu[0] *= xstride_by_mcu / 8;
bytes_per_mcu[1] *= xstride_by_mcu / 8;
bytes_per_mcu[2] *= xstride_by_mcu / 8;
/*修改部分*/
int file_length = 0;
FILE *DC_pic = fopen("DC.yuv", "wb+");
FILE *AC_pic = fopen("AC.yuv", "wb+");
/*修改部分结束*/
/* Just the decode the image by macroblock (size is 8x8, 8x16, or 16x16) */
for (y = 0; y < priv->height / ystride_by_mcu; y++) {
//trace("Decoding row %d\n", y);
priv->plane[0] = priv->components[0] + (y * bytes_per_blocklines[0]);
priv->plane[1] = priv->components[1] + (y * bytes_per_blocklines[1]);
priv->plane[2] = priv->components[2] + (y * bytes_per_blocklines[2]);
for (x = 0; x < priv->width; x += xstride_by_mcu) {
decode_MCU(priv);
/*修改部分开始*/
unsigned char dc;
unsigned char ac;
dc = (unsigned char) ((priv->component_infos->DCT[0] + 512) / 4);//DC系数的取值范围为[-512,511],需要将其转换为[0,255]的范围
ac = (unsigned char) (priv->component_infos->DCT[1] + 128);//AC系数的取值范围为[-128,127],将其转换为[0,255]的范围
fwrite(&ac, 1, 1, AC_pic);//写入分量
file_length++;//像素数+1
/*修改部分结束*/
convert_to_pixfmt(priv);
priv->plane[0] += bytes_per_mcu[0];
priv->plane[1] += bytes_per_mcu[1];
priv->plane[2] += bytes_per_mcu[2];
if (priv->restarts_to_go > 0) {
priv->restarts_to_go--;
if (priv->restarts_to_go == 0) {
priv->stream -= (priv->nbits_in_reservoir / 8);
resync(priv);
if (find_next_rst_marker(priv) < 0)
return -1;
}
}
}
}
/*修改部分开始*/
unsigned char uv = 128;
for (int i = 0; i < file_length / 4 * 2; i++) {
fwrite(&uv, 1, 1, DC_pic);
fwrite(&uv, 1, 1, AC_pic);//写入UV通道数据,黑白图像全置为128
}
fclose(DC_pic);//关闭图像文件
fclose(AC_pic);
/*修改部分结束*/
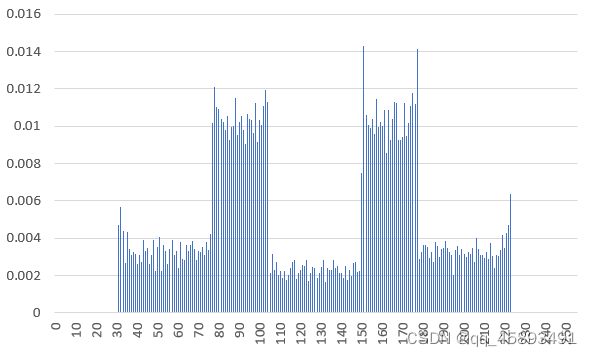
/....../而后运行程序将同时输出DC系数图像DC.yuv和AC系数图像AC.yuv。其中AC图像中输出的AC系数选取为第一个AC系数。


注意由于只输出8x8块中的一个系数,因此图像高宽都会变为原来的1/8,原图像为1024x1024的大小,因此输出图像大小只有128x128。
DC和AC图像对应的概率分布如下:















 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









