







第一章 基础
一、初识 Python
1. 新建 Python 项目
① 点击左上角“文件”,再点击“新建项目”;
② 在弹出窗中,填写项目创建的位置;
③ 在 Python 解释器中选择“先前配置好的解释器”,点击“解释器”最右边三个点,在弹出窗中选择下”系统解释器“;
④ 点击”创建“按钮,即可新建一个项目;
⑤ 在左边菜单栏中,右键文件名,在”新建“中选择”Python文件“,填写文件名,即可创建一个 Python 文件进行编程。
2. 常用的快捷键
① ctrl + d:复制当前行代码
② shift + alt +上\下:将当前行代码上移或下移
③ crtl + shift + f10:运行当前代码文件
④ shift + f6:重命名文件
⑤ ctrl+ f:搜索
二、基础语法
1. 字面量
字面量是被写在代码中的固定的值。常见的字面量类型有字符串、整数和浮点数
2. 注释
注释是代码中的解释语句,用来对代码内容进行注解,提高代码的可读性。注解不是代码,不会被程序执行。
① 单行注释:以#开头,#右边的所有文字当作说明,而不是真正要执行的程序,起辅助说明作用。
# 我是单行注释
print("Hello World!")
注意:# 和注释的内容一般用空格隔开。
单行注释一般用于对一行或一小部分代码进行解释。
② 多行注释:通过一对三个引号来定义("""注释内容"""),引号内部均是注释,可以换行。
""" 我是多行注释 可以换行 """
多行注释一般用于对Python文件、类或方法进行解释。
3. 变量
变量就是在程序运行时,能储存计算结果或能表示值的抽象概念。简单的说,变量就是在程序运行时,记录数据用的。
① 定义的格式:变量名 = 变量值
② 特征:变量的值可以改变。
4. 数据类型
① 通过 type() 语句来得到数据的类型,语法:type(被查看类型的数据)
② 使用方式:
Ⅰ. 在 print 语句中,直接输出类型信息:
输入:print(type("桂子")) or print(type(666)) or print(type(13.14))
输出:<class 'str'> or <class 'int'> or <class 'float'>
Ⅱ. 用变量存储 type() 返回的结果:
string_type = type("桂子")
print(string_type)
注意:通过 type(变量) 查看的是变量存储的数据的类型,变量无类型,但是它存储的数据有。
5. 数据类型转换
① 常见的转换语句
Ⅰ. int(x):将 x 转换为一个整数
Ⅱ. float(x):将 x 转换为一个浮点数
Ⅲ. str(x):将 x 转换为一个字符串
② 注意:
Ⅰ. 任何类型都可以转换为字符串,但只有数字字符串才能转换成数字
Ⅱ. 浮点数转换成整数会丢失精度
6. 标识符
标识符是用户在编程的时候所使用的一系列名字,用于给变量、类、方法等命名。
① 标识符命名规则:
Ⅰ. 内容限定:标识符命名中,只允许出现英文、中文、数字以及下划线,并且不推荐使用中文和数字不可以开头。
Ⅱ. 大小写敏感:同样的英文,大小写不同也是可以区分的。
Ⅲ. 不可使用关键字
② 变量命名规范:
Ⅰ. 见名知意:要做到简介明了,尽量让别人看得懂,尽量的短
Ⅱ. 下划线命名法:多个单词组合变量名,要使用下划线做分隔
Ⅲ. 英文字母全小写
不遵守规则,不能运行;不遵守规范,不够高级。
7. 运算符
① 算数运算符:
| 运算符 | 描述 | 实例(a = 10, b = 20) |
|---|---|---|
| + | 加 | a + b = 30 |
| - | 减 | a - b = -10 |
| * | 乘 | a * b = 200 |
| / | 除 | b / a = 2 |
| // | 取整除 | 9 // 2 = 4,9.0 // 2.0 = 4.0 |
| % | 取余 | b % a = 0 |
| ** | 指数 | a ** 2 = 100 |
② 赋值运算符:
Ⅰ. 标准赋值:=
Ⅱ. 复合赋值:+=、-=、*=、/=、//=、%=、**=
8. 字符串
① 定义方式:
Ⅰ. 单引号定义法:name = '桂子'
Ⅱ. 双引号定义法:name = "桂子"
Ⅲ. 三引号定义法:name = """桂子"""
注意:三引号定义法和多行注释的写法一样,同样支持换行操作。使用变量接收它,它就是字符串;不使用变量接收它,就可以作为多行注释使用。
Ⅳ. 字符串的引号嵌套:
-
单引号定义法:可以内含双引号
-
双引号定义法:可以内含单引号
-
可以使用转义字符 \ 来将引号解除效用,变成普通字符串
② 拼接:
Ⅰ. 使用 + 连接字符串变量或字符串字面量即可:
name = "桂子"
print("我的名字是" + name)
Ⅱ. 无法和非字符串类型拼接
# 错误示范
name = "桂子"
age = 23
print("我的名字是" + name + ",年龄是" + age)
③ 格式化方式一
Ⅰ. 格式化语法:
-
单个占位符:
print("%占位符" % 变量) -
多个占位符:
print("%占位符1 %占位符2 %占位符3..." % (变量1, 变量2, 变量3))
Ⅱ. 常用的占位符:整数 %d、浮点数 %f、字符串 %s
④ 精度控制
使用辅助符号"m.n"来控制数据的宽度和精度。
Ⅰ. m,控制宽度(很少使用),要求是数字,宽度不够的用空格来凑。若设置的宽度小于数字自身,不生效。
Ⅱ. .n,控制小数点精度,要求是数字,会进行小数的四舍五入。
示例:
-
%5d:表示将整数的宽度控制在5位,如数字11被设置为5d,就会变成∶[空格][空格][空格]11,用三个空格补足宽度。
-
%5.2f:表示将宽度控制为5,将小数点精度设置为2,小数点和小数部分也算入宽度计算。如数字11.345被设置为%7.2f,就会变成:[空格][空格]11.35。2个空格补足宽度,小数部分限制2位精度后,四舍五入为.35。
-
%.2f:表示不限制宽度,只设置小数点精度为2,如数字11.345被设置为%.2f,就会变成:11.35。
⑤ 格式化方式二
Ⅰ. 格式化语法:print(f"{变量1} {变量2} {变量3} ...")
Ⅱ. 注意:这种方式不会要求类型,也不会做精度控制,适合对精度没有要求的时候快速使用。
⑥ 表达式的格式化
表达式是一个具有明确结果的代码语句,如1+1、type(“字符串”)、3*5等。
格式化表达式的方法:
Ⅰ. f"{表达式}" Ⅱ. "%s\%d\%f" % (表达式、表达式、表达式)
⑦ input 输入
Ⅰ. input() 语句的功能是,获取键盘输入的数据。
Ⅱ. 使用 input("提示信息"),可以在使用者输入内容之前显示提示信息。
Ⅲ. 注意,无论键盘输入什么类型的数据,获取到的数据永远都是字符串类型。
三、布尔类型
1. 类型
① True:真
② False:假
2. if
语句格式:
if 要判断的条件:
条件成立时,要做的事情
3. if_else
语句格式:
if 要判断的条件:
条件成立时,要做的事情
else:
条件不成立时,要做的事情
4. if_elif_else
语句格式:
if 条件1:
条件1成立时,要做的事情
elif 条件2:
条件1成立时,要做的事情
...
elif 条件N:
条件N成立时,要做的事情
else:
所有条件都不成立时,要做的事情
5. while
语句格式:
while 条件:
条件满足时,要做的事情
6. for
① 语句格式:
for 临时变量 in 待处理数据集(序列):
满足循环条件时执行的代码
② 实例:
name = "guizi"
for x in name:
print(x)
输出:
g
u
i
z
i
③ 注意:
Ⅰ. 同 while 循环不同,for 循环是无法定义循环条件的,只能从被处理的数据集中,依次取出内容进行处理。
Ⅱ. 理论上讲,Python 的 for 循环无法构建无限循环(被处理的数据集不可能无限大)。
7. range
① 作用:获得一个简单的数字序列。
② 语句格式:
Ⅰ. range(num):获取一个从 0 开始,到 num 结束的数字序列(不含 num 本身)。如 range(5) 取得的数据是:[0, 1, 2, 3, 4]。
Ⅱ. range(num1, num2):获得一个从 num1 开始,到 num2 结束的数字序列(不含 num2 本身)。如,range(5, 10)取得的数据是:[5, 6, 7, 8, 9]。
Ⅲ. range(num1, num2, step):获得一个从 num1 开始,到 num2 结束的数字序列(不含 num2 本身),数字之间的步长,以 step 为准(step 默认为1)。如,range(5, 10, 2) 取得的数据是:[5, 7, 9]。
③ 搭配 for 循环使用:
# 使得 for 循环可以指定循环次数
for i in range(1, 10):
print(i)
8. 作用域
for 循环中的临时变量,其作用域限定为循环内,但这种限定:
-
是编程规范的限定,而非强制限定
-
不遵守也能正常运行,但是不建议这样做
-
如需访问临时变量,可以预先在循环外定义它
9. print 拓展
① print("显示的内容", end='')中的end=''可以让 print 不换行
② 单独一个print就是换行
四、函数
1. 基本概念
① 函数是组织好的、可重复使用的、用来实现特定功能的代码段。
② 使用函数的好处是:
Ⅰ. 将功能封装在函数内,可供随时随地重复利用
Ⅱ. 提高代码的复用性,减少重复代码,提高开发效率
③ 定义格式:
def 函数名(传入参数):
函数体
return 返回值
2. None
None 作为一个特殊的字面量,用于表示空、无意义,其有非常多的应用场景。
① 用在函数无返回值上
② 用在 if 判断上
Ⅰ. 在 if 判断中,None 等同于 False
Ⅱ. 一般用于在函数中主动返回 None,配合 if 判断做相关处理
③ 用于声明无内容的变量上:定义变量,但暂时不需要变量有具体值,可以用None来代替
# 暂不赋予变量具体值 name = None
3. 函数说明文档
① 对函数进行说明解释,帮助更好理解函数的功能。
② 定义语法:
def func(x,y):
"""
函数说明
:param x: 参数x的说明
:param y: 参数y的说明
:return: 返回值的说明
"""
函数体
return 返回值
4. 变量的作用域
① 局部变量:作用范围在函数内部,在函数外部无法使用
② 全局变量:在函数内部和外部均可使用
③ 如何将函数内定义的变量声明为全局变量:使用 global 关键字
num = 200
def func_a():
num = 500
def func():
global num
num = 500
func_a()
print(f"num = {num}") # 结果为 num = 200
func_b()
print(f"num = {num}") # 结果为 num = 500
5. 多个返回值
按照返回值的顺序,写对应顺序的多个变量接收即可,变量之间用逗号隔开,支持不同类型的数据 return:
def test_return():
return 1, "guizi", True
x, y, z = test_return
print(x) # 结果 1
print(y) # 结果 'guizi'
print(z) # 结果 True
6. 参数使用方式
① 位置参数
Ⅰ. 调用函数时根据函数定义的参数位置来传递参数
def user_info(name, age, gender):
print(f"您的名字是人{name},年龄是{age},性别是{gender}")
user_info ( 'TOM' ,20,‘男')
注意:传递的参数和定义的参数的顺序及个数必须一致
② 关键字参数
Ⅰ. 函数调用时通过“键 = 值”形式传递参数
Ⅱ. 作用:可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求
def user_info(name, age, gender):
print(f"您的名字是: {name},年龄是: {age},性别是: {gender}")
# 关键字传参
user_info(name="小明", age=20, gender="男")
# 可以不按照固定顺序
user_info(age=20, gender="男", name="小明")
# 可以和位置参数混用,但位置参数必须在前,且匹配参数顺序
user_info("小明", age=20, gender="男")
注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序。
③ 缺省参数
Ⅰ. 缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)。
Ⅱ. 作用:当调用函数时没有传递参数,就会使用缺省参数默认的值。
def user_info(name, age, gender = '男'):
print(f'您的名字是{name},年龄是{age},性别是{gender}')
user_info('TOM', 20)
user_info('Rose', 18, '女')
注意:函数调用时,如果为缺省参数传值则修改默认参数值,否则使用这个默认值。
④ 不定长参数
Ⅰ. 不定长参数也叫可变参数,用于不确定调用的时候会传递多少个参数(不传参也可以)的场景。
Ⅱ. 作用:当调用函数时不确定参数个数时,可以使用不定长参数。
Ⅲ. 不定长参数的类型:
-
位置传递:位置不定长传递以 * 号标记一个形式参数,以元组的形式接受参数,形式参数一般命名为 args。
-
传进的所有参数都会被 args 变量收集,它会根据传进参数的位置合并为一个元组(tuple),args 是元组类型,这就是位置传递。
def user_info(*args):
print(args)
#('TOM', )
user_info('TOM')
#('TOM', 18)
user_info('TOM', 18)
-
关键字传递:关键字不定长传递以 ** 号标记一个形式参数,以字典的形式接受参数,形式参数一般命名为 kwargs。
-
参数是“键 = 值”形式的情况下,所有的“键 = 值”都会被 kwargs 接收,同时会根据“键 = 值”组成字典。
def user_info(**kwargs) :
print(kwargs)
# {'name': 'TOM', 'age': 18, 'id': 110}
user_info(name = 'TOM', age = 18, id = 110)
7. 函数作为参数传递
① 函数本身是可以作为参数,传入另一个函数中进行使用的。
② 将函数传入的作用在于:传入计算逻辑,而非传入数据。
def test_func(args):
result = args(1, 2)
print(result)
def compute(x, y):
return x + y
test_func(compute) # 结果 3
test_func 需要一个函数 args 作为参数传入,其中 args 需要接收 2 个数字进行计算,计算逻辑由 args 函数决定。
8. lambda 匿名函数
① 函数的定义中
-
def 关键字,可以定义带有名称的函数;
-
lambda 关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用;无名称的匿名函数,只可临时使用一次。
② 匿名函数定义语法:lambda 传入参数: 函数体(一行代码)
-
lambda 是关键字,表示定义匿名函数
-
传入参数表示匿名函数的形式参数,如:x,y表示接收 2 个形式参数
-
函数体就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
def test_func(compute):
result = compute(1,2)
print(result)
test_func(lambda x, y: x + y) # 结果 3
③ 注意:
-
匿名函数用于临时构建一个函数,只用一次的场景
-
匿名函数的定义中,函数体只能写一行代码,如果函数体要写多行代码,不可用 lambda 匿名函数,应使用 def 定义带名函数
五、数据容器
1. 基本概念
① 数据容器是一种可以存储多个元素的 Python 数据类型。
② Python有哪些数据容器:list(列表)、tuple(元组)、str(字符串)、set(集合)、dict(字典)
2. 列表 list
① 基本语法:
#字面量 [元素1, 元素2, 元素3, 元素4, ...] #定义变量 变量名称 = [元素1, 元素2, 元素3, 元素4, ...] #定义空列表 变量名称 = [] 变量名称 = list()
② 注意:列表一次可以存储多个数据,且可以为不同的数据类型,支持嵌套。
③ 特点:
Ⅰ. 可以容纳多个元素(上限为2**63-1、9223372036854775807个)
Ⅱ. 可以容纳不同类型的元素(混装)
Ⅲ. 数据是有序存储的(有下标序号)
Ⅳ. 允许重复数据存在
Ⅴ. 可以修改(增加或删除元素等)
3. 列表 list 的方法
① 查找某元素的下标
Ⅰ. 查找指定元素在列表的下标,如果找不到,报错 ValueError
Ⅱ. 语法:列表.index(元素)
my_list = ["guizi", "good", "study"]
index = my_list.index("good")
print(f"good在列表中的下标为{index}") # 结果为 1
② 插入元素
Ⅰ. 在指定的下标位置,插入指定的元素
Ⅱ. 语法:列表.insert(下标, 元素)
my_list = [1, 2, 3] my_list.insert(1, "guizi") print(my_list) # 结果为 [1, "itheima", 3, 4]
③ 追加元素
方法一:
Ⅰ. 将指定元素追加到列表的尾部
Ⅱ. 语法:列表.append(元素)
my_list = [1,2,3] my_list.append(4) print(my_list) # 结果为 [1, 2, 3, 4] my_list = [1,2,3] my_list.append([4,5,6]) print(my_list) # 结果为 [1, 2, 3, 4, 5, 6]
方法二:
Ⅰ. 将其它数据容器的内容取出,依次追加到列表尾部
Ⅱ. 语法:列表.extend(其它数据容器)
my_list = [1, 2, 3] my_list.extend([4, 5, 6]) print(my_list) # 结果为 [1, 2, 3, 4, 5, 6]
④ 删除元素
Ⅰ. 语法1:del 列表[下标]
Ⅱ. 语法2:列表.pop(下标)
my_list = [1, 2, 3]
# 方式1
del my_list[0]
print(my_list) # 结果为 [2, 3]
# 方式2
element = my_list.pop(0)
print(f"pop方法取出元素后列表内容: {mylist},取出的元素是: {element}")
注意:pop 方法不仅能删除元素,还能取到被删除的元素。
Ⅲ. 删除某元素在列表中的第一个匹配项,语法:列表.remove(元素)
my_list = [1, 2, 3, 2, 3] my_list.remove(2) print(my_list) # 结果为 [1, 3, 2, 3]
Ⅳ. 清空列表内容,语法:列表.clear()
my_list = [1, 2, 3] my_list.clear print(my_list) # 结果为 []
⑤ 统计某元素在列表内的数量
语法:列表.count(元素)
my_list = [1, 1, 1, 2, 3] print(my_list.count(1)) # 结果为 3
⑥ 统计列表内,有多少元素
Ⅰ. 可以得到一个 int 数字,表示列表内的元素数量
Ⅱ. 语法:len(列表)
my_list = [1, 2, 3, 4, 5] print(1en(my_list)) # 结果为 5
⑦ 列表的排序
语法:列表.sort(key = 选择排序依据的函数, reverse = True|False)
-
参数 key,是要求传入一个函数,表示将列表的每一个元素都传入函数中,返回排序的依据。
-
参数 reverse,是否反转排序结果,True 表示降序,False 表示升序。
# 如下嵌套列表,要求对外层列表进行排序,排序的依据是内层列表的第二个元素数字
# 以前学习的 sorted 函数就无法适用了。可以使用列表的 sort 方法
my_list = [["a", 33], ["b", 55], ["c", 11]]
# 一、带名函数形式
# 定义排序方法
# 将元素传入 choose_sort_key 函数中,用来确定按照谁来排序
def choose_sort_key(element):
return element[1]
my_list.sort(key=choose_sort_key, reverse=True)
# 二、匿名 lambda 形式
my_list.sort(key=lambda element: element[1], reverse=True)
print(my_list)
4. 元组 tuple
① 元组一旦定义完成,就不可修改。
注意:不可以修改元组的内容,否则会直接报错。可以修改元组内的 list 的内容(修改元素、增加、删除、反转等)。
② 基本语法,定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型:
# 定义元组字面量 (元素,元素,......,元素) # 定义元组变量 变量名称 = (元素,元素,......,元素) # 定义空元组 变量名称 = () # 方式1 变量名称 = tuple() # 方式2
注意:元组只有一个数据,这个数据后面要添加逗号
# 定义1个元素的元组
t2= ('Hello', ) # 注意,必须带有逗号,否则不是元组类型
③ 方法
| 方法 | 作用 | |
|---|---|---|
| 1 | index() | 查找某个数据,如果数据存在返回对应的下标,否则报错 |
| 2 | count() | 统计某个数据在当前元组出现的次数 |
| 3 | len(元组) | 统计元组内的元素个数 |
④ 特点:除了不可以修改(增加或删除元素等)外,其他特征和 list 一致。
5. 字符串
① 特点:
Ⅰ. 只可以存储字符串
Ⅱ. 长度任意(取决于内存大小)
Ⅲ. 支持下标索引
Ⅳ. 允许重复字符串存在
Ⅴ. 不可以修改(增加或删除元素等)
Ⅵ. 支持 for 循环
② 通用方法:
| 方法 | 作用 | |
|---|---|---|
| 1 | 字符串.index(字符串) | 查找给定字符的第一个匹配项的下标 |
| 2 | 字符串.count(字符串) | 统计字符串内某字符串的出现次数 |
| 3 | len(字符串) | 统计字符串的字符个数 |
6. 字符串的方法
① 字符串的替换
Ⅰ. 语法:字符串.replace(字符串1,字符串2)
Ⅱ. 功能:将字符串内的全部字符串1,替换为字符串2
my_str = "guizi"
new_my_str = my_str.replace("gui","桂")
print(f"将字符串{my_str}进行替换后得到: {new_my_str}") # 结果为 桂zi
Ⅲ. 注意:不是修改字符串本身,而是得到了一个新字符串
② 字符串的分割
Ⅰ. 语法:字符串.split(分隔符字符串)
Ⅱ. 功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存人列表对象中
my_str = "hello python guizi"
my_str_list = my_str.split(" ")
# 结果为 ['hello', 'python', 'itheima', 'itcast'],类型为 <class 'list'>
print(f"将字符串{my_str}进行split切分后得到: {my_str_list},类型是: {type(my_str_list)}")
Ⅲ. 注意:字符串本身不变,而是得到了一个列表对象
③ 字符串的规整操作一
Ⅰ. 语法:字符串.strip()
Ⅱ. 功能:去掉字符串前后的空格
my_str = " itheima and itcast " print(my_str.strip()) # 结果为 "itheima and itcast"
④ 字符串的规整操作二
Ⅰ. 语法:字符串1.strip(字符串2)
Ⅱ. 去掉字符串1前后指定字符串2
my_str = "12itheima and itcast21"
print(my_str.strip("12")) # 结果为 "itheima and itcast"
Ⅲ. 注意:传入的是“12”其实就是”1”和”2”,两个字符都会移除,是按照单个字符进行运算。
7. 序列
序列是指内容连续、有序,可使用下标索引的一类数据容器。列表、元组、字符串,均可以可以视为序列。
Ⅰ. 序列支持切片,即:列表、元组、字符串,均支持进行切片操作。切片就是从一个序列中,取出一个子序列。
Ⅱ. 语法:序列[起始下标:结束下标:步长],表示在序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列
-
起始下标表示从何处开始,可以留空,留空视作从头开始
-
结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
-
步长表示,依次取元素的间隔
-
步长1表示,一个个取元素
-
步长2表示,每次跳过1个元素取
-
步长N表示,每次跳过N-1个元素取
-
步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
-
8. 集合
① 基本语法
# 定义集合字面量
{元素,元素,......,元素}
# 定义集合变量
变量名称 = {元素,元素,......,元素}
# 定义空集合
变量名称 = set() # 只有这一种定义方式!
② 特点
Ⅰ. 可以容纳多个数据
Ⅱ. 可以容纳不同类型的数据(混装)
Ⅲ. 数据是无序存储的(不支持下标索引,因此不能用 while 循环遍历数组,只能用 for 循环)
Ⅳ. 不允许重复数据存在
Ⅴ. 可以修改(增加或删除元素等)
③ 通用方法:
| 操作 | 说明 |
|---|---|
| len(集合) | 得到一个整数,记录了集合的元素数量 |
9. 集合的方法
① 添加新元素
Ⅰ. 语法:集合.add(元素),将指定元素,添加到集合内。
Ⅱ. 结果:集合本身被修改,添加了新元素。
my_set = {"He11o","world"}
my_set.add("itheima")
print(my_set) #结果 { 'He1lo', 'itheima ', 'wor1d '}
② 移除元素
Ⅰ. 语法:集合.remove(元素),将指定元素,从集合内移除
Ⅱ. 结果:集合本身被修改,移除了元素
my_set = {"Hello", "world", "guizi"}
my_set.remove("Hello")
print(my_set) # 结果 { 'world', 'guizi' }
③ 从集合中随机取出元素
Ⅰ. 语法:集合.pop(),从集合中随机取出一个元素
Ⅱ. 结果:会得到一个元素的结果,同时集合本身被修改,元素被移除
my_set = {"Hello","world","itheima"}
element = my_set.pop()
print(my_set) # 结果 {'world', 'itheima'}
print(element) # 结果 'Hello'
④ 清空集合
Ⅰ. 语法:集合.clear(),清空集合
Ⅱ. 结果:集合本身被清空
my_set = { "Hello","world","itheima"}
my_set.clear()
print(my_set) #结果 set() 表示空集合
⑤ 取出2个集合的差集
Ⅰ. 语法:集合1.difference(集合2),取出集合 1 和集合 2 的差集(集合 1 有而集合 2 没有的)
Ⅱ. 结果:得到一个新集合,集合 1 和集合 2 不变
set1 = {1,2,3}
set2 = {4,5,6}
set3 = set1.difference(set2)
print(set3) # 结果 {2,3},得到的新集合
print(set1) # 结果 {1,2,3},不变
print(set2) # 结果 {1,5,6},不变
⑥ 消除2个集合的差集
Ⅰ. 语法:集合1.difference_update(集合2)
Ⅱ. 功能:对比集合 1 和集合 2,在集合 1 内,删除和集合 2 相同的元素。
Ⅲ. 结果:集合 1 被修改,集合 2 不变
set1 = {1,2,3}
set2 = {1,5,6}
set1.difference_update(set2)
print(set1) # 结果 {2,3}
print(set2) # 结果 {1,5,6}
⑦ 2个集合合并
Ⅰ. 语法:集合1.union(集合2)
Ⅱ. 功能:将集合 1 和集合 2 组合成新集合,并去除重复项
Ⅲ. 结果:得到新集合,集合 1 和集合 2 不变
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.union(set2)
print(set3) # 结果 {1, 2, 3, 5, 6},新集合
print(set1) # 结果 {1,2,3},set1不变
print(set2) # 结果 {1,5,6},set2不变
10. 字典
① 字典的定义,同样使用{},不过存储的元素是一个个的:键值对,如下语法∶
# 定义字典字面量
{key: value, key: value,......, key: value}
# 定义字典变量
my_dict = {key: value, key: value,......, key: value}
# 定义空字典
my_dict = {} # 空字典定义方式1
my_dict = dict() # 空字典定义方式2
② 字典同集合一样,不可以使用下标索引,但是字典可以通过 Key 值(Key 值不能重复)来取得对应的Value:
# 语法,字典[Key]可以取到对应的value
stu_score = {"王力鸿": 99, "周杰轮": 88, "林俊节": 77}
print(stu_score["王力鸿"]) # 结果 99
print(stu_score["周杰轮"]) # 结果 88
print(stu_score["林俊节"]) # 结果 77
③ 字典的 Key 和 Value 可以是任意数据类型(Key不可为字典),那么,就表明,字典是可以嵌套的。
# 定义嵌套字典
stu_score_dict = {
"王力鸿": {"语文": 77, "数学": 66, "英语": 33},
"周杰轮": {"语文": 78, "数学": 86, "英语": 53}
}
# 通过以下方式访问数据
score = stu_score_dict["王力鸿"]["数学"]
print(f"王力鸿的数学分数为{score}")
④ 通用方法:
| 操作 | 说明 |
|---|---|
| len(集合) | 得到一个整数,计算字典内的元素数量 |
| 字典.clear() | 清空字典 |
⑤ 特点
Ⅰ. 可以容纳多个数据
Ⅱ. 可以容纳不同类型的数据
Ⅲ. 每一份数据是 Key: Value 键值对
Ⅳ. 可以通过 Key 获取到 Value,Key 不可重复(重复会覆盖)
Ⅴ. 不支持下标索引(不支持while循环)
Ⅵ. 可以修改(增加或删除更新元素等)
11. 字典的方法
① 新增或修改元素
Ⅰ. 语法:字典[Key] = Value,若 Key 在字典中存在,则修改该 key 的值;若 Key 在字典中不存在,则为新增元素。
stu_score = {"王力鸿": 77, "周杰轮": 88, "林俊节": 99}
# 新增: 张学油的考试成绩
stu_score['张学油'] = 66
# 更新: 王力鸿的考试成绩
stu_score['王力鸿'] = 50
print(stu_score) # 结果 {'王力鸿': 50,'周杰轮':88,'林俊节': 99,'张学油': 66}
② 删除元素
Ⅰ. 语法:字典.pop(Key)
Ⅱ. 结果:获得指定 Key 的 Value,同时字典被修改,指定Key的数据被删除
stu_score = {"王力鸿": 77, "周杰轮": 88, "林俊节": 99}
value = stu_score.pop("王力鸿")
print(value) # 结果 77
print(stu_score) # 结果 {"周杰轮": 88,"林俊节": 99}
③ 获取全部的 Key
Ⅰ. 语法:字典.keys()
Ⅱ. 结果:得到字典中的全部 Key
stu_score = {"王力鸿": 77, "周杰轮": 88, "林俊节": 99}
keys = stu_score.keys()
print(keys) # 结果 keys(['王力鸿','周杰轮','林俊节'])
Ⅲ. 循环遍历字典
-
方式1:通过获取到全部的 key 来完成遍历
for key in keys:
print(f"字典的key是:{key}")
print(f"字典的value是: {my_dict[key]}")
-
方式2:直接对字典进行 for 循环,每一次循环都是直接得到 key
for key in my_dict:
print(f"2字典的key是:{key}")
print(f"2字典的value是: {my_dict[key]}")
12. 数据容器特点对比
| 列表 list | 元组 tuple | 字符串 str | 集合 set | 字典 dict | |
|---|---|---|---|---|---|
| 元素数量 | 支持多个 | 支持多个 | 支持多个 | 支持多个 | 支持多个 |
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | Key: 除字典外任意类型,Value: 任意 |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
| 使用场景 | 可修改、可重复的一批数据记录场景 | 不可修改、可重复的一批数据记录场景 | 一串字符的记录场景 | 不可重复的数据记录场景 | 以 Key 检索 Value的数据记录场景 |
| while 循环 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| for 循环 | 支持 | 支持 | 支持 | 支持 | 支持 |
13. 数据容器的通用方法
| 方法 | 说明 |
|---|---|
| len(容器) | 统计容器中的元素个数 |
| max(容器) | 计算容器中的最大元素 |
| min(容器) | 计算容器中的最小元素 |
| list(容器) | 将给定容器转换为列表 |
| str(容器) | 将给定容器转换为字符串 |
| tuple(容器) | 将给定容器转换为元组 |
| set(容器) | 将给定容器转换为集合 |
| sorted(容器, [reverse=True]) | 将给定容器进行排序(当 reverse = True 时为逆序排序) |
六、文件
1. 打开文件
① 使用 open 函数,可以打开一个已经存在的文件,或者创建一个新文件,语法:open(name, mode, encoding),其中
-
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
-
mode:设置打开文件的模式(访问模式:只读、写入、追加等)。
-
encoding:编码格式(推荐使用 UTF-8)。
f = open('python.txt', 'r', encoding = "UTF-8")
# encoding 的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定
② 基础访问模式
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。若文件不存在,则报错;文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
2. 读取文件
① read 方法:文件对象.read(num),其中
num 表示要从文件中读取的数据的长度(单位是字节),如果没有传入 num,那么就表示读取文件中所有的数据。
② readlines 方法:文件对象.readlines()
readlines 可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个 元素。
f = open('python.txt')
content = f.readlines()
# ['hello world\n', 'abcdefg\n', 'aaa\n', 'bbb\n', 'ccc']
print(content)
#关闭文件
f.close()
③ readline 方法:文件对象.readlines(),一次读取一行内容。
f = open('python.txt')
content = f.readline()
print(f'第一行:{content}')
content = f.readline()
print(f'第二行:{content}')
#关闭文件
f.close()
④ 注意:读取文件的每一个方法,都会根据上一次读取到的位置继续往下读取。
⑤ for 循环读取文件行
for line in open("python.txt","r"):
print(line)
#每一个 line 临时变量,就记录了文件的一行数据
3. 关闭文件
① close() 关闭文件对象
f = open("python.txt", "r")
f.close()
# 最后通过 close,关闭文件对象,也就是关闭对文件的占用
# 如果不调用 close,同时程序没有停止运行,那么这个文件将一直被 Python 程序占用。
② with open 语法
with open("python.txt", "r") as f:
f.readlines()
# 通过在 with open 的语句块中对文件进行操作
# 可以在操作完成后自动关闭 close 文件,避免遗忘掉 close 方法
4. 写入文件
① 当使用 w 或者 a 模式打开文件时,使用 write 方法可以给文件添加数据:文件对象.write(要写入的数据)
# 1.打开文件
f = open('python.txt' , 'w')
# 2.文件写入
f.write('hello world')
# 3.内容刷新
f.flush()
# close() 也具有 flush() 的功能,可以直接调用 close()
f.close()
注意:直接调用 write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区的区域;当调用 flush 的时候,内容会真正写入文件,这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)。
七、异常
1. 捕获异常
① 常规异常
通过这种方式可以捕获到所有异常,基本语法:
try:
可能发生错误的代码
except:
如果出现异常执行的代码
② 指定异常
Ⅰ. 基本语法:
try:
print(name)
except NameError as e:
print('name变量名称未定义错误')
Ⅱ. 注意:
-
如果尝试执行的代码的异常类型和要捕获的异常类型不一致,则无法捕获异常。
-
一般 try 下方只放一行尝试执行的代码。
③ 多个异常
当捕获多个异常时,可以把要捕获的异常类型的名字,放到except后,并使用元组的方式进行书写。
try:
print(1/0)
except (NameError, ZeroDivisionError):
print('zeroDivision错误...')
④ 全部异常
当使用 Exception 作为要捕获的指定异常时,会将所有类型的异常都捕获到,后面更多会使用这种方式进行异常捕获。
try:
f = open( "D:/123.txt","r")
except Exception as e:
print("出现异常了")
2. 异常处理
① else
else 表示的是如果没有异常要执行的代码。
try:
print(1)
except Exception as e:
print(e)
else:
print('我是else,是没有异常的时候执行的代码')
② finally
finally 表示的是无论是否异常都要执行的代码,例如关闭文件。
try:
f = open('test.txt', 'r')
except Exception as e:
f = open('test.txt', 'w')
else:
print('没有异常,真开心')
finally:
f.close()
3. 异常传递
异常是具有传递性的。如以下代码所示,当函数 func01 中发生异常,并且没有捕获处理这个异常的时候,异常会传递到函数 func02,当func02 也没有捕获处理这个异常的时候,main 函数会捕获这个异常,这就是异常的传递性。
def func01()∶ # 异常在 func01 中没有被捕获
print("这是func01开始")
num = 1 / 0
print("这是func01结束")
def func02(): # 异常在 func02 中没有被捕获
print("这是func02开始")
func01()
print("这是func02结束")
def main(): # 异常在 mian 中被捕获
try:
func02()
except Exception as e:
print(e)
提示:当所有函数都没有捕获异常的时候,程序就会报错。
4. 拓展
f = None
try:
f = open(file_name, "r", encoding="UTF-8")
except Exception as e:
print(f"程序出现异常了,原因是: {e}")
finally:
if f: # 如果变量是 None,表示 False,如果有任何内容,就是 True
f.close()
八、模块和 Python 包
1. 模块
① Python 模块(Module),是一个 Python 文件,以 .py 结尾。模块能定义函数、类和变量,模块里也能包含可执行的代码。
② 导入模块
模块在使用前需要先导入,通常在代码文件的开头位置进行导入,导入的语法:[from 模块名] import \[模块│类│变量│函数│*] [as 别名],常用的组合形式如:
import 模块名 # 使用 模块名.功能名() 来调用功能,如 time.sleep(5) from 模块名 import 功能名 # 直接使用 功能名() 来调用功能,如 sleep(5) from 模块名 import * # 同上 import 模块名 as 别名 # 使用 别名.功能名() 来调用功能,如 t.sleep(5) from 模块名 import 功能名 as 别名 # 直接使用 别名() 来调用功能,如 sl(5)
④ 自定义模块
每个 Python 文件都可以作为一个模块,模块的名字就是文件的名字,就是说自定义模块名必须要符合标识符命名规则。
步骤:新建一个 Python 文件,命名为 my_module1.py,并在其中定义函数。
例如:
# 模块 my_module1.py
def test(a, b):
print(a + b)
# 其他文件 text_my_module.py 调用模块 import my_module1 my_module1.test(10, 20)
注意:
-
在自定义模块中,当我们要测试功能时,在
if __name__ == '__main__:'内编写代码,可以在自定义模块下运行,同时其他文件调用自定义模块时也不会运行 if 下的代码;反之在其他文件调用自定义模块时,会将编写的代码直接运行。 -
在自定义模块中,用
__all__ = ['模块中的方法名等']变量可以限制其他文件使用from xxx import *,使得其他文件导入时,只能导入这个列表中的元素。
2. Python 包
① 从物理上看,包就是一个文件夹,在该文件夹下包含了一个__init__.py文件,该文件夹可用于包含多个模块文件;从逻辑上看,包的本质依然是模块。
② 作用:当我们的模块文件越来越多时,包可以帮助管理这些模块,包的作用就是包含多个模块,但包的本质依然是模块。
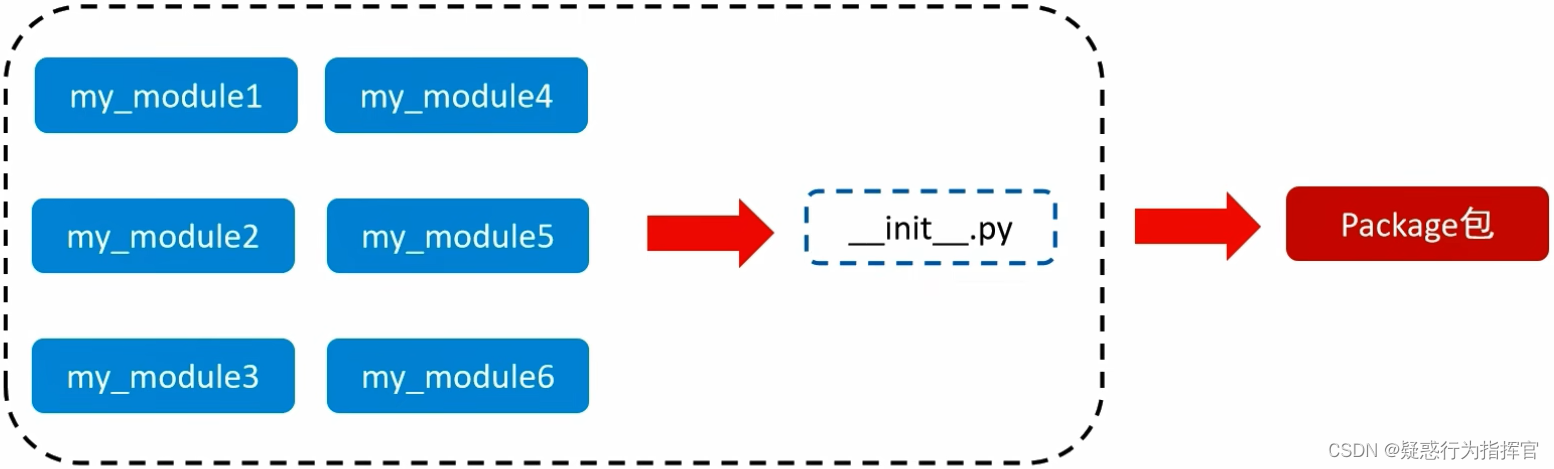
③ 步骤:点击左上角”文件“中的”新建“ -> 选择”Python 包“ -> 输入包名,点击“确定“ -> 右键点击新创建的 Python 包 -> 新建功能模块(有联系的模块)
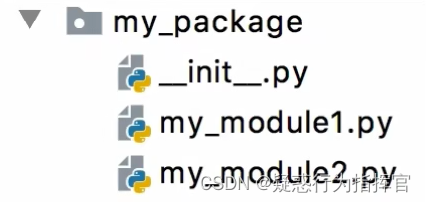
注意:新建包后,包内部会自动创建__init__.py文件,这个文件控制着包的导入行为。
④ 导入并使用包的基本语法:
Ⅰ. 方式一:按照导入模块的方法进行导入
# 导入包中的指定模块 import 包名.模块名 # 使用模块下定义的方法 包名.模块名.方法() # 或者 from 包名 import 模块名 模块名.方法() # 或者 from 包名.模块名 import 方法() # 直接调用 方法()
Ⅱ. 方式二:在__init__.py文件中添加__all__ = [](必须),控制允许导入的模块列表
from 包名 imoort * 模块名.方法()
3. 第三方包
① 在 Python 程序的生态中,有许多非常多的第三方包(非 Python 官方),可以极大的帮助我们提高开发效率,如:
-
科学计算中常用的:numpy 包
-
数据分析中常用的:pandas 包
-
大数据计算中常用的:pyspark、apache-flink 包
-
图形可视化常用的:matplotlib、pyecharts 包
-
人工智能常用的:tensorflow 包
-
等
② 安装第三方包
Ⅰ. 在命令提示符内输入 pip install 包名称 或当下载速度较慢时,可使用pip install -i https://pypi.tuna.tsinghua.edu.cn/simple包名称
Ⅱ. 在 PyCharm 下载
左键点击右下角”Python 版本号“ -> 点击”解释器设置“ -> 点击右边列表框的左上角”+“号 -> 在顶部搜索框输入需要的包进行搜索 -> 选择要下载的包(当网速慢时,勾选右下角“选项”,在“选项”右边输入框中输入-i https://pypi.tuna.tsinghua.edu.cn/simple) -> 点击左下角”下载包“ -> 等待下载完成即可。
九、JSON 与 PyEcharts
1. JSON
① JSON 是一种轻量级的数据交互格式,可以按照 JSON 指定的格式去组织和封装数据,其本质上是一个带有特定格式的字符串。
② 主要功能:JSON 就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互。
③ JSON 格式:
# json数据的格式可以是: 字典
{"name": "admin", "age": 18}
# 也可以是: 元素全部为字典的列表
[{"name": "admin", "age": 18}, {"name": "root", "age": 16}, {"name": "张三", "age": 20}]
④ Python 数据和 JSON 数据的相互转化
# 导入json模块
import json
# 准备符合 json 格式要求的 python 数据
data = [{"name": "老王", "age": 16}, {"name": "张三", "age": 20}]
# 通过 json.dumps(data) 方法把 python 数据转化为 json 数据
data = json.dumps(data)
# 通过 json.loads(data) 方法把 json 数据转化为 python 数据
data = json.loads(data)
注意:如果数据中包含中文,使用 json.dumps(data, ensure_ascii = False) 保证正确展示中文。
2. PyEcharts
① 基本概念
Ⅰ. 开发可视化图表使用的技术栈是 Echarts 的 Python 版本:PyEcharts 包。
Ⅱ. 安装 PyEcharts 包:pip install pyecharts
Ⅲ. 查看官方画廊(图表示例):https://gallery.pyecharts.org/#/README
② 基本操作
Ⅰ. 在 python 文件中编写好代码后,点击编译。
Ⅱ. 在当前文件的目录下会生成名为 xxx.html 的文件(可以在代码line.render("xxx.html")中指定生成的文件名),点击该文件,并选择一个浏览器打开。
3. 基础折线图
# 导包,导入 Line 功能构建折线图对象
from pyecharts.charts import Line
# 得到折线图对象
line = Line()
# 添加 x 轴数据
line.add_xaxis(["中国","美国","英国"])
# 添加 y 轴数据
line.add_yaxis("GDP", [30, 20, 10])
# 生成图表
1ine.render()
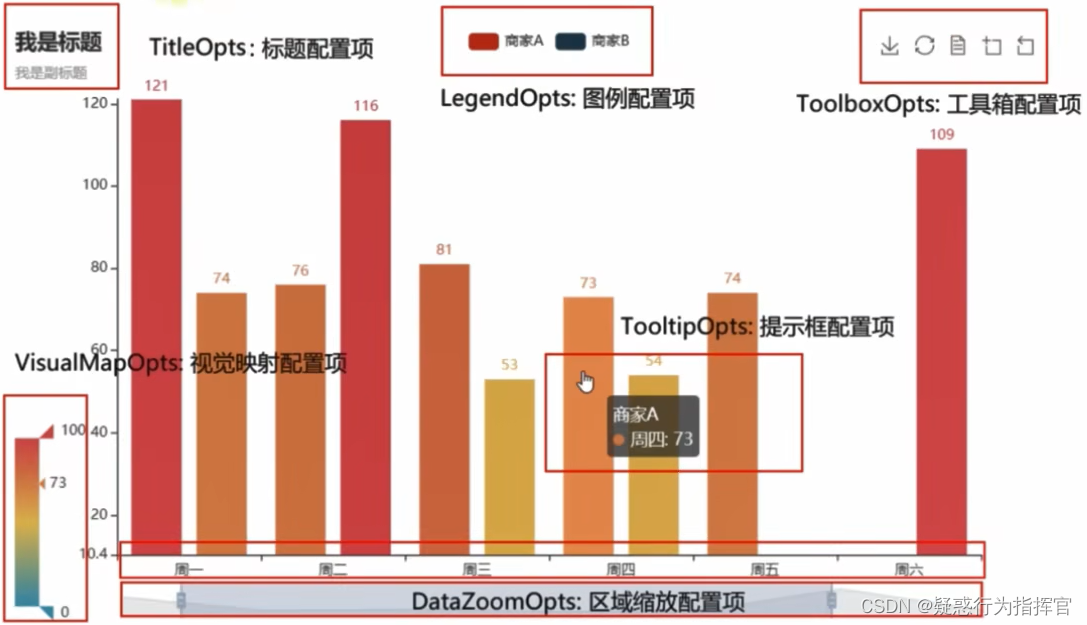
可以通过set_global_opts方法来进行配置,相应的选项和选项的功能如下:
# 设置全局配置项 set_global_opts 来设置
line.set_global_opts(
title_opts=TitleOpts(title="GDP展示", pos_left="center", pos_bottom="1%"),
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True)
)
4. 基础地图
from pyecharts.charts import Map
from pyecharts.options import VisualMap0pts
map = Map()
# 准备数据,需要列表 list
data = [
("北京",99),("上海",199),("湖南",299),("台湾",199),
("安徽",299),("广州",399),("湖北",599)
]
# 地图名称, 数据, 地图类型——也可以写具体省,e.g. 河南
map.add("地图", data, "china")
# 设置全局选项
map.set_global_opts(
visualmap_opts=VisualMap0pts(
is_show=True,
is_piecewise=True,
pieces=[
{"min": 1, "max": 9, "lable": "1-9", "color": "#CCFFFF"},
{"min": 10, "max": 99,"lable": "10-99", "color": "#FF6666"},
{"min": 100, "max": 500, "lable": "100-500", "color": "#990033"}
]
)
)
# 绘图
map.render()
将数据从字典转到列表,并装载到地图上
# 取到各省数据
# 将字符串 json 转换为 python 的字典
data_dict = json.loads(data)
# 基础数据字典
# 从字典中取出省份的数搪
province_data_list = data_dict["areaTree"][0]["children"]
# 组装每个省份和确诊人数为元组,并各个省的数据都封装入列表内
data_list = [] # 绘图需要用的数据列表
for province_data in province_data_list:
province_name = province_data["name"] # 省份名称
province_confirm = province_data["total"]["confirm"] # 确诊人数
data_list.append((province_name, province_confirm))
5. 基础柱状图
from pyecharts.charts import Bar
from pyecharts.options import *
# 构建柱状图对象
bar = Bar()
# 添加 x 轴数据
bar.add_xaxis(["中国","美国","英国"])
# 添加 y 轴数据,label_opts 设置数值标签在右侧显示
bar.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
# 反转 x 和 y 轴
reversal_axis()
# 绘图
bar.render("基础柱状图.html")
6. 时间线
from pyecharts.charts import Bar,Timeline
from pyecharts.options import *
from pyecharts.globals import ThemeType
# 方式一:适合柱状图很少的情况
# 定义柱状图
bar1 = Bar()
bar1.add_xaxis(["中国","美国",“英国"])
bar1.add_yaxis("GDP",[30,20,10],label_opts=Label0pts(position="right"))
bar1.reversal_axis()
bar2 = Bar()
bar2.add_xaxis(["中国","美国","英国"])
bar2.add_yaxis("GDP",[50,30,20],label_opts=Label0pts(position="right"))
bar2.reversal_axis()
# 创建时间线对象,theme 设置柱状图主题颜色
timeline = Timeline({"theme": ThemeType.LIGHT})
# timeline 对象添加 bar 柱状图
timeline.add(bar1, "2021年GDP")
timeline.add(bar2, "2022年GDP")
# 方式二:适合柱状图很多的情况
sorted_year_list = sorted(data_dict.keys())
for year in sorted_year_list:
x_data = []
y_data = []
for country_gdp in year_data:
x_data.append(country_gdp[0]) # x 轴添加国家
y_data.append(country_gdp[1] / 100000000) # y 轴添加 gdp 数据
# 构建柱状图
bar = Bar()
bar.add_xaxis(x_data)
bar.add_yaxis("GDP(亿)", y_dat, label_opts=Label0pts(position="right"))
# 反转 x 轴和 y 轴
bar.reversal_axis()
timeline.add(bar, str(year))
#设置自动播放
timeline.add_schema(
play_interval=1000, # 自动播放的时间间隔,单位毫秒
is_timeline_show=True, # 是否在自动播放的时候,显示时间线
is_auto_play=True, # 是否自动播放
is_loop_play=True # 是否循环自动播放
)
# 通过时间线绘图
timeline.render("基础柱状图-时间线.html")















 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









