







文章目录
吴恩达 week5
一、合理分配
通常,深度学习有很多超参数,我们不可能一下子找到最优解,都需要不断迭代。这就需要我们优化我们的代码提高速度
通常来说,合理分配训练,测试,开发数据集能够使我们迭代的效率变高。
对于之前的深度学习
一般指分为训练集和开发集也称为训练集和测试集
传统的比例为7:3 或6:2:2
但现在数据变多了,测试集和开发集可能连10%都不到。
1、各自作用
训练数据集 顾名思义 就是训练一个模型
为了防止过度拟合训练集
开发集:测试哪个模型并确定哪个模型或者算法更好
所以只有有足够的数据 可以区分哪个模型(算法)好就可以,不需要太多。
又为了防止过度拟合开发集
测试数据集::对训练好的分类器,给出可信度较高的评估。
它是完全不偏的评估。
2、训练与测试数据(开发)集分布不匹配的问题
随着数据越来越多,可能会出现分布不匹配的问题。
比如 如果一个网页运用爬虫的方式从别的网站获取猫的图片作为训练集
而把用户上传的图像作为测试集。
网站的图片一般都很清晰,而用户上传的图片可能是随便拍摄的,可能会很模糊。
就导致不匹配的问题,而测试数据集可以衡量一个算法的好坏。
当训练集与开发或测试数据集分布匹配时,我们的迭代的效率也会提高些。
二、偏差与方差
1.什么是偏差与方差? Bias/Variance
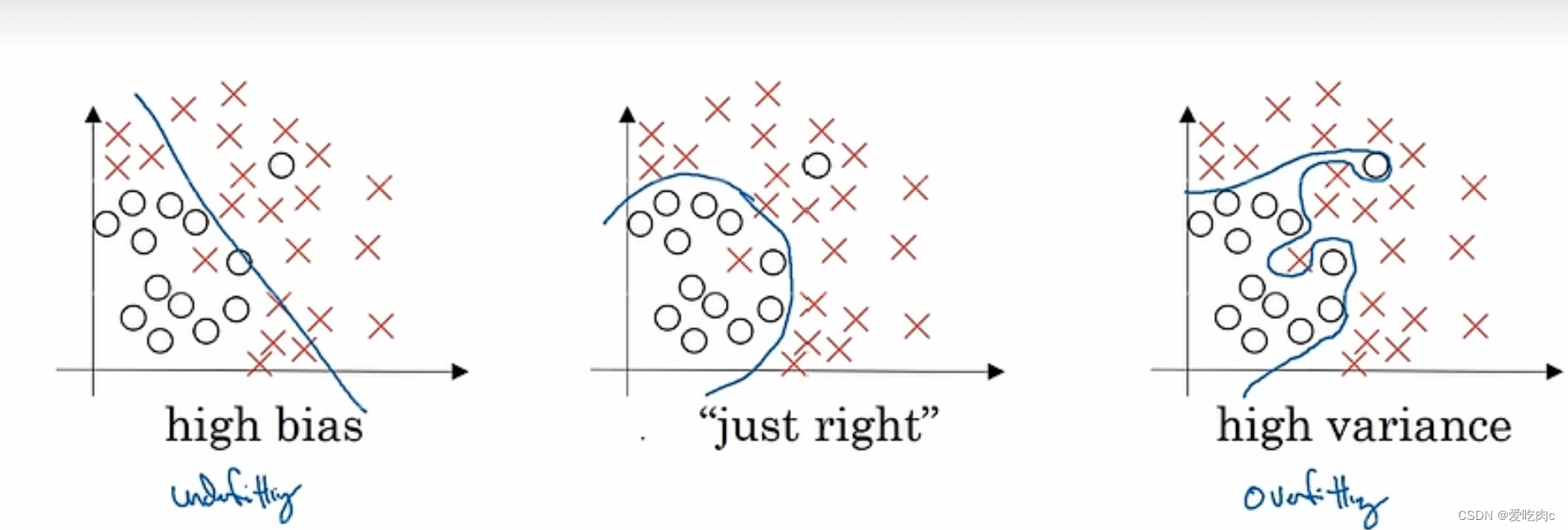
高偏差 对应着欠拟合 under fitting
高方差 对应着过拟合 outfitting

上副图片 对于高偏差和高方差的判断
都是基于base error/optinal err 为0%的情况下。
高偏差和高方差是什么样呢?
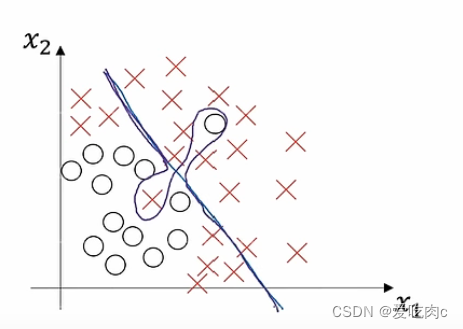
一边不能很好的分割数据 一边又对某些点过度拟合
2.Basic recipe for deep learing
深度学习的基本配方如下:
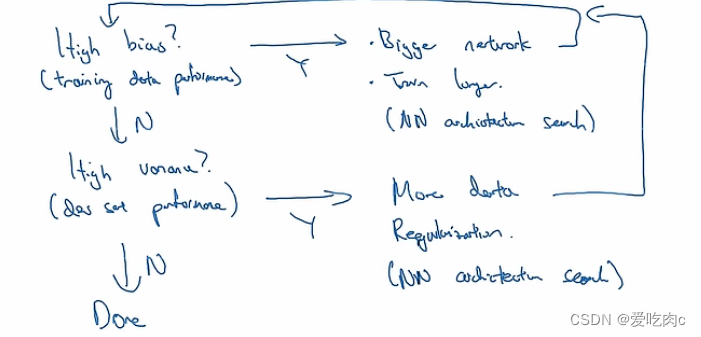
我们要先看自己的模型是否有高偏差 之后通过扩大网络规模 增加训练时间或者运用其他神经网络结构等来减小偏差
之后我们看自己的模型在测试数据上是否有高方差 之后通过寻找更多数据
或者正则化以及其他方式来减小方差
之后再返回第一步。
对于现在的深度学习来说,如果我们既能训练一个更大的模型又能找到更多的数据来测试,我们可以在减小方差的情况下不会很大程度的影响偏差,反之亦然。
三、正则化 Regularzation
1、正则化形式
如果我们发现我们的数据出现了过拟合的现象,首先就会采用正则化的方式来降低过拟合的程度。
1、L1,L2正则化
逻辑回归中的正则化
逻辑回归没有隐藏层,W是(nx,1)

对于神经网络的正则化:
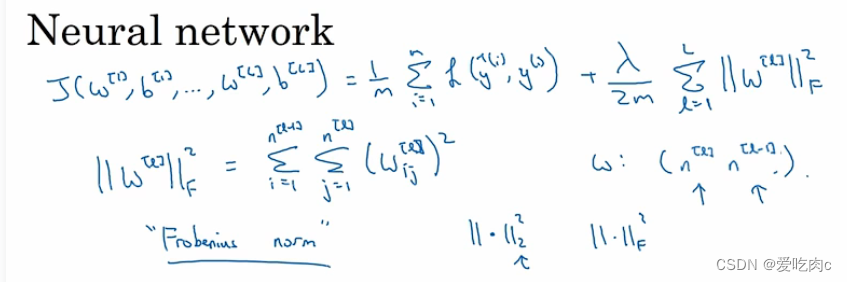
因为有了中间层,所以有W1,W2…
损失函数中我们需要把所有的w都求平方 之后求和
我们也把神经网络这种L2正则化称为Frobenius norm
因为我们的损失函数改变了,所以在反向传播时
dW的值也会发生改变

也称权重衰减 因为多减去了一个值。
2、为什么正则化能防止过拟合
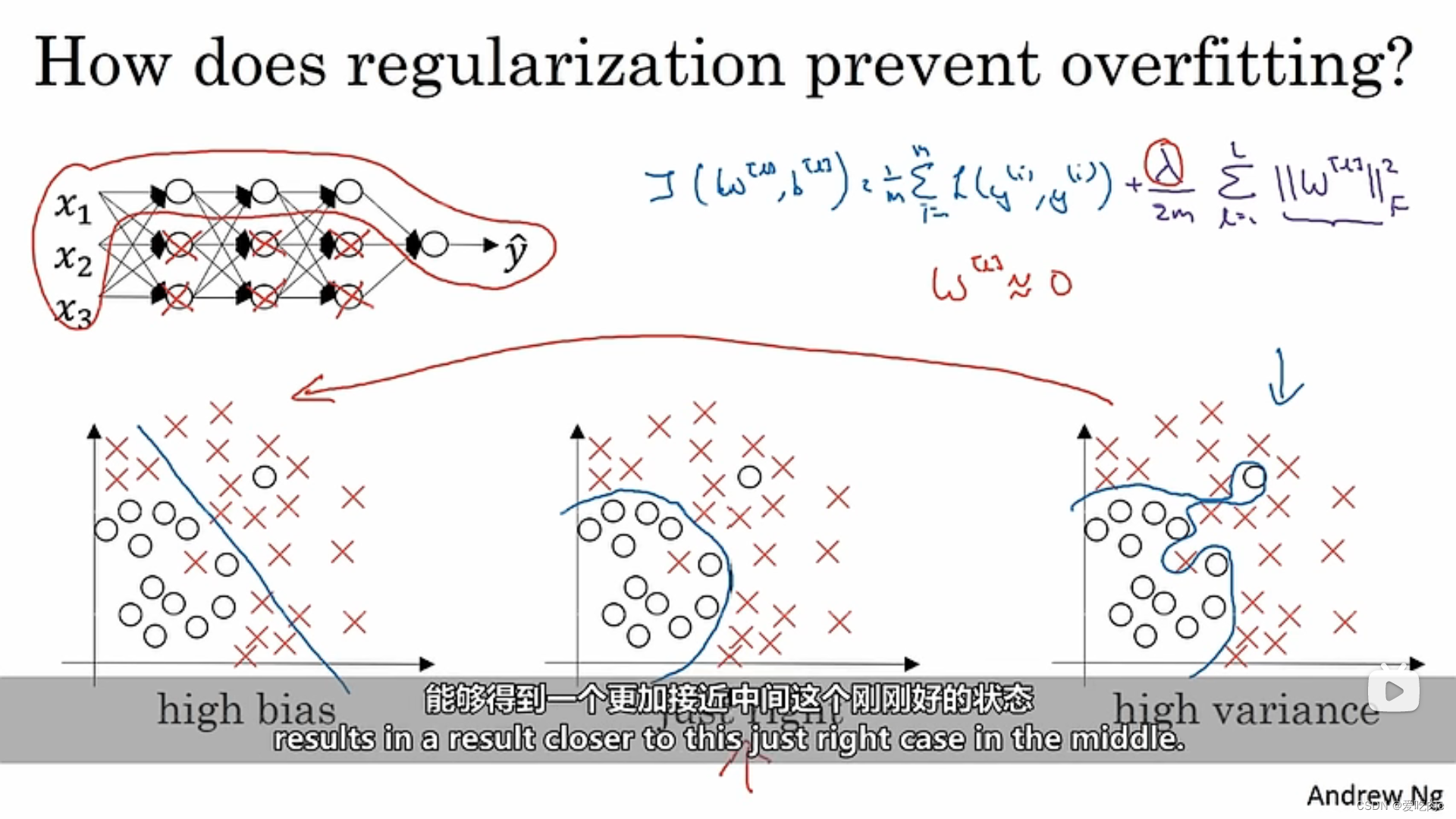
当labda很大时,我们要减小损失函数,就会使W很小。
我们可以简单理解为让神经网络中的一些神经节点为0,相当于简化了神经网络,更像一个逻辑回归,此时就可以降低方差,不会过拟合。
但是我们要知道,我们可以取一个合适的labda值,不会那么极端,让w为0,此时就可以取到一个相对较好的边界。

以激活函数为tanh举例,如果w很小,那么z也会变小,此处忽略b的影响,那么就会使用激活函数的线性部分,我们知道,多个线性结合仍然是线性的,会导致最后的结果也很简单,不会发生过拟合。
四、dropout regularization
1、概念
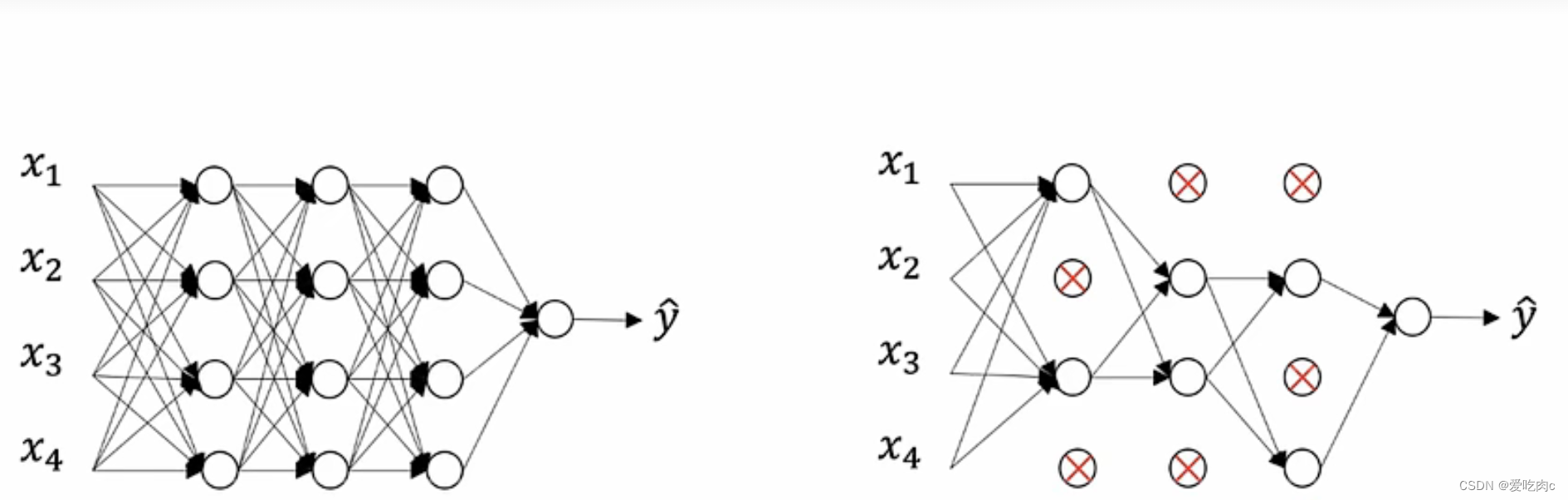
采用随机的编码决定节点的去留。
这样就简化了神经网络防止过拟合
dropout中一个常用的就是"Inverted dropout"

这里假设是在第三层上采用dropout
在python中这样的d3是一个bool矢量,我们可以用type=‘int’ 转换为0,1
最后需要注意将a3/=权重
因为如果我们选取keep.prob为0.8,那就代表有20%的a将被抛弃,则z4的期望也将会减少百分之二十,为了防止z4的期望不变,我们需要除以keep.prob
2、why does dropout work?
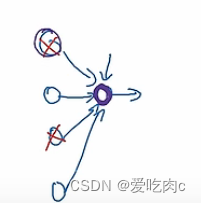
比如这样一个网NN,紫色的点并不会完全依赖于前面四个点中的任何一个,因为采用dropout的方式,任何一个节点都有可能被抛弃,所以NN会给这些节点每个都较小的权重,也就相当于简化了神经网络。
dropout 与L2相似,但又不同
L2的损失函数是固定的,我们可以画出J对迭代次数的变化图。
但是dropout的损失函数是不固定的甚至不能表示出来,每个w都是不固定的,所以如果我们的数据没有出现过拟合,一般都不会使用dropout。
L2的变化小,适应性更广。
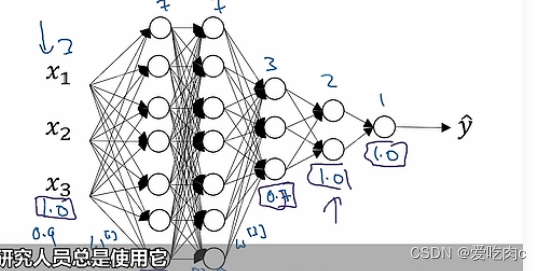
对于dropout,我们可以给不同层不同的keep.prob,如果我们认为某一层会发生过拟合,就可以给这一层的keep.prob设置的小一些。
但是这样会导致超参数的数量变多,不好训练模型。
五、其他的正则化方法
1、data argument
增大数据集可以防止我们的数据出现过拟合的情况。
但是我们一般不容易获得更多的数据。
此时我们可以采取一些其他的方法来数据扩增。
比如把一张图片放大之后截取部分,比如水平翻转等。
2、Early stopping
早终止。
我们一般都会绘制损失函数随着迭代次数增加的变化图。
一般而言随着迭代次数的增多,我们的损失函数会逐渐减小,这时候NN次数多,可能就会出现过拟合的情况。
此时若检测测试数据集的损失函数J可能会逐渐增大。
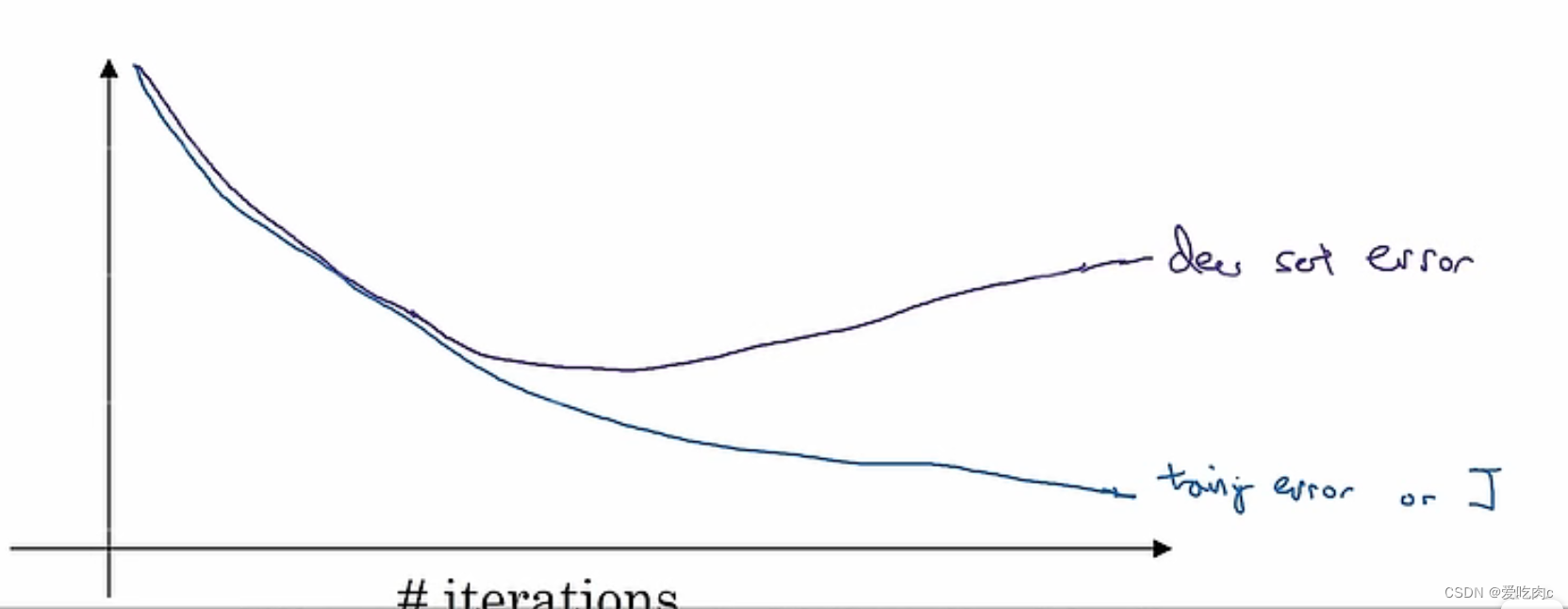
因为此时的模型对训练数据集过拟合,泛化能力变弱。
早终止的缺点
我们一般都会把优化损失函数J与减小方差分开。
但是早终止是让这两件事同时做了,在优化J的同时又害怕出现过拟合的现象,会使我们的计算过程更加复杂。
对于L2正则化,我们需要做的是不断地寻找更好的lambd,来防止过拟合。
对于早终止,我们需要做的是带入一个小w,中值w和大的w即可,来查看对应的损失函数。
**注:**在刚开始,我们一般都会给w初始为一个很小的值,之后随着迭代次数增多,w逐渐增大。
















 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









