






1 理论知识
1.1、SPI通信协议
1.1.1SPI 物理层
通讯模式是主从通讯模式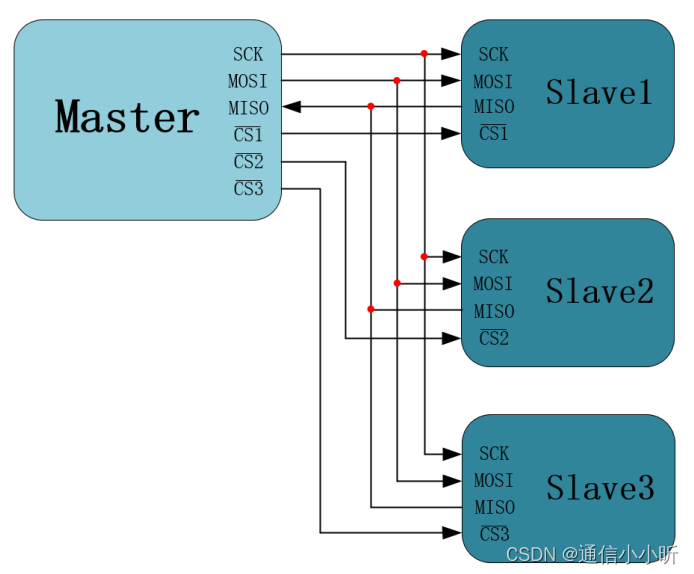 SPI 通讯协议包含 1 条时钟信号线、 2 条数据总线和 1 条片选信号线, 时钟信号线为
SPI 通讯协议包含 1 条时钟信号线、 2 条数据总线和 1 条片选信号线, 时钟信号线为
SCK, 2 条数据总线分别为 MOSI(主输出从输入)、 MISO(主输入从输出),片选信号线为
CS_N(低电平有效)
1.2flash特性
1.2.1页(Page)、扇区(Sector)、块(Block) 的概念
(1)页
Flash存储器中一种区域划分的单元,好比一本书中一页(其中包含N个字)
比如:STM32F1中小容量芯片内部Flash,1K字节为1页,整个Flash分为32页(当然,不同容量的芯片,页数不同)
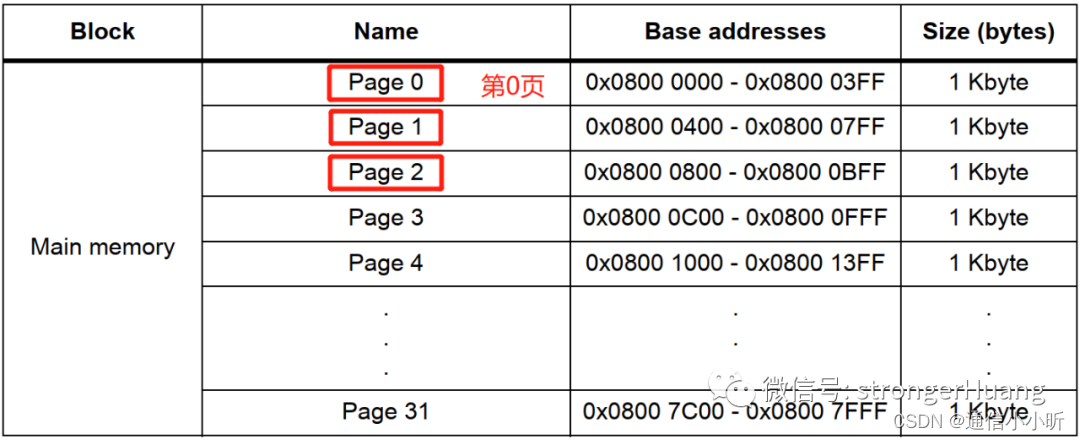
注: 不同厂家的、不同类型存储器的页大小不同,1KB、2KB、4KB等各种容量的页大小都有。
(2)扇区(Sector)
扇区和页类似,也是一种存储结构单元,只是扇区更常见,大部分Flash主要还是以扇区为最小的单元。
比如:W25Q256芯片以4KB为1扇区
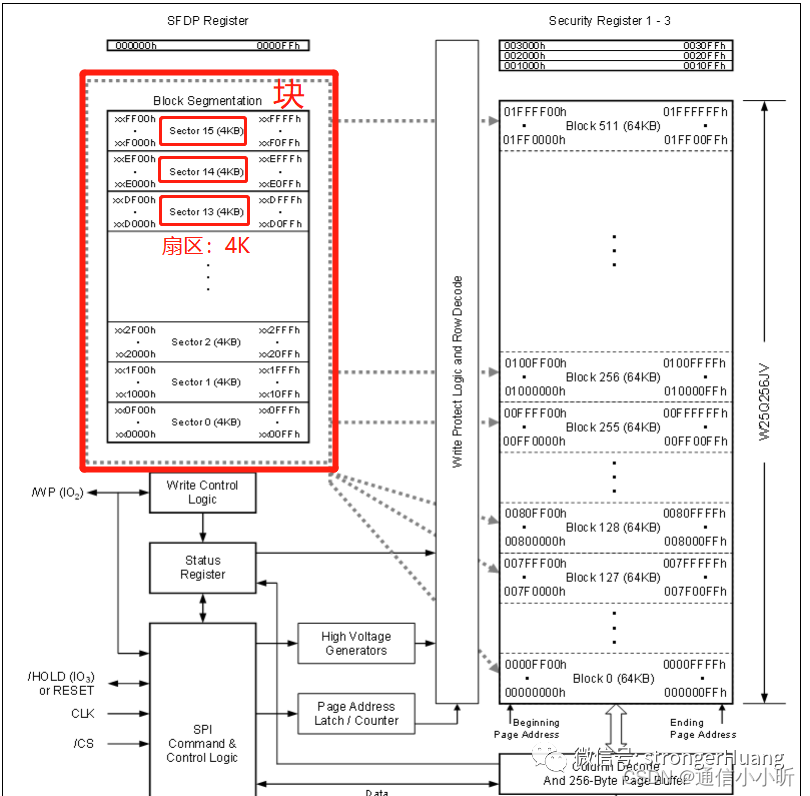
同样: 不同厂家的、不同类型存储器的扇区大小可能不同
(3)块(Block)
块,比扇区更高一个等级,一般1块包含多个扇区。
同样,以上图W25Q256芯片为例:1块包含16个扇区。
说明:W25Q256中256的意思是:存储空间256Mb (32M x 8) 也就是32M字节
还有,你可能会看到一些其他的名词,比如:和扇区一个级别的SubSector,和块一个级别的Bank、Bulk等
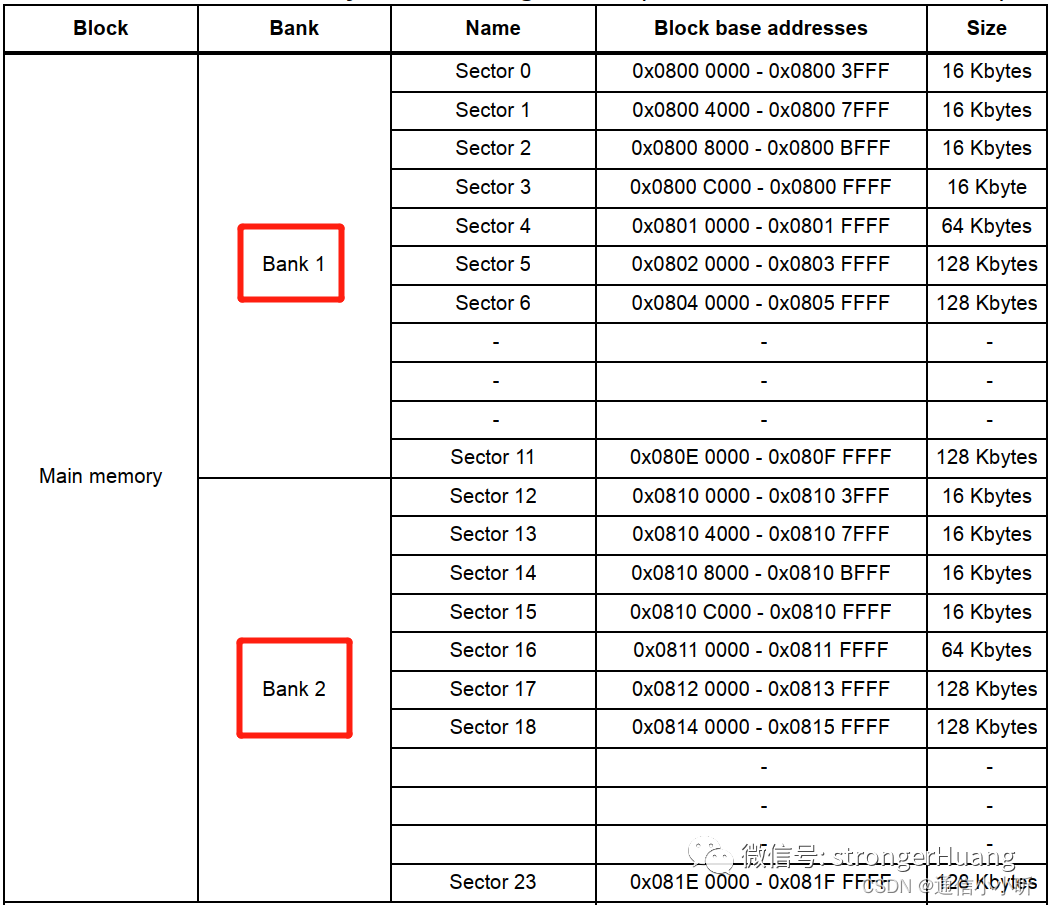
用包含关系来描述Flash物理分区的话: 芯片包含多个块,块又包含多个扇区,扇区又包含多个页,页包含多个字节
根据容量大小来说,它们的关系:
** 页(Page)** < 扇区(Sector) < 块(Block)< 芯片(Chip)**
1.3 几个时间的说明
保持时间:数据需要保持不变的时间
时序里面特别要注意的三个时间:
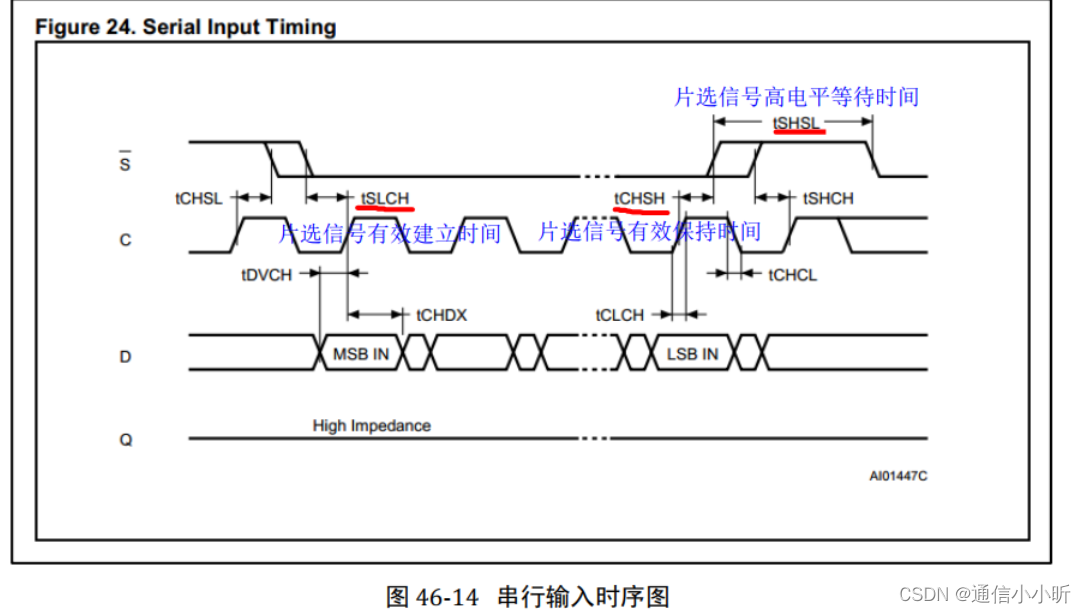
1 从片选信号拉低到第一个有效数据写入的时间tSLCH(最小5ns)
2 从最后一个有效数据写入到片选信号拉高的时间tCHSH(最小5ns)
3 片选信号的高电平等待时间tSHSL(最小100ns)
为了方便寄存器的计数 程序中采用的640ns的计数方式实现
2 实战演练
2.1 全擦除和扇区擦除
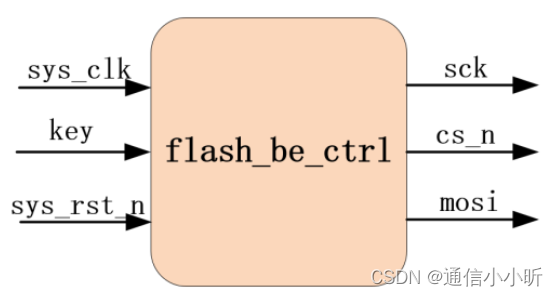
说明:根据按键消抖后的key的标志信号触发擦除指令。
出现触发信号后,根据flash的操作时序进行指令的一系列操作
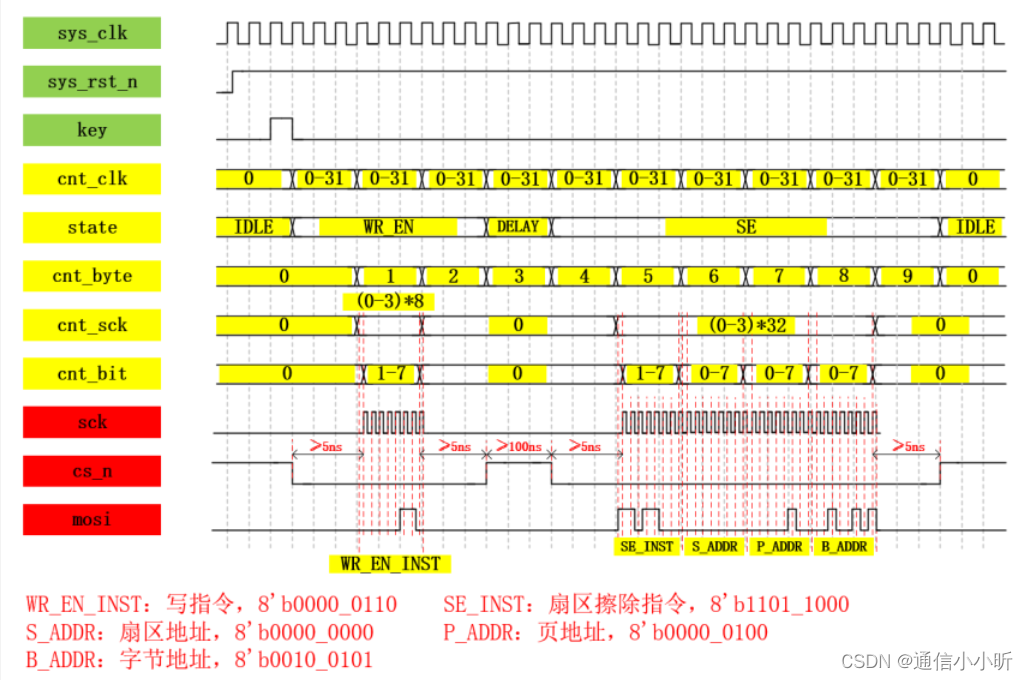
2.1.1 全擦除模块的波形图绘制

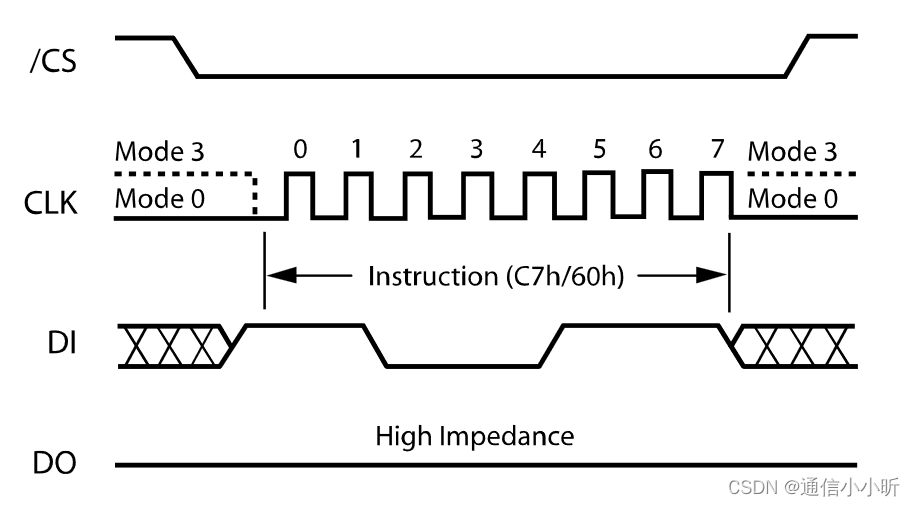
根据上述时序的要求,想要实现全擦除,首先要发送写使能指令(注意:在进行每次页面编程、扇区擦除、块擦除、芯片擦除和写状态寄存器操作前,必须设置 WEL 位。要输入“写使能”指令,请拉低 /CS 引脚,在 CLK 上升沿时向数据输入(DI)引脚输入指令代码“06h”,然后将 /CS 引脚拉高。)
然后按照上面的时序图实现C7指令的写入:先拉低cs_n,然后写入C7指令,等待一阵后拉高cs_n,至此全擦除功能实现完毕。
注意:
1、在写使能指令和全擦除指令写入的过程中 牵扯到指令的输入或者输出的时候sck才需要进行信号驱动,其他时刻sck为0即可。
2、发送指令过程中高位在前,低位在后。

2.1.2 扇区擦除的波形图的绘制
The Block Erase instruction sets all memory within a specified block (64K-bytes) to the erased state of all 1s (FFh). A Write Enable instruction must be executed before the device will accept the Block Erase Instruction (Status Register bit WEL must equal 1). The instruction is initiated by driving the /CS pin low and shifting the instruction code “D8h” followed a 24-bit block address (A23-A0) (see Figure 2). The Block Erase instruction sequence is shown in figure 18.
“块擦除”指令将指定块(64K 字节)中的所有存储器内容都设置为擦除状态即全是1(FFh)。在设备接受“块擦除”指令之前,必须先执行“写使能”指令(状态寄存器位 WEL 必须等于 1)。该指令由拉低 /CS 引脚并输入指令代码“D8h”,接着输入 24 位块地址(A23-A0),如图 2 所示。块擦除指令序列如图 18 所示。
The /CS pin must be driven high after the eighth bit of the last byte has been latched. If this is not done the Block Erase instruction will not be executed. After /CS is driven high, the self-timed Block Erase instruction will commence for a time duration of tBE (See AC Characteristics). While the Block Erase cycle is in progress, the Read Status Register instruction may still be accessed for checking the status of the BUSY bit. The BUSY bit is a 1 during the Block Erase cycle and becomes a 0 when the cycle is finished and the device is ready to accept other instructions again. After the Block Erase cycle has finished the Write Enable Latch (WEL) bit in the Status Register is cleared to 0. The Block Erase instruction will not be executed if the addressed page is protected by the Block Protect (TB, BP2, BP1, and BP0) bits (see Status Register Memory Protection table).
在最后一个字节的第 8 位被捕获后,必须将 /CS 引脚拉高。如果不这样做,则不会执行块擦除指令。将 /CS 引脚拉高后,将开始进行自定时块擦除指令,持续时间为 tBE(参见 AC 特性)。在块擦除循环进行时,仍可访问“读取状态寄存器”指令,以检查 BUSY 位的状态。在块擦除循环进行时,BUSY 位为 1,当循环结束并且设备准备好再次接受其他指令时,BUSY 位变为 0。块擦除周期结束后,“写使能锁存器(WEL)”位在状态寄存器中将被清除为 0。如果地址所在页面受“块保护”(TB、BP2、BP1 和 BP0)位(参见状态寄存器存储保护表)的保护,则块擦除指令将不会被执行。
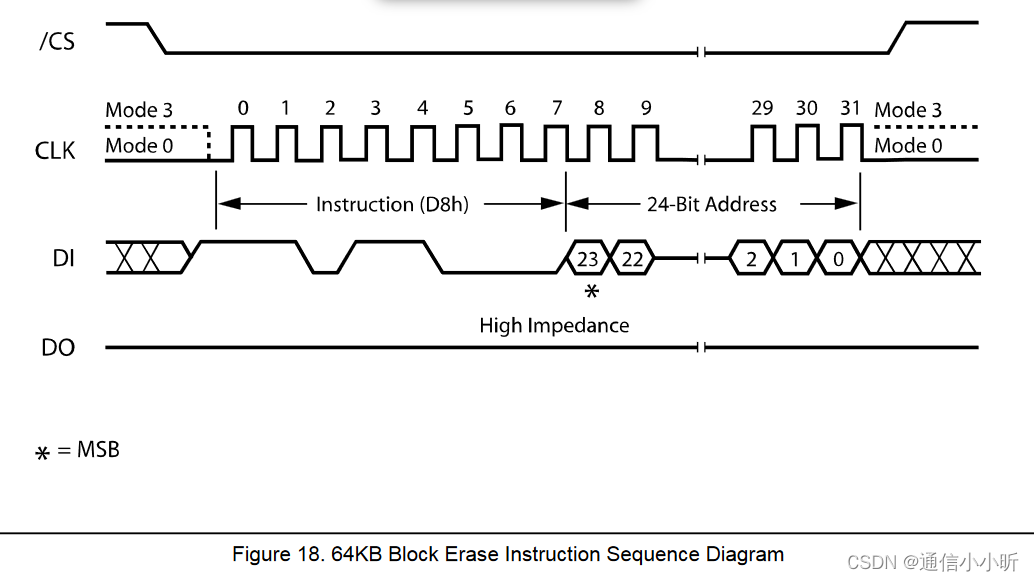
与全擦除类似,扇区擦除要求先进行写使能指令,然后先发送扇区擦除指令,紧接着发送地址
2.2 页写与连续写
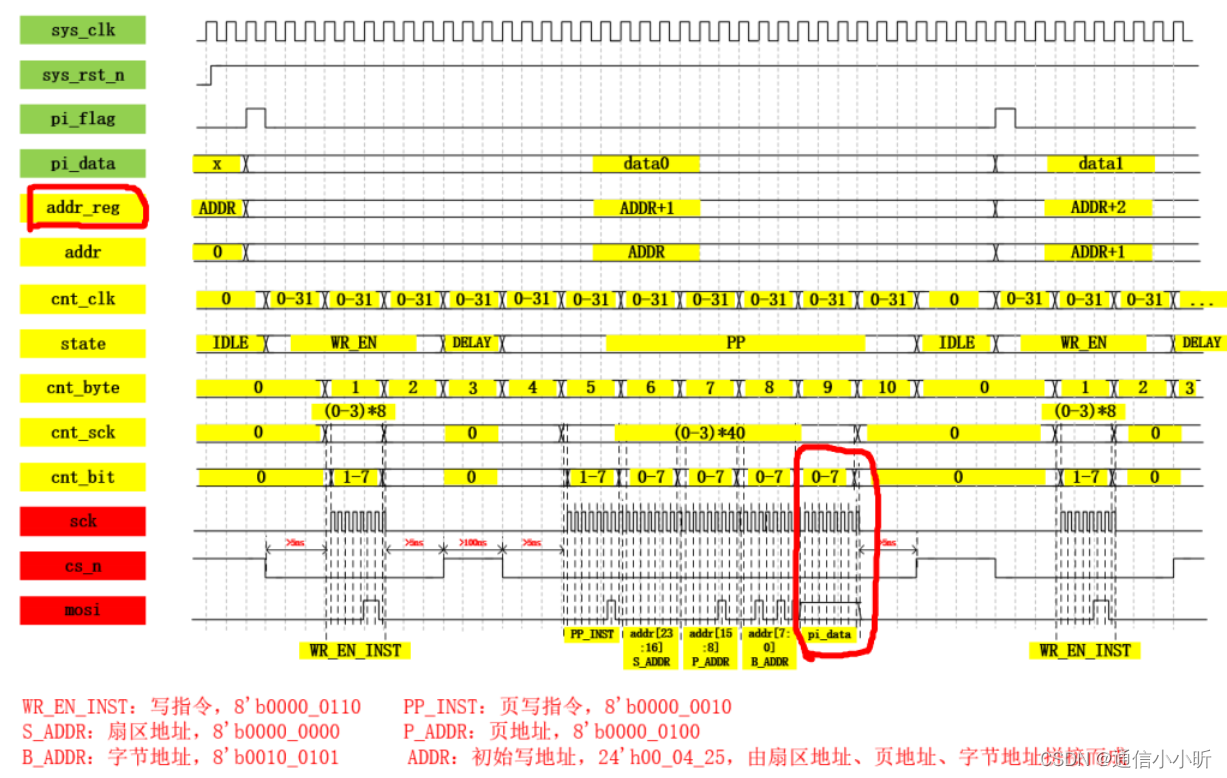
连续写这里就是多次的页写操作,同样根据芯片手册的要求进行相应时序程序的编写。
2.3 数据读取

这里涉及到跨时钟域处理的问题,为什么这么说?
首先,fpga对于flash数据的读取的速度要比串口发送到PC机的速度要快,这里为了实现串口数据的正确传输,这里就运用到了fifo IP核的相关知识:先把从flash读取到的数据暂存到8bit位宽的fifo当中,然后等待100个字节的串口数据接收完毕。在100个字节的串口数据接收完毕以后,设计一个cnt计时器,开始从fifo向串口的发送模块进行数据传输。
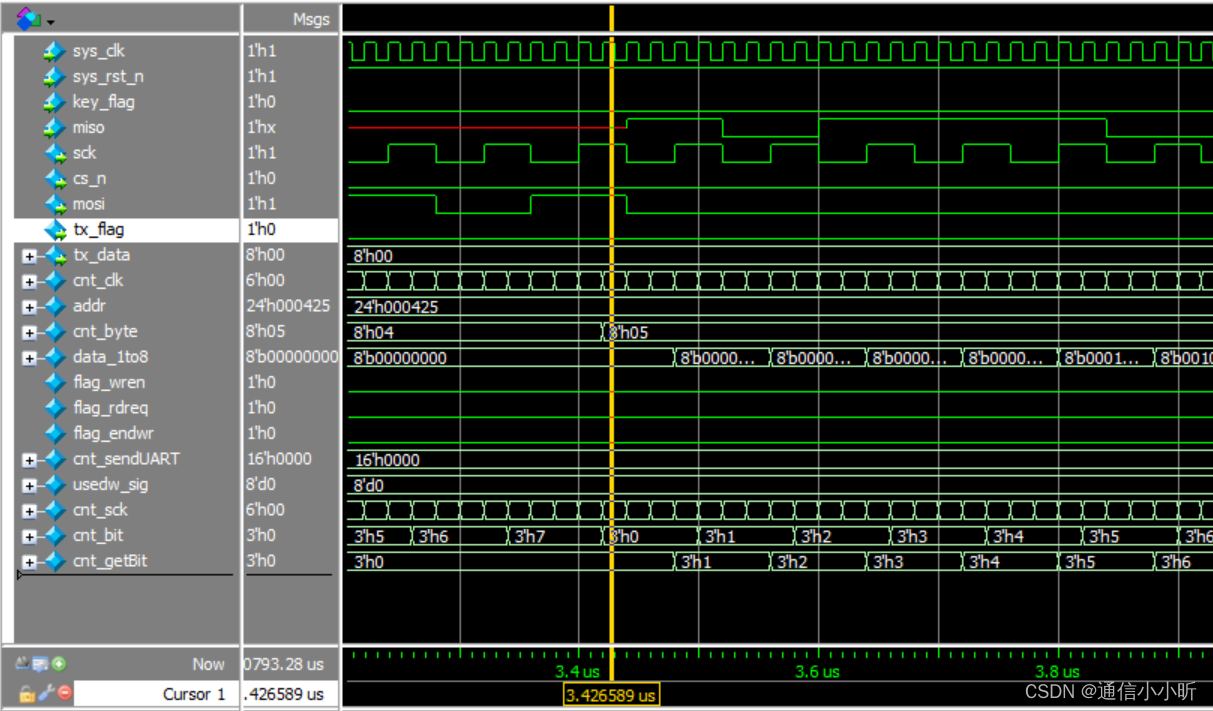
这里特别强调一下fifo数据的写入,这是笔者出现严重错误的部分,原因在于错误理解了芯片手册的介绍:
接收到地址后,被地址定位的存储器位置的数据字节会在 CLK 下降沿时从 DO 引脚开始以最高有效位(MSB)优先的方式依次输出。在每个数据字节输出后,地址会自动增加为下一个较高地址,以实现连续的数据流
注意数据的输出是从miso引脚出来的,但是要注意mimo数据的更新开始是在sck的下降沿,这也就意味着读取flash芯片的存储信息不能在sck的下降沿,因为此时的数据不稳定,数据的读入依然我们选择在sck的上升沿进行读取。这里有跨时钟域部分的含义,就是说通过同步fifo的模式,实现了从快速时钟域向慢速时钟域的转换。
3 总结
本章节的学习花费了笔者将近两个星期的时间,当然期间的学习是断断续续的。总结花费时间长的原因:1、学习的目的不明确,没有明确的学习方法论。对于芯片的学习,笔者觉得可以主要从两个方面学习,第一是芯片指令的学习,指令部分有比较详细的时序数据操作介绍;第二个是输入时序部分的讲解,通过输入时序的要求我们可以设置最小的byte计数时间。结合输入时序的要求核指令部分的介绍,就可以写出目的指令的时序程序,然后通过仿真进行验证。
此外,本次的代码的编写主要不是依靠viso文件波形图的绘制,更多的是依靠modelsim仿真后逐步对波形的调整实现的。这种情况是在波形图的中间变量太多,viso时序图不容易绘制的背景下出现的,当然,目前来说我不认为这是一种高效的编程方式。
同时我也注意到:所有中间变量都是为了服务于输入输出波形的对应关系的,所以说可能会存在输入输出波形一致,但是中间变量不一致的情况,而我们可能每个人编写程序的不同可能更多的也会体现在中间变量的设置上。














 4336
4336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









