







本文是接着上一篇深度学习之 3 线性模型_水w的博客-CSDN博客
目录
深度学习框架
深度学习框架是一种 接口 、 库 或 工具 ,利用 预先构建和优化好的组件 集合定义模型。
- 一个良好的深度学习框架应具备的关键特性:
✓ 性能优化✓ 易于理解和编码✓ 良好的社区支持✓ 并行处理以减少计算✓ 自动计算梯度
- 框架核心组件:
◼ 张量◼ 基于张量的操作◼ 计算图◼ 自动微分工具◼ BLAS、cuBLAS、cuDNN等拓展包
一、核心组件
- 框架核心组件:
◼ 张量◼ 基于张量的操作◼ 计算图◼ 自动微分工具◼ BLAS、cuBLAS、cuDNN等拓展包
核心组件-张量
张量是深度学习框架中最核心的组件,Tensor实际上就是一个多维数组。
Tensor对象具有3个属性:
• rank
:
number of dimensions
• shape: number of rows and columns
• type: data type of tensor's elements


核心组件-基于张量的操作
张量的相关操作:
•
类型转换
:字符串转为数字、转为64(32)位浮点类型(整型)等。
•
数值操作
:按指定类型与形状生成张量、正态(均匀)分布随机数、设置随机数种子。
•
形状变换:
将数据的shape按照指定形状变化、插入维度、将指定维度去掉等。
•
数据操作:
切片操作、连接操作等。
•
算术操作
:求和、减法、取模、三角函数等。
•
矩阵相关的操作:
返回给定对角值的对角tensor、对输入进行反转、矩阵相乘、求行列式…
核心组件-计算图
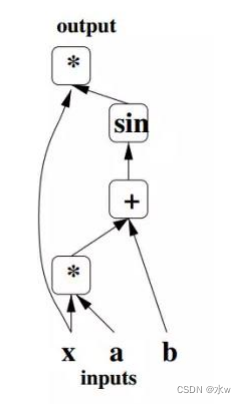
计算图结构 :
• 用不同的
占位符
(*,+,sin
)构成操作结点,以字母
x
、
a
、
b
构成变量结点。
• 用有向线段将这些结点连接起来,组成一个表征运算
逻辑关系
的清晰明了的“图”型数据结构
核心组件-自动微分工具
计算图带来的一个好处是让模型训练阶段的梯度计算变得 模块化 且更为 便捷 ,也就是 自动微分法 。◼ 自动微分Forward Mode:给定函数 𝑓(𝑥 1 , 𝑥 2 ) = ln(𝑥 1 ) + 𝑥 1 𝑥 2 − sin(𝑥 2 )

核心组件-BLAS、cuBLAS、cuDNN等拓展包
◼ 通过前面所介绍的组件,已经可以搭建一个全功能的深度学习框架:将待处理数据转换为张量,针对张量施加各种需要的操作,通过自动微分对模型展开训练,然后得到输出结果开始测试。◼ 存在的缺陷是运行缓慢◼ 利用扩展包来进行加速,例如:✓ Fortran实现的BLAS(基础线性代数子程序)✓ 英特尔的MKL(Math Kernel Library)✓ NVIDIA推出的针对GPU优化的 cuBLAS 和 cuDNN 等更据针对性的库
二、主流框架
◼ 深度学习的主流框架:✓ Caffe✓ Theano✓ Torch & PyTorch✓ TensorFlow✓ Keras✓ MXNet✓ OneFlow✓ MindSpore✓ PaddlePaddle
发展历程:

Caffe
◼ Caffe 的全称是 Convolutional Architecture for Fast Feature Embedding ,它是一个 清晰 、 高效 的深度学习框架,于2013 年底由加州大学伯克利分校开发,核心语言是 C++ 。它支持命令行、 Python 和MATLAB接口。 Caffe 的一个重要特色是可以在不编写代码的情况下训练和部署模型。 https://github.com/BVLC/caffe◼ Caffe2 是由 Facebook 组织开发的一个 轻量级 的深度学习框架,具有 模块化 和 可扩展性 等特点。它在原来的Caffe 的基础上进行改进,提高了它的表达性,速度和模块化,现在被并入 Pytorch项目。Caffe曾经名噪一时,但由于使用不灵活、代码冗长、安装困难、不适用构建循环网络等问题,已经很少被使用。 https://github.com/caffe2

◼ 优点:
✓
核心程序用
C++
编写,因此更
高效,适合工业界开发;
✓
网络结构都是以配置文件形式定义,不需要用代码设计网络;
✓
拥有大量的训练好的经典模型(
AlexNet
、
VGG
、
Inception)
在其
Model Zoo
里;
◼
缺点:
✓
缺少灵活性和扩展性;
✓
依赖众多环境,难以配置;
✓
缺乏对递归网络
RNN
和语言建模的支持,不适用于文本、声音或时间序列数据等其他类型的深度学习应用;
Theano
Theano 是深度学习框架的鼻祖,由 Yoshua Bengio 和蒙特利尔大学的研究小组于 2007 年创建,是率先广泛使用的深度学习框架。Theano 是一个 Python 库,速度更快,功能强大,可以高效的进行数值表达和计算,可以说是从NumPy 矩阵表达向 tensor 表达的一次跨越,为后来的深度学习框架提供了样板。遗憾的是Theano 团队 2017 年已经停止了该项目的更新,深度学习应用框架的发展进入到了背靠工业界大规模应用的阶段。https://github.com/Theano
◼
缺点:
✓
原始的
Theano
只有比较低级的
API
;大型模型可能需要
很长的编译时间
;
不支持多 GPU
;有的错误信息的提示没有帮助。
MXNet
MXNet 于 2014 年由上海交大校友陈天奇与李沐组建团队开发, 2017 年 1 月, MXNet 项目进入Apache 基金会,成为 Apache 的孵化器项目。 MXNet 主要用 C++ 编写,强调提高内存使用的效率,甚至能在智能手机上运行诸如图像识别等任务。◼ 它拥有类似于 Theano 和 TensorFlow 的数据流图,为多 GPU 配置提供了良好的配置,还有着类似于 Blocks 等更高级别的模型构建块,并且 可以在任何硬件上运行(包括手机 )。同时 MXNet 是一个旨在提高效率和灵活性的深度学习框架,提供了强大的工具来帮助开发人员利用 GPU和云计算的全部功能。 https://mxnet.apache.org/

◼
优点:
✓
灵活的编程模型
✓
从云端到客户端可移植
✓
多语言支持
✓
本地分布式训练
✓
性能优化
◼
缺点:
✓
社区相对
PyTorch
和
TensorFlow
来说相对小众
TensorFlow
TensorFlow 最初由 Google Brain 团队针对机器学习和深度神经网络进行研究所开发的,目前开源之后可以在几乎各种领域适用。它灵活的架构可以部署在一个或多个CPU 、 GPU 的台式及服务器中,或者使用单一的API 应用在移动设备中。 TensorFlow 可以说是当今十分流行的深度学习框架,Airbnb、 DeepMind 、 Intel 、 Nvidia 、 Twitter 以及许多其他著名公司都在使用它。 TensorFlow 提供全面的服务,构建了活跃的社区,完善的文档体系,大大降低了我们的学习成本 ,另外,TensorFlow 有很直观的计算图可视化呈现 。 模型能够快速的部署在各种硬件机器上,从高性能的计算机到移动设备,再到更小的更轻量的智能终端 。◼ 但是, TensorFlow 相比 Pytorch , Caffe 等框架, 计算速度很慢 。而且通过它构建一个深度学习框架 需要更复杂的代码 ,还要忍受重复的 多次构建静态图 。https://github.com/tensorflow

◼
优点:
✓
自带tensorboard可视化工具,能够让用户
实时监控观察训练过程
✓
拥有大量的开发者,有详细的说明文档、可查询资料多
✓
支持
多GPU、分布式训练,跨平台运行能力强
✓
具备不局限于深度学习的多种用途,
还有支持强化学习和其他算法的工具
◼
缺点:
✓
频繁变动的接口
✓
接口设计过于晦涩难懂
Keras
Keras 于 2015 年 3 月首次发布,拥有“为人类而不是机器设计的 API” ,由 Google 的 Francis Chollet 创建与维护,它是一个用于快速构建深度学习原型的 高层神经网络库 ,由纯 Python 编写而成,以TensorFlow, CNTK , Theano 和 MXNet 为底层引擎,提供简单易用的 API 接口,能够极大地减少一般应用下用户的工作量。 能够和TensorFlow , CNTK 或 Theano 配合使用。通过 Keras 的 API 可以仅使用数行代码就构建一个网络模型,Keras+Theano , Keras+CNTK 的模式曾经深得开发者喜爱。 目前Keras 整套架构已经封装进了 TensorFlow ,在 TF.keras 可以完成 Keras 的所有事情。 https://keras.io/

◼
优点:
✓
更简洁,更简单
的
API
✓
丰富的教程
和可重复使用的代码
✓
更多的部署选项(直接并且通过
TensorFlow
后端),更简单的模型导出
✓
支持
多
GPU
训练
◼
缺点:
✓
过度封装导致丧失灵活性,导致用户在新增操作或是获取底层的数据信息时过于困难
✓
许多
BUG
都隐藏于封装之中,
无法调试细节
✓
初学者容易依赖于
Keras
的易使用性而忽略底层原理
Torch & PyTorch
◼ Torch 是一个有大量机器学习算法支持的科学计算框架,其诞生已经有十余年,但真正起势得益于Facebook 开源了大量 Torch 的深度学习模块和扩展。 Torch 的一个特殊之处是采用了 Lua 编程语言(曾被用来开发视频旅游)。 https://github.com/torch◼ PyTorch 于 2016 年 10 月发布,是一款专注于 直接处理数组表达式 的低级 API 。 前身是 Torch 。 Facebook人工智能研究院对 PyTorch 提供了强力支持。 PyTorch 支持动态计算图 ,为更具数学倾向的用户提供了 更低层次 的方法和更多的灵活性,目前许多新发表的论文都采用 PyTorch 作为论文实现的工具, 成为学术研究的首选解决方案 。 https://github.com/pytorch

PyTorch:
◼
优点:
✓
简洁易用
✓
活跃的社区:提供
完整的文档和指南
✓
代码很
Pythonic
(简洁、优雅)
◼
缺点:
✓
导出模型不可移植,
工业部署不成熟
✓
代码冗余量较大
OneFlow
◼ OneFlow 是由北京一流科技有限公司开发的一款深度学习框架, OneFlow 围绕 性能提升 和 异构分布式扩展 ,秉持静态编译和流式并行的核心理念和架构,解决了集群层面的内存墙挑战。OneFlow计算集群内部的通信和调度消耗,提高硬件利用率,加快模型训练速度,训练成本时间大幅缩减。OneFlow 天生支持 数据并行 、 模型并行 和 混合并行。◼ OneFlow 是一个专门针对深度学习打造的异构分布式流式系统,大幅减少了运行时开销,且一旦成功启动无运行时错误。OneFlow 分布式易用,代码量优且完全自动并行。https://github.com/Oneflow-Inc/oneflow.git

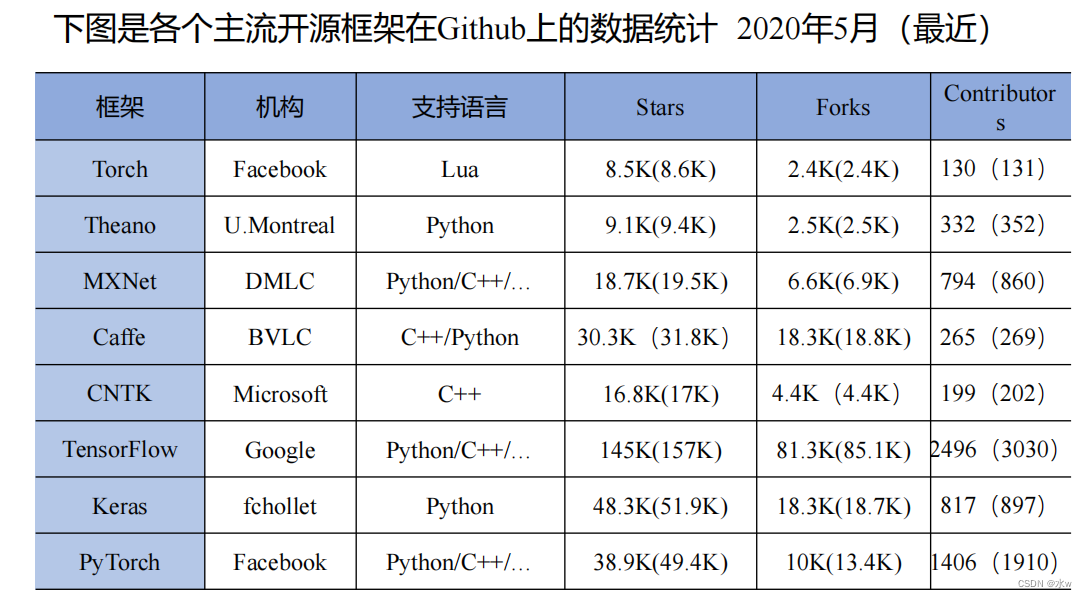
总结:

三、Tensorflow与PyTorch比较分析
通过分析,目前来看TensorFlow和PyTorch框架是业界使用最为广泛的两个深度学习框架,TensorFlow 在工业界拥有完备的解决方案和用户基础,PyTorch 得益于其精简灵活的接口设计,可以快速设计和调试网络模型,在学术界获得好评如潮。
对比分析:
◼
细化特征比较

◼
使用场景
• TensorFlow
:当需要拥有丰富的入门资源、开发大型生产模型、可视化要求较高、大规模分布式模型训练时。
• PyTorch
:如果想要快速上手、对于功能性需求不苛刻、追求良好的开发和调试体验、擅长
Python
化的工具时。
四、PyTorch入门
PyTorch是一个基于 Python 的库,用来提供一个具有灵活性的深度学习开发平台。PyTorch的工作流程非常接近Python的 科学计算库 —— numpy 。PyTorch像Python一样简单,可以顺利地与Python数据科学栈集成,取代了具有特定功能的预定义图形,PyTorch为我们提供了一个框架,以便可以在运行时构建计算图,甚至在运行时更改它们。 PyTorch的其他一些优点还包括: 多gpu支持 , 自定义数据加载器 和 简化的预处理器 。
PyTorch入门-安装
(1)使用pip安装
目前,使用pip安装
PyTorch二进制包
是最简单、最不容易出错,同时也是最适合新手的安装方式。从PyTorch官网选择
操作系统
、
包管理器pip
、
Python版本
及
CUDA版本
,会对应不同的安装命
令,如图所示:

pip install <软件包名称> -i https://pypi.tuna.tsinghua.edu.cn/simple
(2)使用conda安装
conda是Anaconda自带的包管理器。如果使用Anaconda作为Python环境,则除了使用pip安装,
还可以使用conda进行安装。同样,在PyTorch官网中选择
操作系统
、
包管理器conda
、
Python版本
及
CUDA版本
,对应不同的安装命令。如图所示:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ …………
PyTorch入门-Tensor
Tensor,又名张量。可简单地认为它是一个数组,且支持高效的科学计算。它可以是
一个数(标
量)
、
一维数组(向量)
、
二维数组(矩阵)
或
更高维的数组(高阶数据)
。Tensor和numpy的
ndarrays类似,但PyTorch的tensor支持GPU加速。如下定义一个简单的一维矩阵:
torch.FloatTensor([2])
与numpy一样,科学计算库非常重要的一点是能够实现高效的数学功能。如下实现一个简单的加
法操作:
a = torch.FloatTensor([2])
b = torch.FloatTensor([3])
a + bPyTorch入门-自动求导
(1)autograd:
torch.autograd是为了方便用户使用,专门开发的一套
自动求导引擎
,它能够根据
输入
和
前向传播
过程自动构建
计算图
,并执行
反向传播
。 autograd包就是用来自动求导的,可以为张量上的所有操作提供自动求导机制,而torch.Tensor和torch.Function为autograd上的两个核心类,他们相互连接并生成一个有向非循环图。
autograd包为对tensor进行自动求导,为实现对tensor自动求导,需考虑如下事项:
• 在创建torch.Tensor时,如果属性.require_grad为True,它将会追踪对于该张量的所有操作。
• 可以通过用torch.no_grad()包裹代码块来阻止autograd去跟踪那些标记为.requesgrad=True
的张量的历史记录
• 当通过调用.backward()来自动计算所有的梯度,这个张量所有梯度将会自动累加到.grad属性。
• backward()函数接受参数,该参数应和调用backward()函数的Tensor的维度相同,或者是可
broadcast的维度。
• 如果求导的tensor为标量(即一个数字),backward中参数可省略。
(2)计算图:
计算图是一种特殊的有向无环图
,用于记录算子与变量之间的关系。一般用矩形表示算子,椭圆形表示变量。

如图,表达式:z=wx+b,可写成两个表示式:y=wx, 则z=y+b。
• x、w、b为变量,是用户创建的变量,不依赖于其他变量,故又称为叶子节点
• y、z是计算得到的变量,非叶子节点,z为根节点
• mul和add是算子(或操作或函数)由这些变量及算子,就构成一个完整的计算过程(前向传播)。
Pytorch调用backward(),将自动计算各节点的梯度,这是一个反向传播过程, 这个过程如下图所示。
• 在反向传播过程中,autograd当前根节点z反向溯源,利用导数链式法则,计算所有叶子节点的梯度,其梯度值将累加到grad属性中。
• 对非叶子节点的计算操作(或function)记录在grad_fn属性中,叶子节点的grad_fn值为None。
















 7808
7808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











