







 本文介绍了深度学习的基本概念,包括单个神经元模型、神经元拟合原理、多层神经网络以及隐藏层的作用。重点讨论了激活函数、反向传播、softmax回归和损失函数,并通过实例解释了隐藏层如何解决非线性问题。此外,还提到了过拟合和欠拟合的概念及其解决方案。
本文介绍了深度学习的基本概念,包括单个神经元模型、神经元拟合原理、多层神经网络以及隐藏层的作用。重点讨论了激活函数、反向传播、softmax回归和损失函数,并通过实例解释了隐藏层如何解决非线性问题。此外,还提到了过拟合和欠拟合的概念及其解决方案。
深度学习的基本概念
简单概括是,使用神经网络,进行不断学习训练和修正的过程。训练集就是有答案的习题,神经网络每一次写完作业都会去对答案,如果有偏差,就自动修正参数,谓之迭代,直到最后错误率越接近0越好。
一、单个神经元
数学模型(MP模型)
1943年,心理学家W.S.McCulloch和数理逻辑学家W.Pitts基于神经元的生理特征,建立了单个神经元的数学模型(MP模型)
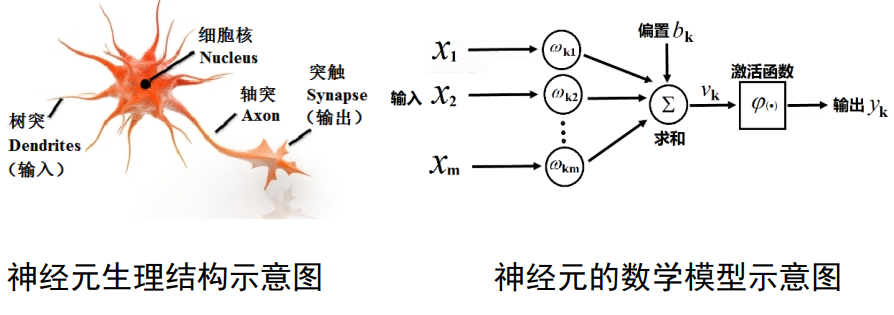
神经元的数学模型推导公式:
y k = φ ( ∑ i = 1 m ω k i x i + b k ) y_k = φ(\sum_{i=1}^mω_{ki}x_{i}+b_k) yk=φ(i=1∑mωkixi+bk)
公式参数:
- x:输入
- ω:权重
- b:偏置(b绝大部分情况下是一个向量,可以类比一下一元一次方程 y = k x + b y=kx+b y=kx+b的 b b b,使数值产生整体的偏移。)
- 激活函数φ:一个非线性函数,目的是将输入进行变化映射,得出输出信号。它模拟大脑电信号,对较小的刺激进行弱化甚至抑制,对较明显的刺激继续传递。
二、神经元的拟合原理
模型每次的学习都是为了调整W和b从而得到一个合适的值,最终由这个值配合运算公式所形成的逻辑就是神经网络模型。这个调整的过程称为拟合。
正向传播
数据是从输入到输出的流向传递过来的。当然,它是在一个假设有合适的w和b的基础上的,才可以实现对现实环境的正确拟合。但是,在实际过程中我们无法得知w和b的值具体是多少才算是正常。于是,我们加入一个训练过程,通过反向误差传递的方法让模型自动来修正,最终得到合适的W和b。
反向传播:
BP(Back Propagation process),BP是在估计权重的时候的必要过程,可被称为BP算法。深度学习的目的就是通过最小化损失函数,来估计神经网络的权重。 在这个过程中,需要用到BP进行反向传播。(损失函数下文会讲)
损失,指神经网络输出结果与实际值的差值(可为均方差等形式的差值)。为了让损失值最小化,我们选择一个损失函数,让这个表达式有最小值,接着通过对其求导的方式,找到最小值时刻的函数切线斜率(也就是梯度),让w和b沿着这个梯度来调整。
至于每次调整多少,我们引入一个叫做 “学习率” 的参数来控制,这样通过不断的迭代,使误差逐步接近最小值,从而达到我们的目标。
通常BP的步骤为:
- 明确损失函数
- 明确参数调整策略
可参考博客:多层神经网络BP算法的推导
激活函数(activation function): (同上文“一个非线性函数,目的是将输入进行变化映射,得出输出信号。它模拟大脑电信号,对较小的刺激进行弱化甚至抑制,对较明显的刺激继续传递。 ”)激活函数(也译作激励函数)的主要作用就是加入非线性因素,以解决线性模型表达能力不足的缺陷,在整个神经网络里起到至关重要的作用。
因为神经网络的数据基础是处处可微的,所以选取的激活函数要保证数据输入与输出也是可微的。在神经网络里常用的函数有Sigmoid、Tanh和Relu等,具体实现自行百度。
处理分类: softmax回归,对一些数据进行多种分类。softmax从字面上来说,可以分成soft和max两个部分。max故名思议就是最大值的意思。softmax的核心在于soft,而soft有软的含义,与之相对的是hard硬。很多场景中需要我们找出数组所有元素中值最大的元素,实质上都是求的hardmax。softmax的含义就在于不再唯一的确定某一个最大值,而是为每个输出分类的结果都赋
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 33万+
33万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









