







感谢知乎大佬:@弈心
本文是基于@弈心大佬(王印)的书籍《网络工程师的python之路》所整理的笔记
1.JSON
JSON诞生于1999年12月,是JavaScript Programming Language(Standard ECMA-262 3rd Edition)的一个子集合,是一种轻量级的数据交换格式。虽然JSON基于JavaScript开发,但它是一种“语言无关”(Language Independent)的文本格式,并且采用C语言家族,如C、C++、C#、Java、Python和Perl等语言的用法习惯,成为一门理想的数据交换语言(Data-Interchange Language)。
1.1JSON基础知识
JSON的数据结构具有易读的特点,它由键值对(Collection)和对象(Object)组成,在结构上非常类似Python的字典(Dictionary),如下是一个典型的JSON数据格式。
{
"intf":"Gigabitethernet0/0",
"status":"up"
}与Python的字典一样,JSON的键值对也由冒号分开,冒号左边的“intf”和“status”即键值对的键(Name),冒号右边的“Gigabitethernet0/0”和“up”即键值对的值(Value),每组键值对之间都用逗号隔开。 JSON与字典不一样的地方如下。
(1)JSON里键的数据类型必须为字符串,而在字典里字符串、常数、浮点数或者元组等都能作为键的数据类型。
(2)JSON里键的字符串内容必须使用双引号括起来,不像字典里既可以用单引号,又可以用双引号来表示字符串。 JSON里键值对的值又分为两种形式,一种形式是简单的值,包括字符串、整数等,比如上面的“Gigabitethernet0/0”和“up”就是一种简单的值。另一种形式被称为对象(Object),对象内容用大括号{}表示,对象中的键值对之间用逗号分开,它们是无序的,举例如下。
{"Vendor":"Ciscio","Model":"2960"}当有多组对象存在时,我们将其称为JSON阵列(JSON Array),阵列以中括号[]表示,阵列中的元素(即各个对象)是有序的(可以把它理解为列表),举例如下。
{
"devices":[
{"Vendor":"Ciscio","Model":"2960"},
{"Vendor":"Ciscio","Model":"3560"},
{"Vendor":"Ciscio","Model":"4500"}
]
}1.2JSON在Python中的使用
Python中已经内置了JSON模块,使用时只需import json即可。
JSON模块主要有两种函数:json.dumps()和json.loads()。前者是JSON的编码器(Encoder),用来将Python中的对象转换成JSON格式的字符串,如下图所示。

由此可以看到,我们用json.dumps()将Python中3种类型的对象:字符串('parry')、字典({"c": 0, "b": 0, "a": 0})、列表([1,2,3])转换成了JSON格式的字符串,并用type()函数进行了验证。
而json.loads()的用法则是将JSON格式的字符串转换成Python的对象,如下图所示。
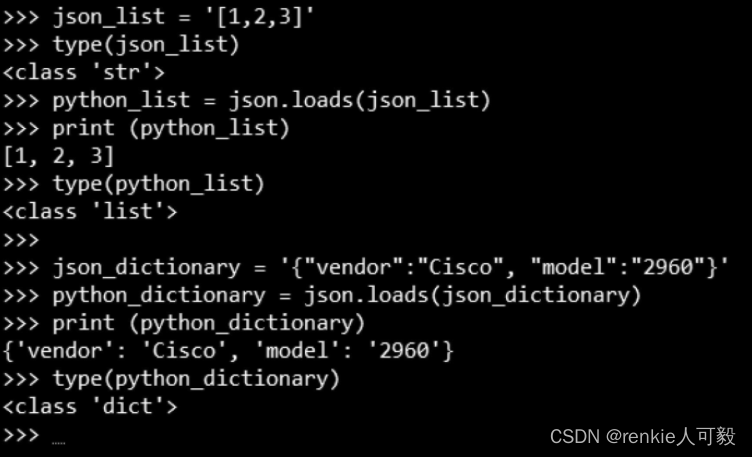
我们将两个JSON格式的字符串:“[1,2,3]”和“{"vendor":"Cisco", "model":"2960"}”,用json.loads()转换成了它们各自对应的Python对象:列表[1,2,3]和字典{"vendor":"Cisco","model":"2960"}。
2.正则表达式的痛点
作为本书的重点内容,我们知道,在Python中可以使用正则表达式来对字符串格式的文本内容做解析(Parse),从而匹配到我们感兴趣的文本内容,但是这么做有一定限制,比如我们需要用正则表达式从如下图所示的一台2960交换机show ip int brief命令的回显内容中找出哪些物理端口是Up的。
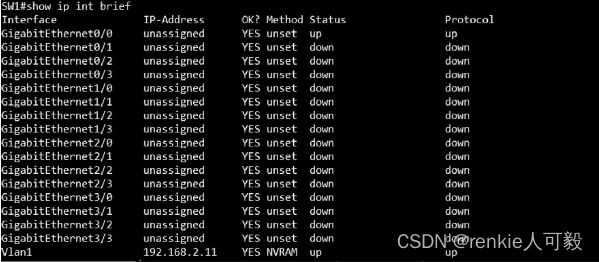
如果用常规思维的正则表达式GigabitEthernet\d\/\d来匹配,则会将除VLAN1外的所有物理端口都匹配上,显然这种做法是错误的,因为当前只有GigabitEthernet0/0这一个物理端口的状态是Up的。大家也许此时想到了另一种方法,那就是在交换机的show ip int brief后面加上| i up提前做好过滤,再用正则表达式GigabitEthernet\d\/\d来匹配。 这种方法确实可以匹配出我们想要的结果,但是如果这时把要求变一变:找出当前交换机下所有Up的端口(注意,现在不再只是找出所有Up的物理端口,虚拟端口也要算进去),并且同时给出它们的端口号及IP地址。 这个要求意味着不仅要用正则表达式匹配上面文本里的GigabitEthernet0/0、Vlan1、unassigned、192.168.2.11这4项内容,还要保证正则表达式没有匹配到其他诸如YES、unset、NVRAM、up等文本内容,为了解决类似这样的正则表达式的痛点问题,我们必须搬出“救兵”——TextFSM了
3.TextFSM和ntc-templates
TextFSM最早是由Google开发的一个Python开源模块,它能使用自定义的变量和规则设计出一个模板(Template),然后用该模板来处理文本内容,将这些无规律的文本内容按照自己打造的模板将它们整合成想要的有序的数据格式。 举个例子,如果有办法把show ip int brief的回显内容转换成JSON格式,将它们以JSON阵列的数据格式列出来,是不是会很方便配合for循环匹配出我们想要的东西呢?比如看到下面这样的JSON阵列。

由上面代码可以看到,JSON阵列格式在Python中实际上是一个数据类型为列表的对象(以 [开头,以]结尾),既然是列表,那我们就能很方便地使用for语句遍历列表中的每个元素(这里所有的元素均为字典),并配合if语句,将端口状态为“up”(“status”键对应的值)的端口号(“intf”键对应的值)和IP地址(“ipaddr”键对应的值)一一打印出来即可。 下面介绍如何在Python中使用TextFSM创建我们需要的模板。
3.1TextFSM的安装
作为Python的第三方模块,TextFSM有两种安装方法。 第一种方法是使用pip安装,如下图所示。
pip3.10 install textfsmpip安装完毕后,进入Python并输入import textfsm,如果没有报错,则说明安装成功。
由上面代码可以看到,JSON阵列格式在Python中实际上是一个数据类型为列表的对象(以 [开头,以]结尾),既然是列表,那我们就能很方便地使用for语句遍历列表中的每个元素(这里所有的元素均为字典),并配合if语句,将端口状态为“up”(“status”键对应的值)的端口号(“intf”键对应的值)和IP地址(“ipaddr”键对应的值)一一打印出来即可(具体的代码将在6.4节中给出)。 下面介绍如何在Python中使用TextFSM创建我们需要的模板。
3.2TextFSM模板的创建和应用
TextFSM的语法本身并不难,但是必须熟练掌握正则表达式。以show vlan命令的回显内容为例,来看如何用TextFSM创建模板,以及如何使用模板将该show vlan命令的回显内容整理成我们想要的数据格式。
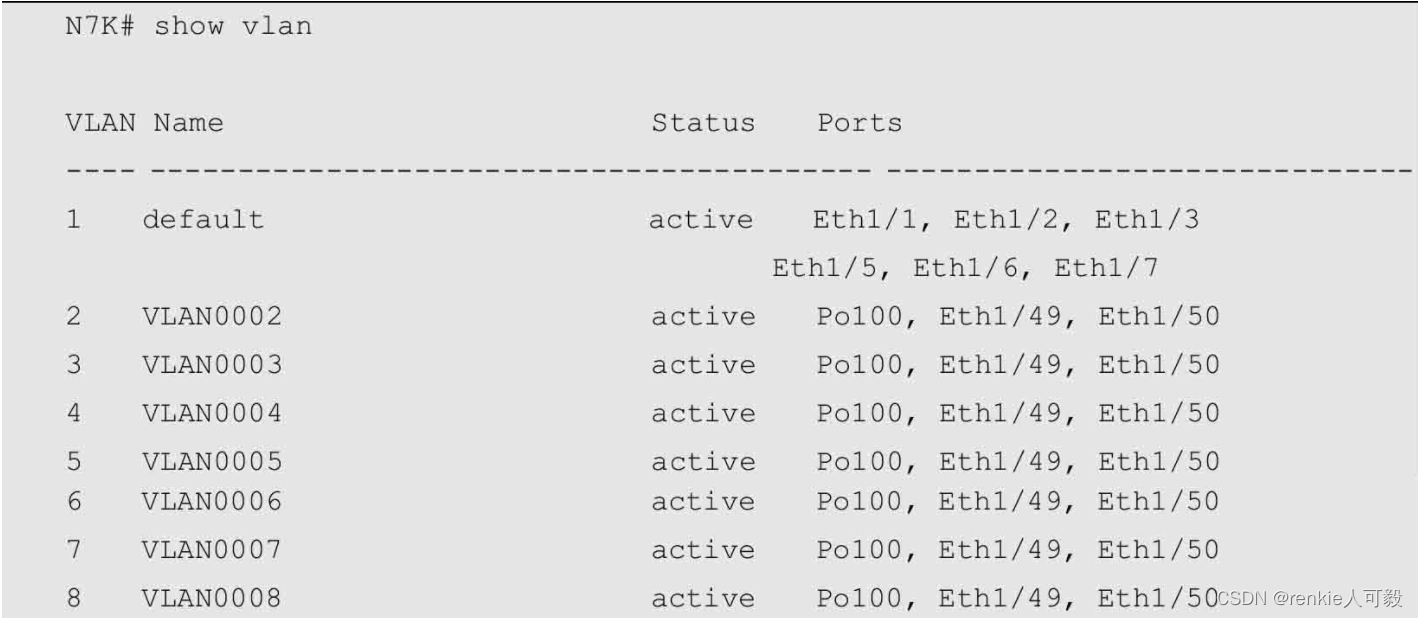
我们创建一个TextFSM模板,模板内容如下。
Value VLAN_ID (\d+)
Value NAME (\w+)
Value STATUS (\w+)
Start
^${VLAN_ID}\s+${NAME}\s+${STATUS}\s+ -> Record(1)在TextFSM中,我们使用Value语句来定义变量,这里定义了3个变量,分别是VLAN_ID、NAME和STATUS。
Value VLAN_ID (\d+)
Value NAME (\w+)
Value STATUS (\w+)(2)每个变量后面都有它自己对应的正则表达式模式(Pattern),这些模式写在括号()中。比如变量VLAN_ID顾名思义是要去匹配VLAN的ID的,所以它后面的正则表达式模式写为(\d+)。在以前讲过,\d这个特殊序列用来匹配数字,后面的+用来做贪婪匹配。同理,变量NAME是用来匹配VLAN的名称的,因为这里VLAN的名称掺杂了字母和数字,比如VLAN0002,所以它的正则表达式模式写为(\w+)。\w这个特殊序列用来匹配字母或数字,后面的+用来做贪婪匹配。同理,变量STATUS(\w+)用来匹配VLAN状态,VLAN状态会有active和inactive之分。
(3)在定义好变量后,我们使用Start语句来定义匹配规则,匹配规则由正则表达式的模式及变量名组成。
Start
^${VLAN_ID}\s+${NAME}\s+${STATUS}\s+ ->Record(4)Start语句后面必须以正则表达式^开头。^是正则表达式中的一种特殊字符,用于匹配输入字符串的开始位置,注意紧随其后的$不是正则表达式里的$,它的作用不是用来匹配输入字符串的结尾位置,而是用来调用我们之前设置好的VLAN_ID并匹配该变量。注意,在TextFSM中调用变量时可以用大括号{},写成${VLAN_ID},也可以不用,写成$VLAN_ID,但是TextFSM官方推荐使用大括号。VLAN_ID对应的正则表达式恰巧是\d+,这样就匹配到了1、2、3、4、5、6、7、8这些VLAN_ID,而后面的\s+$则表示匹配1、2、3、4、5、6、7、8后面的空白字符(\s这个特殊序列用来匹配空白字符)。
(5)同理,我们调用变量NAME,它对应的正则表达式模式为\w+,该特殊序列用来匹配show vlan命令回显内容中的default、VLAN0002、VLAN0003、…、VLAN0008等内容,而后面的\s则用来匹配之后所有的空白字符。
(6)变量{STATUS}也一样,它对应的\w+用来匹配active和inactive这两种VLAN状态(例子中给出的show vlan的回显内容中没有inactive,但是不影响理解)以及后面的空白字符。最后用-> Record来结束TextFSM的匹配规则。
应用
在了解了TextFSM的语法基础后,接下来看怎么在Python中使用TextFSM。首先将上面的TextFSM模板文件以文件名show_vlan.template保存。 然后在相同的文件夹下创建一个名叫textfsm_demo.py的Python脚本。
将下面的代码写入该脚本。
from textfsm import TextFSM
output = '''
show vlan
VLAN Name status Ports
1 default active Eth1/1,Eth1/2,Eth1/3
Eth1/5,Eth1/6,Eth1/7
2 VLAN0002 active Po100,Eth1/49,Eth1/50
3 VLAN0003 active Po100,Eth1/49,Eth1/50
4 VLAN0004 active Po100,Eth1/49,Eth1/50
5 VLAN0005 active Po100,Eth1/49,Eth1/50
6 VLAN0006 active Po100,Eth1/49,Eth1/50
7 VLAN0007 active Po100,Eth1/49,Eth1/50
8 VLAN0008 active Po100,Eth1/49,Eth1/50
'''
f=open('show_vlan.template')
template=TextFSM(f)
print(template.ParseText(output))代码分段讲解如下。
(1)首先我们用from textfsm import TextFSM引入TextFSM模块的TextFSM函数,该函数为TextFSM模块下最核心的类。
from textfsm import TextFSM(2)将show vlan的回显内容以三引号字符串的形式赋值给变量output。
output = '''
show vlan
VLAN Name status Ports
1 default active Eth1/1,Eth1/2,Eth1/3
Eth1/5,Eth1/6,Eth1/7
2 VLAN0002 active Po100,Eth1/49,Eth1/50
3 VLAN0003 active Po100,Eth1/ 49,Eth1/50
4 VLAN0004 active Po100,Eth1/49,Eth1/50
5 VLAN0005 active Po100,Eth1/49,Eth1/50
6 VLAN0006 active Po100,Eth1/49,Eth1/50
7 VLAN0007 active Po100,Eth1/49,Eth1/50
8 VLAN0008 active Po100,Eth1/49,Eth1/50
'''(3)打开之前创建好的模板文件show_vlan.template,调用TextFSM()函数将它赋值给变量template,最后调用template下的ParseText()函数对文本内容进行解析,ParseText()函数中的参数output即show vlan命令的回显内容,最后用print()函数将被模板解析后的回显内容打印出来,看看是什么样的内容。
f=open('show_vlan.template')
template=TextFSM(f)
print(template.ParseText(output))一切就绪后,执行脚本看效果,如下图所示。

由此可以看到,之前无序的纯字符串文本内容被TextFSM模板解析后,已经被有序的嵌套列表替代,方便我们配合for循环做很多事情。
3.3ntc-templates
用TextFSM制作的模板很好用,但是缺点也很明显:每个TextFSM模板都只能对应一条show或者display命令的回显内容,而目前每家知名厂商的网络设备都有上百种showshow或display命令,并且每家厂商的回显内容和格式都完全不同,有些厂商还有多种不同的操作系统,比如思科就有IOS、IOS-XE、IOS-XR、NX-OS、ASA、WLC等多种OS版本,这些版本又有各自特有的show命令,每种操作系统的每条命令都要靠自己手动写一个对应的模板吗?不用担心,已经有前人帮我们写好了模板,这就是ntc-templates。 ntc-templates是由Network To Code团队用TextFSM花费了无数心血开发出来的一套模板集,支持Cisco IOS、Cisco ASA、Cisco NX-OS、Cisco IOS-XR、Arista、Avaya、Brocade、Checkpoint、Fortinet、Dell、Huawei、Palo Alto等绝大多数主流厂商的设备,将在这些设备里输入show和display命令后得到的各式各样的回显文本内容整合成JSON、XML、YAML等格式。举例来说,针对思科的IOS设备,ntc-templates提供了show ip int brief、show cdp neighbor、show access-list等常用的show命令对应的TextFSM模板(还有数百种思科和其他厂商的TextFSM模板可自行去挖掘)。
但是,目前大量的模板还是思科的,华为目前提供了 6个 demo模板。

我们可以通过Netmiko模块来调用TextFSM和ntc-tempalte。















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









